
Ultipa CLI (ultipa_cli) is a cross-platform (Windows/Mac/Linux) command line interface designed for executing GQL and UQL queries against Ultipa graph databases.
Prerequisites
- A command line terminal.
- Linux or MacOS: Bash, Zsh, TCSH
- Windows: PowerShell
- Download Ultipa CLI from here. No installation is required.
Usage Guides
The following steps are demonstrated using PowerShell (Windows).
1. Connect to Ultipa
Open the terminal program and navigate to the folder containing ultipa_cli. Run ultipa_cli and connect to the database:
./ultipa_cli.exe -h <host_addr> -u <username> -p <password>
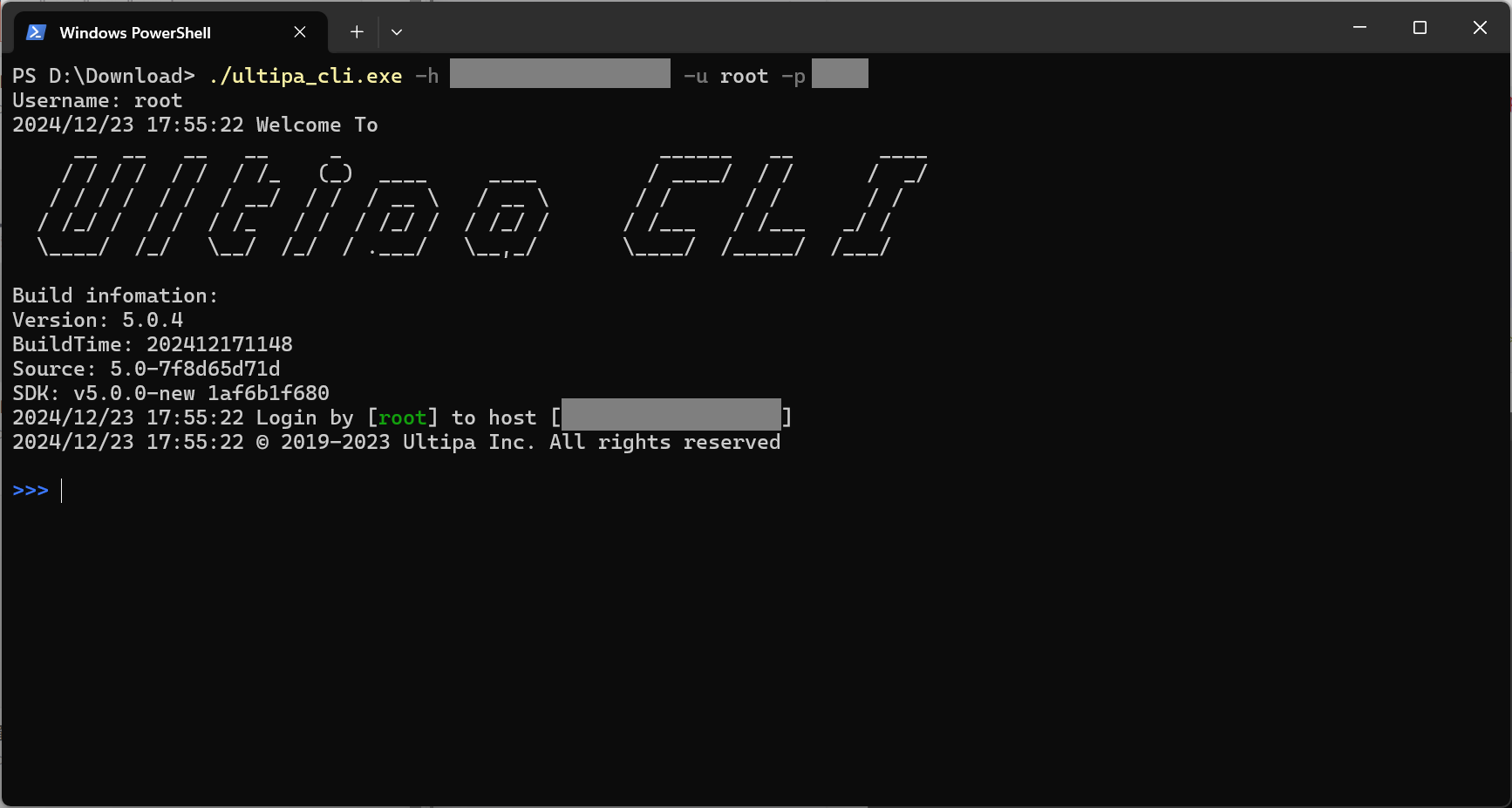
See All Flags to start using ultipa_cli and connect to Ultipa. Once logged in successfully, you will enter an interactive session where you can use various commands (See All Commands) to interact with and operate the database.
