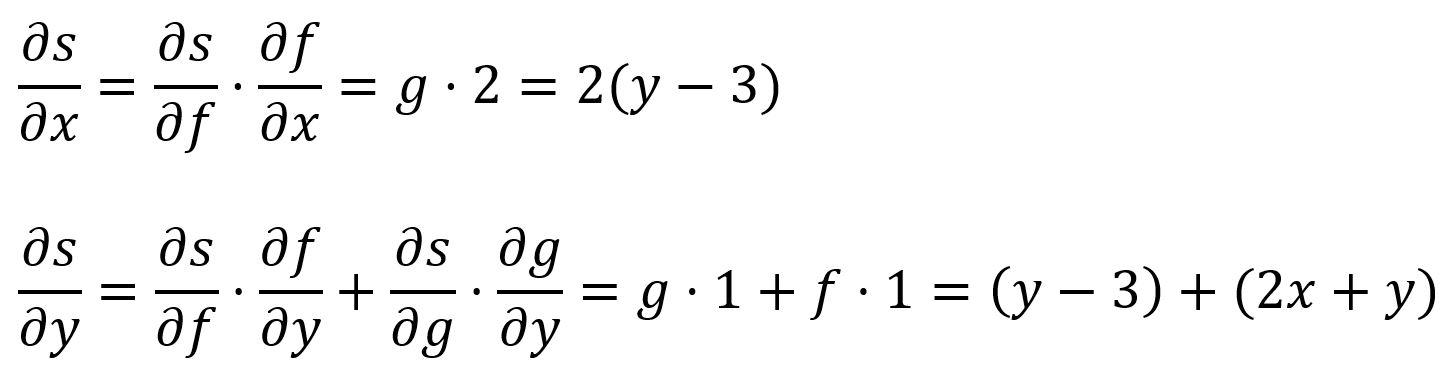Gradient descent is a fundamental optimization algorithm widely used in graph embedding models. Its primary purpose is to iteratively update model parameters in order to minimize a predefined loss/cost function.
To handle the computational challenges of large-scale graph embedding, several variants of gradient descent have been developed. Two commonly used ones are Stochastic Gradient Descent (SGD) and Mini-Batch Gradient Descent (MBGD). These variations update model parameters using gradients computed from either a single data point or a small subset of data during each iteration.
Basic Form
Consider a real-life scenario: standing on a mountain and aiming to descend as quickly as possible. While there may be an optimal path, identifying if in advance is difficult. Instead, a step-by-step approach is used—at each position, you assess the steepest downward direction and take a step accordingly. At each iteration, the algorithm calculates the direction that minimizes the loss most rapidly (the gradient) and updates the parameters accordingly. The process continues until the minimum (the base of the mountain) is reached.
Building on this concept, gradient descent serves as the technique to find the minimum of a function by moving in the direction of the negative gradient. Conversely, if the goal is to find a maximum, the algorithm follows the positive gradient direction, a technique known as gradient ascent.
along the gradient's descent. Conversely, if the aim is to locate the maximum value while ascending along the gradient's direction, the approach becomes gradient ascent.
Given a function , the basic form of gradient descent is:
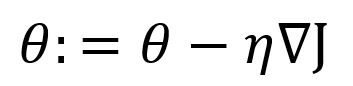
where is the gradient of the function at the position of , is the learning rate. Since gradient is the steepest ascent direction, a minus symbol is used before to get the steepest descent.
The learning rate determines the step size taken in the direction of the gradient during optimization. In the example above, the learning rate corresponds to the distance covered in each step during the descent.
The learning rate is typically kept constant throughout the training process, where the rate is adjusted over time—often decreased gradually or according to a predefined schedule. Such adjustments are designed to improve convergence stability and optimization efficiency.
Example: Single-Variable Function
For function , its gradient (in this case, same as the derivative) is .
If we start at position , and set , the next movements following gradient descent would be:
- ...
- ...
As the number of steps increases, the process gradually converges toward , ultimately reaching the minimum of the function.
