
Overview
The SybilRank algorithm ranks the trust of nodes by early-terminated random walks in the network, typically Online Social Network (OSN). The surge in popularity of OSNs has accompanied by the a rise in Sybil attacks, in which a malicious attacker creates multiple fake accounts (Sybils) to send spam, distribute malware, manipulate votes, inflate view counts for niche content, and so on.
SybilRank was proposed by Qiang Cao et al. in 2012, it is computationally efficient and can scale to large graphs.
- Q. Cao, M. Sirivianos, X. Yang, T. Pregueiro, Aiding the Detection of Fake Accounts in Large Scale Social Online Services (2012)
Concepts
Threat Model and Trust Seeds
SybilRank models an OSN as an undirected graph, where each node represents a user in the network, and each edge represents a mutual social relationship.
In the threat model of SybilRank, all nodes are divided into two disjoint sets: non-Sybils H, and Sybils S. Denote the non-Sybil region GH as the subgraph induced by the set H, which includes all non-Sybils and edges among them. Similarly, the Sybil region GS is the subgraph induced by S. GH and GS are connected by attack edges between Sybils and non-Sybils.
Some nodes identified as non-Sybils are designated as trust seeds for the operation of SybilRank. Seeding trust on multiple nodes makes SybilRank robust to seed selection errors, as incorrectly designating a node that is Sybil or close to Sybils as a seed causes only a small fraction of the total trust to be initialized and propagated in the Sybil region.
Below is an example of the threat model with trust seeds:
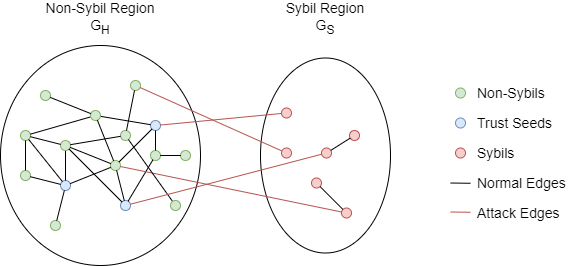
An important assumption of SybilRank is that the number of attack edges is limited. Since SybilRank is designed for large scale attacks, where fake accounts are crafted and maintained at a low cost, and are thus unable to befriend many real users. It results in a sparse cut between GH and GS.
Early-Terminated Random Walk
In an undirected graph, if a random walk's transition probability to a neighbor node is uniformly distributed, when the number of steps is sufficient, the probability of landing at each node would converge to be proportional to its degree. The number of steps that a random walk needs to reach the stationary distribution is called the graph's mixing time.
SybilRank relies on the observation that an early-terminated random walk starting from a non-Sybil node (trust seed) has higher landing probability to land at a non-Sybil node than a Sybil node, as the walk is unlikely to traverse one of the relatively few attack edges. That is to say, there is a significant difference between the mixing time of the non-Sybil region GH and the entire graph.
SybilRank refers to the landing probability of each node as the node’s trust. SybilRank ranks nodes according to their trust scores; nodes with low trust scores are ranked higher, indicating they are potential Sybil (fake) users.
Trust Propagation via Power Iteration
SybilRank uses the technique of power iteration to efficiently calculate the landing probability of random walks in large graphs. Power iteration involves successive matrix multiplications where each element of the matrix represents the random walk transition probability from one node to a neighbor node. Each iteration computes the landing probability distribution over all nodes as the random walk proceeds by one step.
In an undirected graph G = (V, E), initially a total trust TG is evenly distributed among all trust seeds. During each power iteration, a node first evenly distributes its trust to its neighbors; it then collects trust distributed by its neighbors and updates its own trust accordingly. The trust of node v in the i-th iteration is:
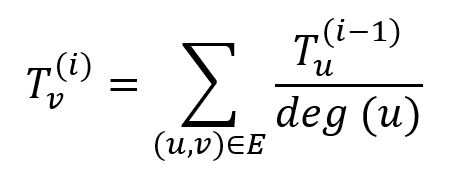
where node u belongs to the neighbor set of node v, deg(u) is the degree of node u. The total amount of trust TG remains unchanged all the time.
With sufficient power iterations, the trust of all nodes would converge to the stationary distribution:
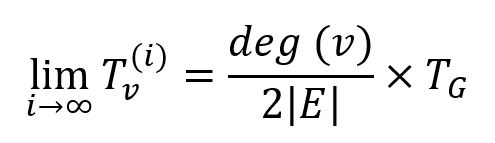
However, SybilRank terminates the power iteration after a fixed number of steps, without waiting for full convergence, and it is suggested to be set as log2(|V|). This number of iterations is sufficient to reach an approximately stationary distribution of trust over the fast-mixing non-Sybil region GH, but limits the trust escaping to the Sybil region GS, thus non-Sybils will be ranked higher than Sybils.