2. Specify the Graph
Specify the current graph using the use command. Take the graph named alimama as an example.
use alimama

3. Execute Queries
ultipa_cli has UQL and GQL modes. By default, it is in the UQL mode.
UQL Queries
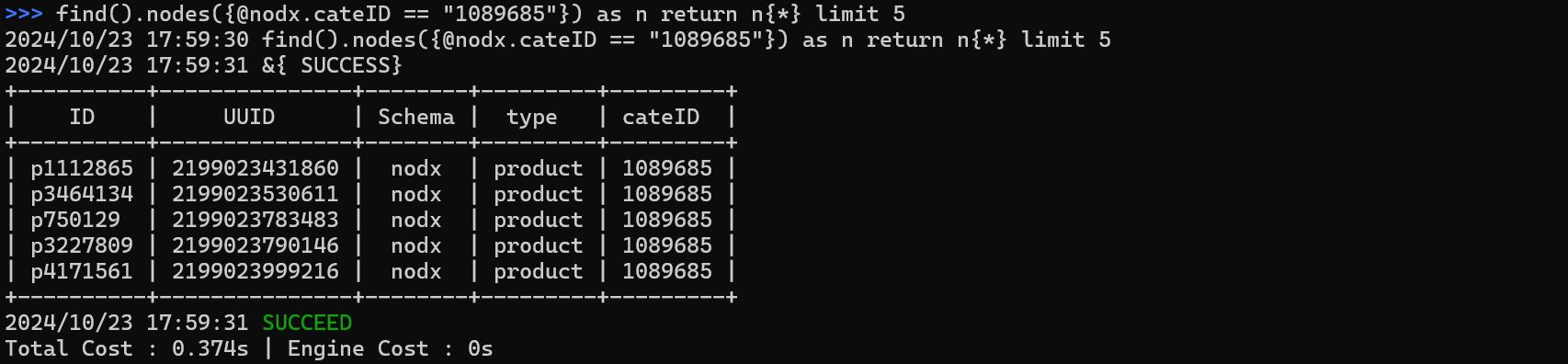
Execute a UQL query:
find().nodes({@nodx.cateID == "1089685"}) as n return n{*} limit 5
Switch Between UQL and GQL
You can switch between the UQL and GQL mode using the uql and gql commands.
gql

GQL Queries
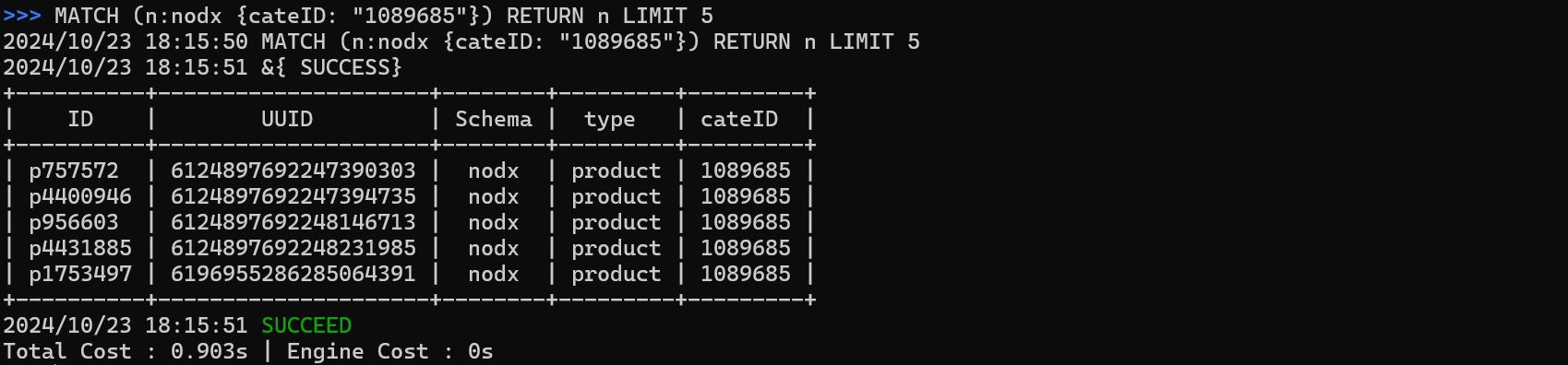
Execute a GQL query:
MATCH (n:nodx {cateID: "1089685"}) RETURN n LIMIT 5
4. Execute Files
You can execute a file either in an interactive session using the run command, or by using the -e/--exec flag to execute it directly. In both way, you need to specify the file path.