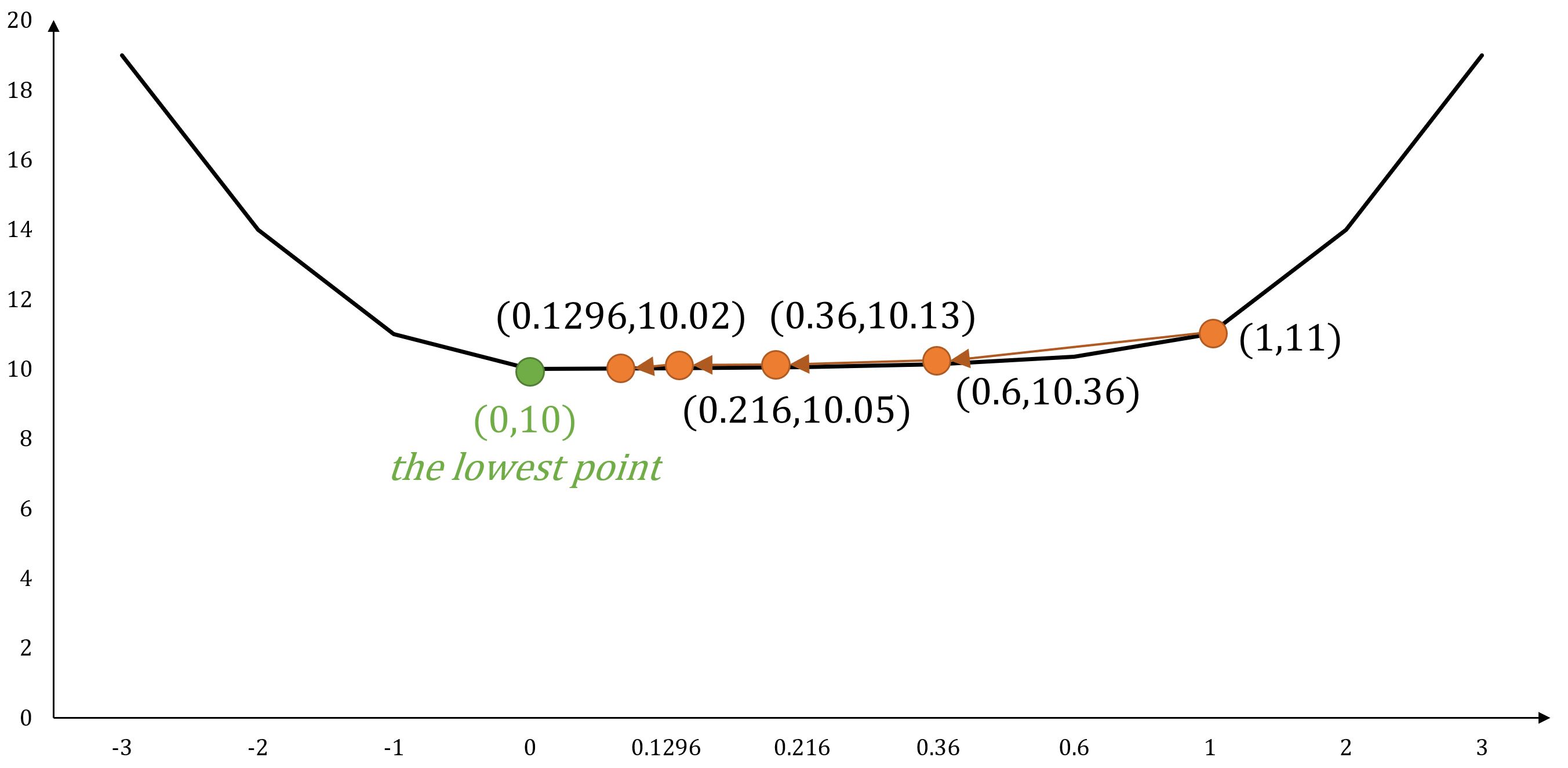
Example: Multi-Variable Function
For function , its gradient is .
If starts at position , and set , the next movements following gradient descent would be:
- ...
- ...
As the number of steps increases, the process gradually converges toward , ultimately reaching the minimum of the function.
Application in Graph Embeddings
In the process of training a neural network model for graph embeddings, a loss or cost function, typically denoted as , is used to assess the discrepancy between the model's output and the expected outcomes. To minimize this loss, gradient descent is used. This iterative optimization technique updates the model's parameters in the opposite direction of the gradient . This process continues until the model converges to a minimum, thereby optimizing performance.
To balance computational efficiency and model accuracy, several variants of gradient descent are commonly used in practice, including:
- Stochastic Gradient Descent (SGD)
- Mini-Batch Gradient Descent (MBGD)
Example
Consider a scenario where we are training a neural network model using a set of samples. Each sample consists of an input value and its corresponding expected output. Let's use and () denote the input and expected output of the -th sample.
