
Overview
The UNCOLLECT statement transforms elements in a list into individual records.
Syntax
UNCOLLECT <listExp> as <alias>
Details
- The
<listExp>is an expression that represents or produces data of thelisttype. - An
<alias>is mandatory to represent the data uncollected.
Example Graph
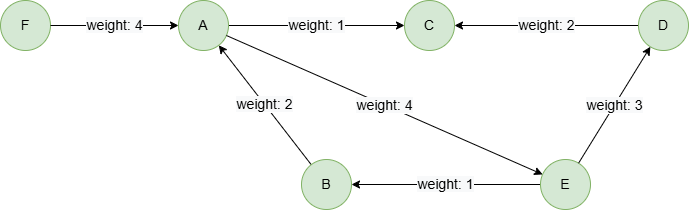
To create the graph, execute each of the following UQL queries sequentially in an empty graphset:
create().edge_property(@default, "weight", int32)
insert().into(@default).nodes([{_id:"A"}, {_id:"B"}, {_id:"C"}, {_id:"D"}, {_id:"E"}, {_id:"F"}])
insert().into(@default).edges([{_from:"A", _to:"C", weight:1}, {_from:"E", _to:"B", weight:1}, {_from:"A", _to:"E", weight:4}, {_from:"D", _to:"C", weight:2}, {_from:"E", _to:"D", weight:3}, {_from:"B", _to:"A", weight:2}, {_from:"F", _to:"A", weight:4}])
Uncollecting a List
uncollect [1,1,2,3,null] as item
return item
Result:
| item |
|---|
| 1 |
| 1 |
| 2 |
| 3 |
null |
uncollect [[1,2], [2,3,5]] as item
return item
Result:
| item |
|---|
| [1,2] |
| [2,3,5] |
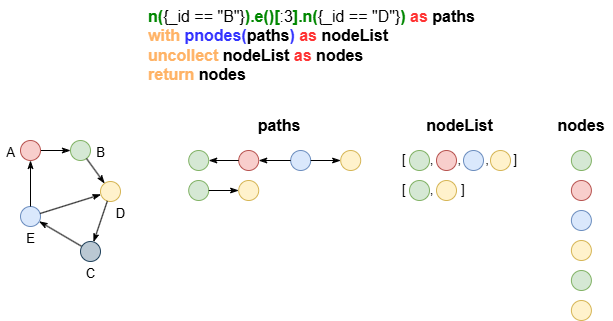
Uncollecting Node/Edge Lists
The pnodes() or pedges() function collects nodes or edges in a path into a list.
n({_id == "A"}).e()[2].n({_id == "D"}) as p
call {
with p
uncollect pedges(p) as edges
return sum(edges.weight) as totalWeights
}
return totalWeights
Result:
| totalWeights |
|---|
| 3 |
| 7 |