About the file:
- The file shoud contain one or multiple UQL or GQL queries. Multiple queries are executed sequentially, with each query ending with a semicolon (;).
- The file can include the
use <graphName>command to specify the current graph. ultipa_cliautomatically detects the query mode base on the file name. If the file name contains "UQL" or "GQL" (case insensitive, with priority given to "UQL"), it will switch to the appropriate mode. If no such keyword is identified, the current or default mode will be used.
Execute a file in an interactive session
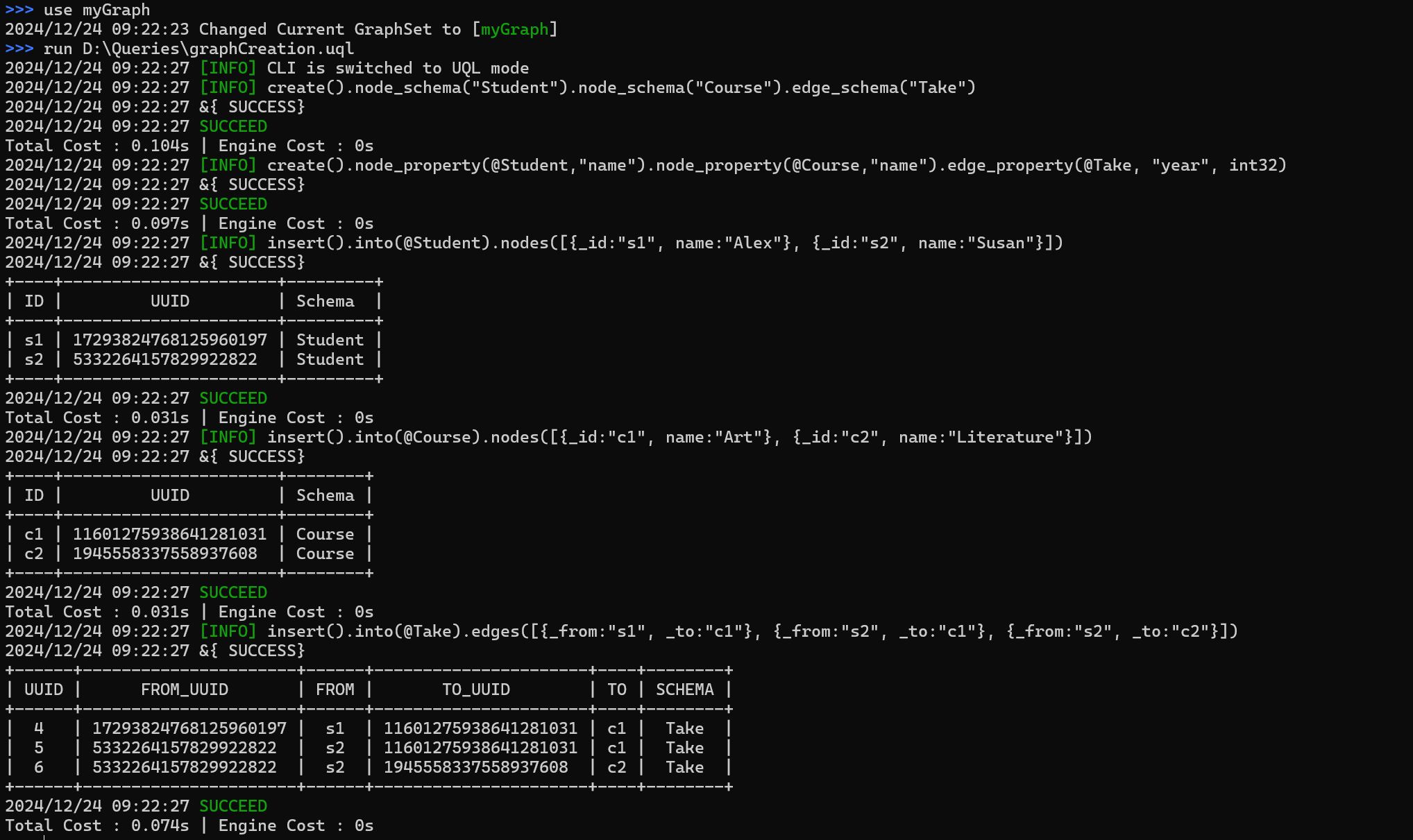
The following file contains UQL queries to create schemas and properties, and insert nodes and edges into the current graph:
create().node_schema("Student").node_schema("Course").edge_schema("Take");
create().node_property(@Student,"name").node_property(@Course,"name").edge_property(@Take, "year", int32);
insert().into(@Student).nodes([{_id:"s1", name:"Alex"}, {_id:"s2", name:"Susan"}]);
insert().into(@Course).nodes([{_id:"c1", name:"Art"}, {_id:"c2", name:"Literature"}]);
insert().into(@Take).edges([{_from:"s1", _to:"c1"}, {_from:"s2", _to:"c1"}, {_from:"s2", _to:"c2"}]);
To execute this file in an interactive session:
run D:\Queries\graphCreation.uql
Execute a file directly
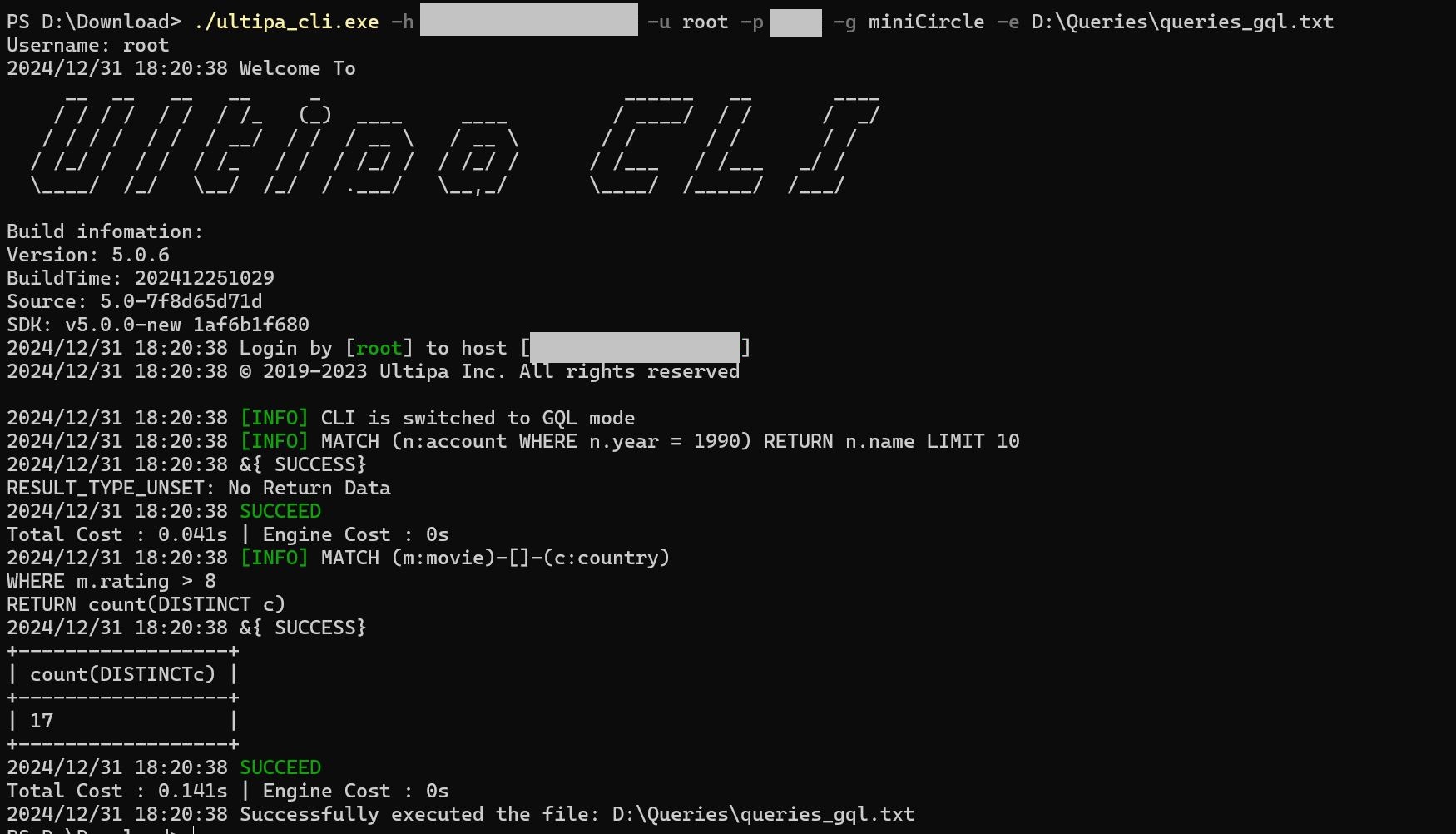
The following file contains two GQL queries:
use miniCircle;
// query 1
MATCH (n:account WHERE n.year = 1990) RETURN n.name LIMIT 10;
// query 2
MATCH (m:movie)-[]-(c:country)
WHERE m.rating > 8
RETURN count(DISTINCT c);
To execute this file immediately:
./ultipa_cli.exe -h <host_addr> -u <username> -p <password> -e D:\Queries\queries_gql.txt
5. Install Algorithms
You can install HDC algorithms using the install algo command in ultipa_cli on one of your database's HDC servers.
The install algo requires the following flags:
Flag |
Parameter | Optional |
|---|---|---|
-a, --algo |
Path of the algorithm .so file. | No |
-i, --info |
Path of the algorithm .yml file. | No |
-hdc, --hdcName |
Name of the HDC server on which the algorithm to be installed. | No |
install algo -a D:\\algo\\libplugin_fastRP.so -i D:\\algo\\fastRP.yml -hdc hdc-server-1

On Windows devices, the
install algorequires\\to specify the file path, and spaces are not allowed in the path.
6. Uninstall Algorithms
You can uninstall HDC algorithms using the uninstall algo command in ultipa_cli from one of your database's HDC servers.
The uninstall algo requires the following flags:
Flag |
Parameter | Optional |
|---|---|---|
-n, --name |
Name of the algorithm (the name used in queries, not the display name). | No |
-hdc, --hdcName |
Name of the HDC server from which the algorithm to be uninstalled. | No |
uninstall algo -n fastRP -hdc hdc-server-1

All Flags
ultipa_cli supports the following flags:
Flag |
Parameter | Optional |
|---|---|---|
-h, --host |
Database host address provided as a URL (excluding https:// or http://) or IP:Port; if connecting to a cluster, provide multiple IP:Port pairs separated by commas. |
No |
-u, --username |
Database username for host authentication. | No |
-p, --password |
Password of the above database user. | No |