The hypothesis of the model is defined as:
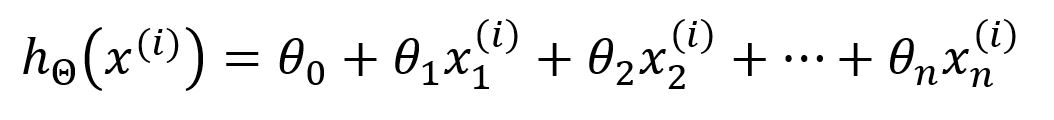
Here, represents the model's parameters ~ , and is the -th input vector, consisting of features. The model computes the output using a function , which performs a weighted combination of the input features.
The objective of model training is to identify the optimal values of that produce outputs as close as possible to the expected values. At the beginning of training, is initialized with random values.
During each iteration of model training, after computing the outputs for all samples, the mean squared error (MSE) is used as the loss/cost function . It measures the average squared difference between the predicted output and its corresponding expected value:
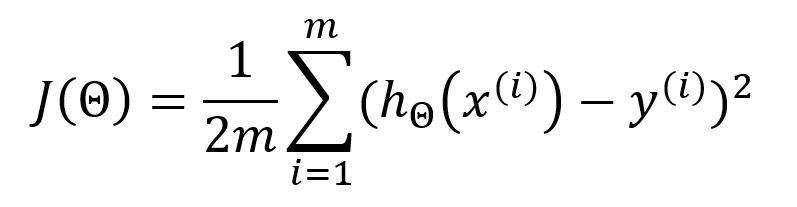
In the standard MSE formula, the denominator is usually . However, is often used instead to offset the squared term when taking the derivative. This leads to the elimination of the constant coefficient during gradient calculation, simplifying subsequent computations without affecting the final result.
Subsequently, gradient descent is used to update the parameters . The partial derivative of the loss function with respect to is calculated as follows:
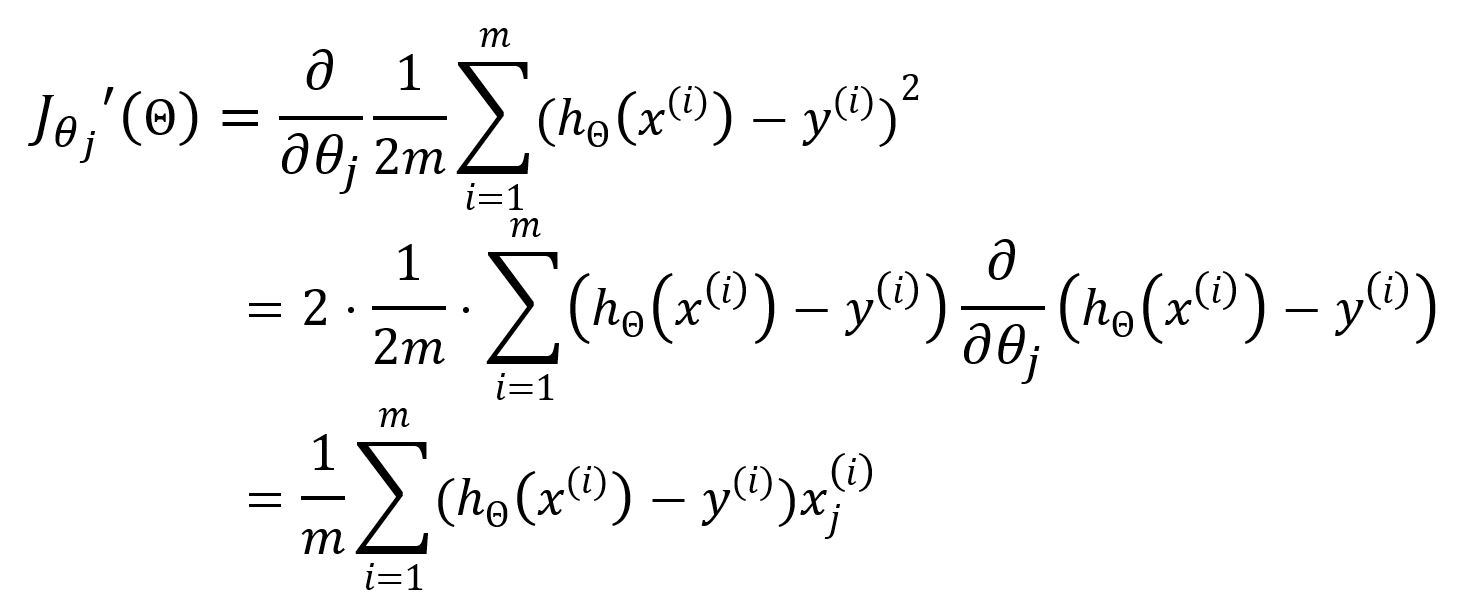
Hence, update as:
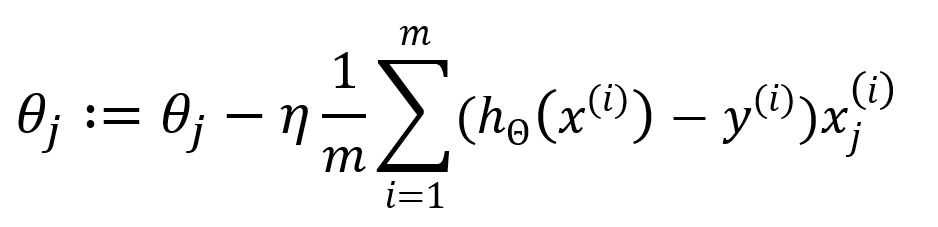
The summation from to indicates that all samples are used in each iteration to update the parameters. This approach is known as Batch Gradient Descent (BGD), the original and most straightforward form of the gradient descent algorithm. In BGD, the entire sample dataset is used to compute the gradient of the cost function during each iteration.
