
Overview
The CALL statement is used to invoke an inline procedure or a named procedure.
Calling Inline Procedures
An inline procedure is a user-defined procedure embedded within a query, commonly used to execute subqueries or perform data modifications. It enables complex logic such as looping and enhances efficiency by managing resources more effectively—especially when working with large graphs—thereby reducing memory overhead.
<call inline procedure statement> ::=
[ "OPTIONAL" ] "CALL" [ "(" [ <variable reference list> ] ")" ] "{"
<statement block>
"}"
<variable reference list> ::=
<variable reference> [ { "," <variable reference> }... ]
Details
- You can import variables from earlier parts of the query into
CALL. If omitted, all current variables are implicitly imported. - Each imported record is processed independently by the
<statement block>inside theCALL. - When used for subqueries, the
<statement block>must end with aRETURNstatement to output variables to the outer query:- Each returned variable becomes a new column in the intermediate result table.
- If a subquery yields no records, the associated imported record is discarded. The
OPTIONALkeyword can be used to handle this case - producing anullvalue instead of discarding the record. - If multiple records are returned, the imported row is duplicated accordingly.
- For data modification procedures, a
RETURNstatement is not required. In such cases, the number of records in the intermediate result table remains the same after theCALL.
Example Graph
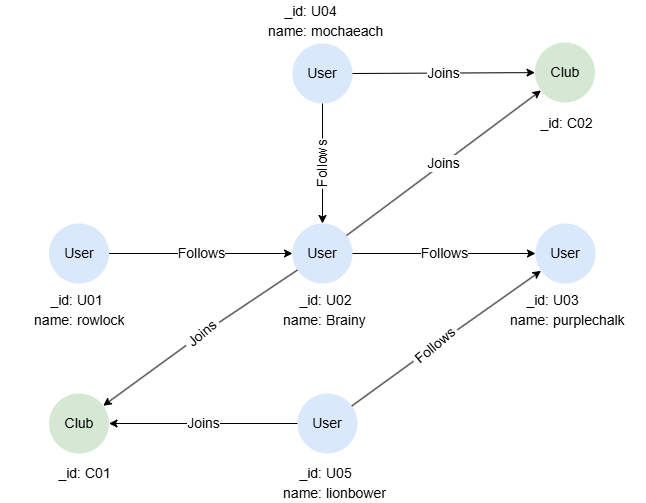
CREATE GRAPH myGraph {
NODE User ({name string}),
NODE Club (),
EDGE Follows ()-[]->(),
EDGE Joins ()-[{rates uint32}]->()
} PARTITION BY HASH(Crc32) SHARDS [1]
INSERT (rowlock:User {_id:'U01', name:'rowlock'}),
(brainy:User {_id:'U02', name:'Brainy'}),
(purplechalk:User {_id:'U03', name:'purplechalk'}),
(mochaeach:User {_id:'U04', name:'mochaeach'}),
(lionbower:User {_id:'U05', name:'lionbower'}),
(c01:Club {_id:'C01'}),
(c02:Club {_id:'C02'}),
(rowlock)-[:Follows]->(brainy),
(mochaeach)-[:Follows]->(brainy),
(brainy)-[:Follows]->(purplechalk),
(lionbower)-[:Follows]->(purplechalk),
(brainy)-[:Joins]->(c01),
(lionbower)-[:Joins]->(c01),
(brainy)-[:Joins]->(c02),
(mochaeach)-[:Joins]->(c02)
Subqueries
To find members of each club:
MATCH (c:Club)
CALL {
MATCH (c)<-[:Joins]-(u:User)
RETURN collect_list(u.name) AS members
}
RETURN c._id, members
Result:
| c._id | members |
|---|---|
| C01 | ["Brainy","lionbower"] |
| C02 | ["Brainy","mochaeach"] |
OPTIONAL CALL
To retrieve the followers of each member in club C01, ensure that members with no followers are still included in the results:
MATCH (c)<-[:Joins]-(u:User) WHERE c._id = "C01"
OPTIONAL CALL (u) {
MATCH (u)<-(follower:User)
RETURN collect_list(follower.name) AS followers
}
RETURN u.name, followers
Result:
| u.name | followers |
|---|---|
| Brainy | ["rowlock","mochaeach"] |
| lionbower | null |
Execution Order of Subqueries
The order in which the subquery executed is not determined. If a specific execution order is desired, ORDER BY should be used to sort the records before CALL to enforce that sequence.
This query counts the number of followers for each user. The execution order of the subqueries is determined by the ascending order of the users' name:
MATCH (u:User)
ORDER BY u.name
CALL {
MATCH (u)<-[:Follows]-(follower)
RETURN COUNT(follower) AS followersNo
}
RETURN u.name, followersNo
Result:
| u.name | followersNo |
|---|---|
| Brainy | 2 |
| lionbower | 0 |
| mochaeach | 0 |
| purplechalk | 2 |
| rowlock | 0 |
Data Modifications
To set values for the property rates of Joins edges:
FOR score IN [1,2,3,4]
CALL {
MATCH ()-[e:Joins WHERE e.rates IS NULL]-() LIMIT 1
SET e.rates = score
RETURN e
}
RETURN e
Result: e
_uuid |
_from |
_to |
_from_uuid |
_to_uuid |
schema |
values |
|---|---|---|---|---|---|---|
| Sys-gen | U04 | C02 | UUID of U04 | UUID of C02 | Joins | {rates: 1} |
| Sys-gen | U02 | C01 | UUID of U02 | UUID of C01 | Joins | {rates: 2} |
| Sys-gen | U02 | C02 | UUID of U02 | UUID of C02 | Joins | {rates: 3} |
| Sys-gen | U05 | C01 | UUID of U05 | UUID of C01 | Joins | {rates: 4} |
Calling Named Procedures
A named procedure refers to a predefined procedure, such as an algorithm, that is registered in the system and can be invoked by its name using the CALL statement.
<call named procedure statement> ::=
"CALL" <procedure reference> [ <yield clause> ]
<yield clause> ::=
"YIELD" <yield item> [ { "," <yield item> }... ]
<yield item> ::=
<column name> [ "AS" <binding variable> ]
Details
- The
YIELDclause can be used to output variables to the outer query.
Running an Algorithm
The following query executes the Degree Centrality algorithm. Note that the algorithm is run on the HDC graph my_hdc_graph derived from the current graph.
CALL algo.degree.run("my_hdc_graph", {
direction: "in",
order: "desc"
}) YIELD r
RETURN r
To learn more about available algorithms, refer to the Graph Analytics & Algorithms documentation.