-g, --graph |
The graph to set as the current working graph; the default is default. |
Yes |
-qt, --queryType |
The query type: uql (default) or gql. |
Yes |
-crt, --crt |
Local TSL file path for encrypting the transmission. | Yes |
-d, --debug |
A boolean flag, use it to enable the debug mode. | Yes |
-t, --timeout |
Timeout threshold in seconds for requests. | Yes |
-e, --exec |
Executes a file after connecting to Ultipa. | Yes |
--version |
Displays the version of ultipa_cli. |
Yes |
All Commands
ultipa_cli supports the following commands after entering an interactive session:
Command |
Parameter |
Description |
|---|---|---|
use |
Name of a graph. | Specifies the current graph where queries will be executed. |
uql, gql |
/ | Switches the query mode to UQL (default) or GQL. |
| / | UQL or GQL queries. | No specific command is needed; simply input the query and press Enter to execute it. |
run |
File path of the query file. | Executes a file containing queries. |
install algo |
|
Installs an algorithm on an HDC server. |
uninstall algo |
|
Uninstalls an algorithm from an HDC server. |
exit |
/ | Exits the interactive session and disconnectes from Ultipa. |
UQL Execution History
The .ultipa_cli_history file is automatically generated in the same directory as ultipa_cli upon your successful connection to the database, provided the file does not already exist. The file logs all commands executed within ultipa_cli, appending any new commands to the end of the file if it exists. This file helps users keep track of their command history for reference and easy re-execution.