While BGD offers precise convergence to the minimum of the cost function, it can be computationally intensive for large datasets. To improve efficiency and convergence speed, SGD and MBGD were introduced. These variants use subsets of the data in each iteration, significantly accelerating the optimization process while still aiming to find the optimal parameters.
Stochastic Gradient Descent
Stochastic gradient descent (SGD) only selects one sample in random to calculate the gradient for each iteration.
When employing SGD, the above loss function should be expressed as:
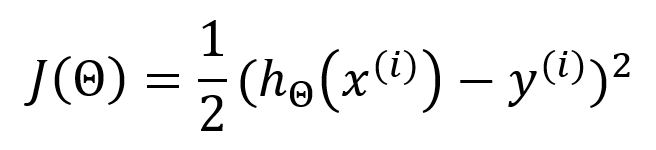
The partial derivative with respect to is:
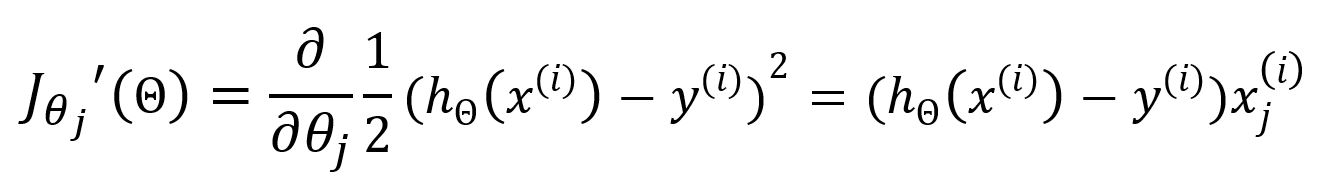
Update as:
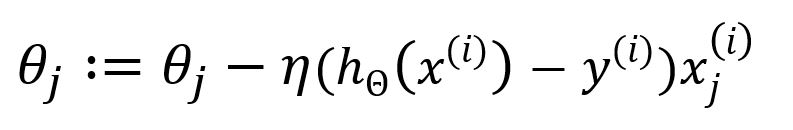
SGD reduces computational complexity by using only one sample per iteration, eliminating the need for summation and averaging. This leads to faster computation but may sacrifice some accuracy in the gradient estimation.
Mini-Batch Gradient Descent
BGD and SGD both represent two extremes: BGD uses all samples, while SGD uses only one. Mini-batch Gradient Descent (MBGD) strikes a balance by randomly selecting a subset of samples for computation.
Mathematical Basics
Derivative
The derivative of a single-variable function is often denoted as or , it represents how changes with respect to a slight change in at a given point.