In practice, the mixing time of GH is affected by many factors, so
log2(|V|)is only a reference, but it must be less than the mixing time of the whole graph.
Considerations
- Each self-loop adds two degrees to its subject node.
- The SybilRank algorithm ignores the direction of edges but calculates them as undirected edges.
- SybilRank’s computational cost is O(n log n). This is because each power iteration costs O(n), and it iterates O(log n) times. It is not related with the number of trust seeds.
Example Graph
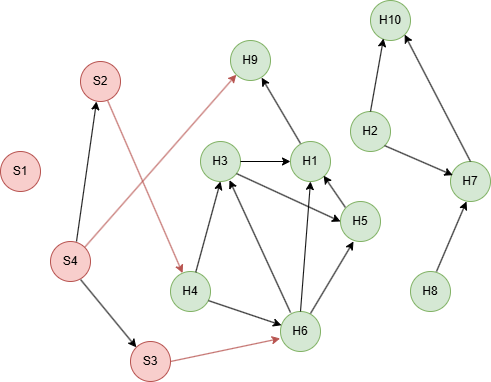
Run the following statements on an empty graph to define its structure and insert data:
ALTER GRAPH CURRENT_GRAPH ADD NODE {
user ()
};
ALTER GRAPH CURRENT_GRAPH ADD EDGE {
link ()-[]->()
};
INSERT (H1:user {_id: "H1"}),
(H2:user {_id: "H2"}),
(H3:user {_id: "H3"}),
(H4:user {_id: "H4"}),
(H5:user {_id: "H5"}),
(H6:user {_id: "H6"}),
(H7:user {_id: "H7"}),
(H8:user {_id: "H8"}),
(H9:user {_id: "H9"}),
(H10:user {_id: "H10"}),
(S1:user {_id: "S1"}),
(S2:user {_id: "S2"}),
(S3:user {_id: "S3"}),
(S4:user {_id: "S4"}),
(S2)-[:link]->(H4),
(S3)-[:link]->(H6),
(S4)-[:link]->(S2),
(S4)-[:link]->(S3),
(S4)-[:link]->(H9),
(H1)-[:link]->(H9),
(H2)-[:link]->(H7),
(H2)-[:link]->(H10),
(H3)-[:link]->(H1),
(H3)-[:link]->(H5),
(H4)-[:link]->(H3),
(H4)-[:link]->(H6),
(H5)-[:link]->(H1),
(H6)-[:link]->(H1),
(H6)-[:link]->(H3),
(H6)-[:link]->(H5),
(H7)-[:link]->(H10),
(H8)-[:link]->(H7);
create().node_schema("user").edge_schema("link");
insert().into(@user).nodes([{_id:"H1"}, {_id:"H2"}, {_id:"H3"}, {_id:"H4"}, {_id:"H5"}, {_id:"H6"}, {_id:"H7"}, {_id:"H8"}, {_id:"H9"}, {_id:"H10"}, {_id:"S1"}, {_id:"S2"}, {_id:"S3"}, {_id:"S4"}]);
insert().into(@link).edges([{_from:"S2", _to:"H4"}, {_from:"S3", _to:"H6"}, {_from:"S4", _to:"S2"}, {_from:"S4", _to:"S3"}, {_from:"S4", _to:"H9"}, {_from:"H1", _to:"H9"}, {_from:"H2", _to:"H7"}, {_from:"H2", _to:"H10"}, {_from:"H3", _to:"H1"}, {_from:"H3", _to:"H5"}, {_from:"H4", _to:"H3"}, {_from:"H4", _to:"H6"}, {_from:"H5", _to:"H1"}, {_from:"H6", _to:"H1"}, {_from:"H6", _to:"H3"}, {_from:"H6", _to:"H5"}, {_from:"H7", _to:"H10"}, {_from:"H8", _to:"H7"}]);
Creating HDC Graph
To load the entire graph to the HDC server hdc-server-1 as my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}
hdc.graph.create("my_hdc_graph", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}).to("hdc-server-1")
Parameters
Algorithm name: sybil_rank
Name |
Type |
Spec |
Default |
Optional |
Description |
|---|---|---|---|---|---|
total_trust |
Float | >0 | / | No | Total trust assigned across all trust seeds. |
trust_seeds |
[]_uuid |
/ | / | Yes | Specifies the nodes selected as trust seeds by their _uuid. It is recommended to assign trust seeds for each community. If unset, all nodes are treated as trust seeds by default. |
loop_num |
Integer | >0 | 5 |
Yes | The maximum number of iteration rounds. The algorithm will terminate after completing all rounds. It is recommended to set this value as log2(|V|), where |V| is the number of nodes. |
