
Overview
The k-Nearest Neighbors (kNN) algorithm is a classification method that determines the class of a target node based on the classes of its k nearest (most similar) nodes. Proposed by T.M. Cover and P.E. Hart in 1967, kNN has since become one of the simplest and most widely used classification algorithms:
- T.M. Cover, P.E. Hart, Nearest Neighbor Pattern Classification (1967)
Although the name includes the word neighbor, the kNN algorithm does not explicitly consider the edges between nodes when measuring similarity. Instead, it focuses solely on node properties.
Concepts
Similarity Metric
Ultipa's kNN algorithm calculates the pairwise cosine similarity between the target node and all other nodes in the graph, then selects the k nodes with the highest similarity score.
Vote on Classification
One node property is selected as the class label. After identifying the k nearest nodes to the target node, the label that appears most frequently among the k nodes is assigned to the target node.
If multiple labels share the highest frequency, the label of the node with the highest similarity score is selected.
Example Graph
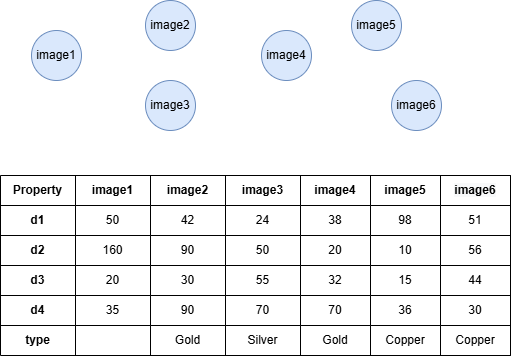
Run the following statements on an empty graph to define its structure and insert data:
ALTER GRAPH CURRENT_GRAPH ADD NODE {
image ({d1 int32, d2 int32, d3 int32, d4 int32, type string})
};
INSERT (:image {_id: "image1", d1: 50, d2: 160, d3: 20, d4: 35}),
(:image {_id: "image2", d1: 42, d2: 90, d3: 30, d4: 90, type: "Gold"}),
(:image {_id: "image3", d1: 24, d2: 50, d3: 55, d4: 70, type: "Silver"}),
(:image {_id: "image4", d1: 38, d2: 20, d3: 32, d4: 70, type: "Gold"}),
(:image {_id: "image5", d1: 98, d2: 10, d3: 15, d4: 36, type: "Copper"}),
(:image {_id: "image6", d1: 51, d2: 56, d3: 44, d4: 30, type: "Copper"});
create().node_schema("image");
create().node_property(@image,"d1",int32).node_property(@image,"d2",int32).node_property(@image,"d3",int32).node_property(@image,"d4",int32).node_property(@image,"type",string);
insert().into(@image).nodes([{_id:"image1", d1:50, d2:160, d3:20, d4:35}, {_id:"image2", d1:42, d2:90, d3:30, d4:90, type:"Gold"}, {_id:"image3", d1:24, d2:50, d3:55, d4:70, type:"Silver"}, {_id:"image4", d1:38, d2:20, d3:32, d4:70, type:"Gold"}, {_id:"image5", d1:98, d2:10, d3:15, d4:36, type:"Copper"}, {_id:"image6", d1:51, d2:56, d3:44, d4:30, type:"Copper"}]);
Creating HDC Graph
To load the entire graph to the HDC server hdc-server-1 as my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}
hdc.graph.create("my_hdc_graph", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}).to("hdc-server-1")
Parameters
Algorithm name: knn
Name |
Type |
Spec |
Default |
Optional |
Description |
|---|---|---|---|---|---|
node_id |
_uuid |
/ | / | No | Specifies the target node by its _uuid. |
node_schema_property |
[]"<@schema.?><property>" |
/ | / | No | Numeric node properties used to compute the cosine similarity; at least two properties are required. The schema must be the same as the target node. |
top_k |
Integer | >0 | / | No | The number of the nearest nodes to select. |
target_schema_property |
"<@schema.?><property>" |
/ | / | No | Numeric or string node property used as the class label. The schema must be the same as the target node. |
return_id_uuid |
String | uuid, id, both |
uuid |
Yes | Includes _uuid, _id, or both to represent nodes in the results. |
File Writeback
CALL algo.knn.write("my_hdc_graph", {
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "@image.type"
}, {
file: {
filename: "knn"
}
})
algo(knn).params({
projection: "my_hdc_graph",
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "@image.type"
}).write({
file: {
filename: "knn"
}
})
Result:
Gold:2
top k(_id):
image2,0.85516
image6,0.841922
image3,0.705072
image4,0.538975
The first line in the file represents the majority label and its count among the k nearest nodes. Starting from the third line, it shows the top k nodes along with their similarity scores to the target node.
Stats Writeback
CALL algo.knn.write("my_hdc_graph", {
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "@image.type"
}, {
stats: {}
})
algo(knn).params({
projection: "my_hdc_graph",
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "@image.type"
}).write({
stats: {}
})
Result:
| attribute_value | count |
|---|---|
| Gold | 2 |
Full Return
CALL algo.knn.run("my_hdc_graph", {
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "@image.type"
}) YIELD r
RETURN r
exec{
algo(knn).params({
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "@image.type"
}) as r
return r
} on my_hdc_graph
Result:
| _ids | similarity |
|---|---|
| image2 | 0.85516 |
| image6 | 0.841922 |
| image3 | 0.705072 |
| image4 | 0.538975 |
Stream Return
CALL algo.knn.stream("my_hdc_graph", {
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "type"
}) YIELD r
RETURN r
exec{
algo(knn).params({
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "type"
}).stream() as r
return r
} on my_hdc_graph
Result:
| _ids | similarity |
|---|---|
| image2 | 0.85516 |
| image6 | 0.841922 |
| image3 | 0.705072 |
| image4 | 0.538975 |
Stats Return
CALL algo.knn.stats("my_hdc_graph", {
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "@image.type"
}) YIELD s
RETURN s
exec{
algo(knn).params({
return_id_uuid: "id",
// Assigns image1 as the target node
node_id: 15420327323139833861,
node_schema_property: ["d1", "d2", "d3", "d4"],
top_k: 4,
target_schema_property: "@image.type"
}).stats() as s
return s
} on my_hdc_graph
Result:
| attribute_value | count |
|---|---|
| Gold | 2 |