Graphically, corresponds to the slope of the tangent line to the function's curve. The derivative at point is:
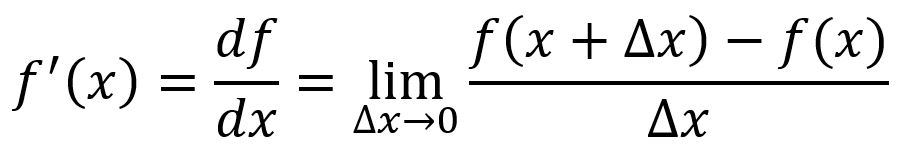
For example, , at point :
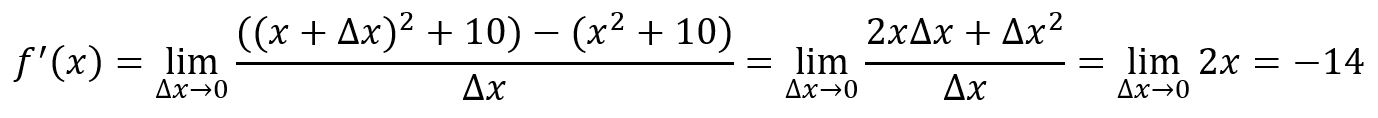
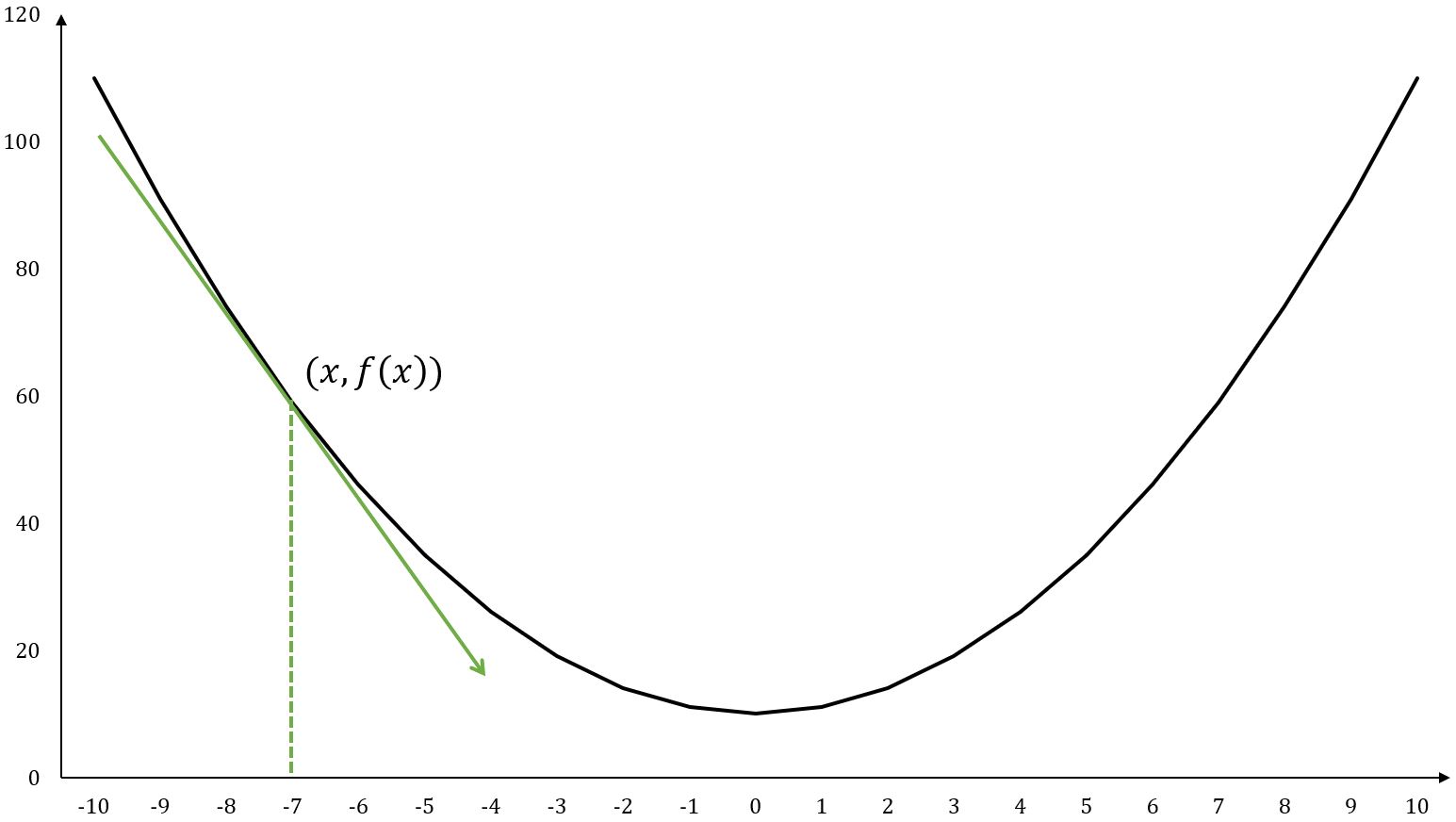
A tangent line is a straight line that touches a function's curve at exactly one point and has the same slope (direction) as the curve at that point.