return_id_uuid |
String | uuid, id, both |
uuid |
Yes | Includes _uuid, _id, or both values to represent nodes in the results. |
limit |
Integer | ≥-1 | -1 |
Yes | Limits the number of results returned; set to -1 to include all results. |
File Writeback
CALL algo.sybil_rank.write("my_hdc_graph", {
return_id_uuid: "id",
total_trust: 100,
// Assigns H2, H3, and H5 as trust seeds
trust_seeds: [8214567919347040353, 16429133639670825060, 15060039352950194277],
loop_num: 4
}, {
file: {
filename: "sybil_rank"
}
})
algo(sybil_rank).params({
projection: "my_hdc_graph",
return_id_uuid: "id",
total_trust: 100,
// Assigns H2, H3, and H5 as trust seeds
trust_seeds: [8214567919347040353, 16429133639670825060, 15060039352950194277],
loop_num: 4
}).write({
file: {
filename: "sybil_rank"
}
})
Result:
_id,sybil_rank
S1,0
S4,3.61111
S2,4.45602
S3,4.71065
H9,5.0434
H8,5.09259
H4,6.66667
H10,7.87037
H5,8.67766
H1,9.59491
H2,9.9537
H7,10.4167
H3,11.305
H6,12.6013
DB Writeback
Writes the sybil_rank values from the results to the specified node property. The property type is float.
CALL algo.sybil_rank.write("my_hdc_graph", {
return_id_uuid: "id",
total_trust: 100,
// Assigns H2, H3, and H5 as trust seeds
trust_seeds: [8214567919347040353, 16429133639670825060, 15060039352950194277],
loop_num: 4
}, {
db: {
property: "trust"
}
})
algo(sybil_rank).params({
projection: "my_hdc_graph",
return_id_uuid: "id",
total_trust: 100,
// Assigns H2, H3, and H5 as trust seeds
trust_seeds: [8214567919347040353, 16429133639670825060, 15060039352950194277],
loop_num: 4
}).write({
db:{
property: 'trust'
}
})
Full Return
CALL algo.sybil_rank.run("my_hdc_graph", {
return_id_uuid: "id",
total_trust: 100,
// Assigns H2, H3, and H5 as trust seeds
trust_seeds: [8214567919347040353, 16429133639670825060, 15060039352950194277],
loop_num: 4
}) YIELD trust
RETURN trust
exec{
algo(sybil_rank).params({
return_id_uuid: "id",
total_trust: 100,
// Assigns H2, H3, and H5 as trust seeds
trust_seeds: [8214567919347040353, 16429133639670825060, 15060039352950194277],
loop_num: 4
}) as trust
return trust
} on my_hdc_graph
Result:
| _id | sybil_rank |
|---|---|
| S1 | 0 |
| S4 | 3.611111 |
| S2 | 4.456018 |
| S3 | 4.710648 |
| H9 | 5.043402 |
| H8 | 5.092593 |
| H4 | 6.666666 |
| H10 | 7.87037 |
| H5 | 8.677661 |
| H1 | 9.594906 |
| H2 | 9.953703 |
| H7 | 10.41667 |
| H3 | 11.30498 |
| H6 | 12.60127 |
Stream Return
CALL algo.sybil_rank.stream("my_hdc_graph", {
return_id_uuid: "id",
total_trust: 100,
// Assigns H2, H3, and H5 as trust seeds
trust_seeds: [8214567919347040353, 16429133639670825060, 15060039352950194277],
loop_num: 4,
limit: 4
}) YIELD trust
RETURN trust
exec{
algo(sybil_rank).params({
return_id_uuid: "id",
total_trust: 100,
// Assigns H2, H3, and H5 as trust seeds
trust_seeds: [8214567919347040353, 16429133639670825060, 15060039352950194277],
loop_num: 4,
limit: 4
}).stream() as trust
return trust
} on my_hdc_graph
Result:
| _id | sybil_rank |
|---|---|
| S1 | 0 |
| S4 | 3.611111 |
| S2 | 4.456018 |
| S3 | 4.710648 |