Partial Derivative
The partial derivative of a multiple-variable function measures how the function changes as one specific variable changes, while all other variables are held constant. For a function , its partial derivative with respect to at a particular point is denoted as or :
For example, , at point , :
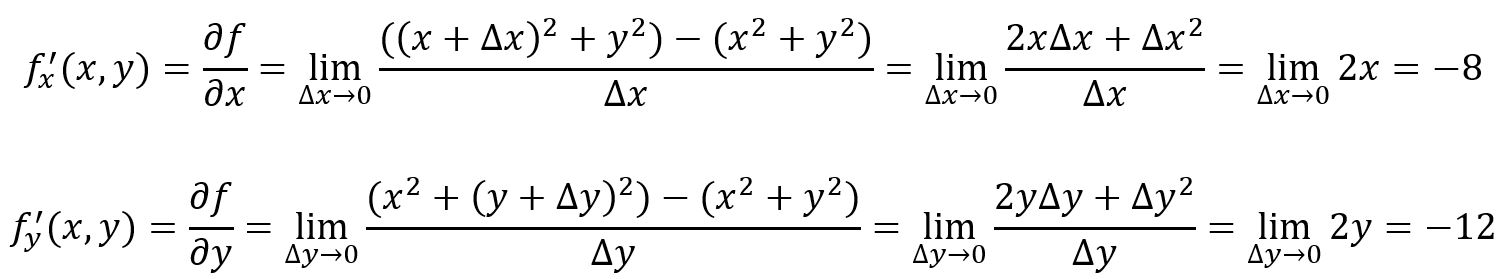
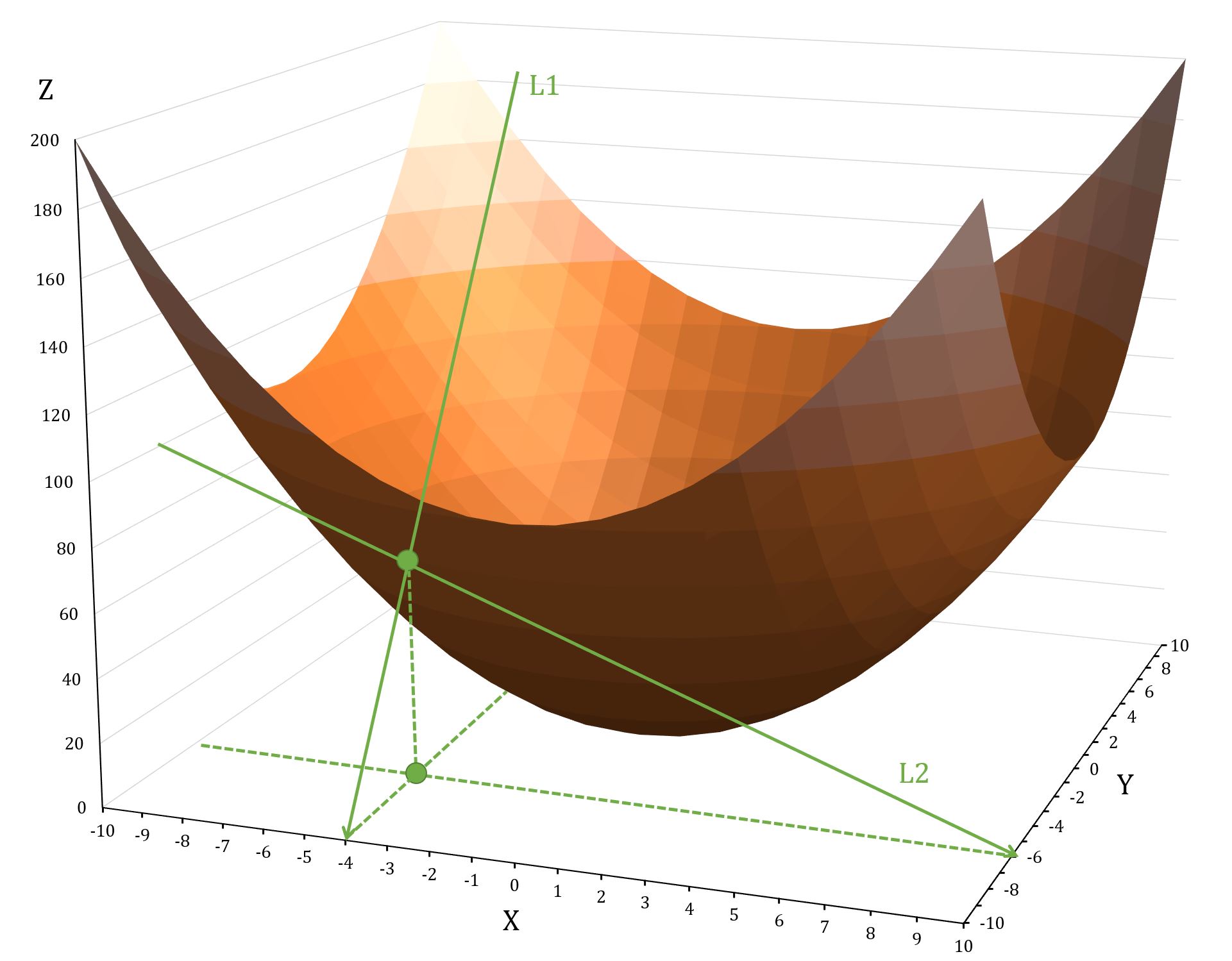
shows how the function changes as you move along the Y-axis, while keeping constant; shows how the function changes as you move along the X-axis, while keeping constant.
Directional Derivative
The partial derivative of a function describes how its output changes when moving slightly along one of the coordinate axes. However, when movement occurs in a direction that is not parallel to any axis, the concept of the directional derivative becomes crucial.
The directional derivative is mathematically expressed as the dot product of the vector composed of all partial derivatives of the function with the unit vector which indicates the direction of the change:
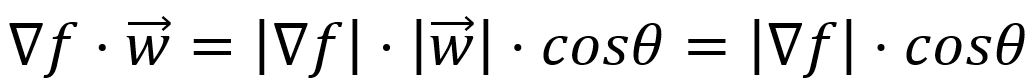
where , is the angle between the two vectors, and
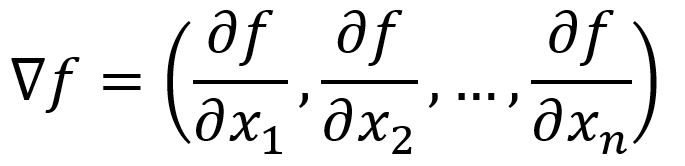
Gradient
The gradient shows the direction in which a function increases the fastest. This is the same as finding the maximum directional derivative. This occurs when angle between the vectors and is , as , implying that aligns with the direction of . is thus called the gradient of a function.
Naturally, the negative gradient points in the direction of the steepest descent.
Chain Rule
The chain rule describes how to calculate the derivative of a composite function. In the simpliest form, the derivative of a composite function can be calculated by multiplying the derivative of with respect to by the derivative of with respect to :
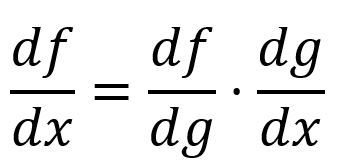
For example, is composed of and :
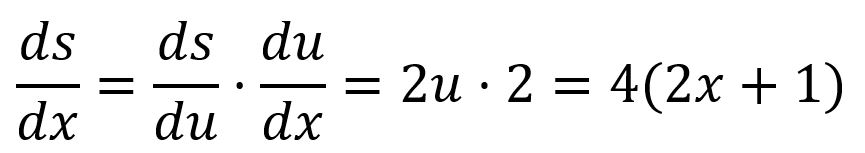
In a multi-variable composite function, the partial derivatives are obtained by applying the chain rule to each variable.
For example, is composed of and and :