
Overview
Overlap similarity is derived from Jaccard similarity, which is also called the Szymkiewicz–Simpson coefficient. It divides the size of the intersection of two sets by the size of the smaller set with the purpose to indicate how similar the two sets are.
Overlap similarity ranges from 0 to 1, where 1 indicates that one set is the subset of the other or that the two sets are identical, and 0 indicates that the sets have no elements in common.
Concepts
Overlap Similarity
Given two sets A and B, the overlap similarity between them is computed as:
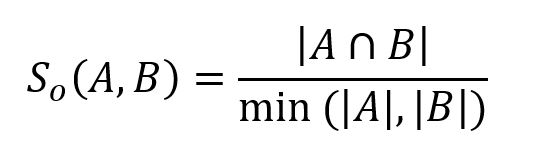
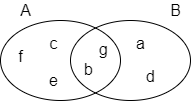
In the following example, set A = {b,c,e,f,g}, set B = {a,d,b,g}, their intersection A⋂B = {b,g}, hence the overlap similarity between A and B is 2 / 4 = 0.5.
When applying Overlap Similarity to compare two nodes in a graph, each node is represented by its 1-hop neighborhood set. The 1-hop neighborhood set:
- contains no repeated nodes;
- excludes the two target nodes.
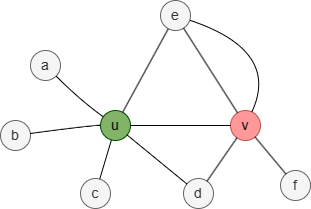
In this graph, the 1-hop neighborhood set of nodes u and v is:
- Nu = {a,b,c,d,e}
- Nv = {d,e,f}
Therefore, the Jaccard similarity between nodes u and v is 2 / 3 = 0.666667.
In practice, you may need to convert some node properties into node schemas in order to calculate the similarity index that is based on common neighbors, just as the overlap Similarity. For instance, when considering the similarity between two applications, information like phone number, email, device IP, etc. of the application might have been stored as properties of @application node schema; they need to be designed as nodes and incorporated into the graph in order to be used for comparison.
Weighted Overlap Similarity
The Weighted Overlap Similarity is an extension of the classic Overlap Similarity that takes into account the weights associated with elements in the sets being compared.
The formula for Weighted Overlap Similarity is given by:
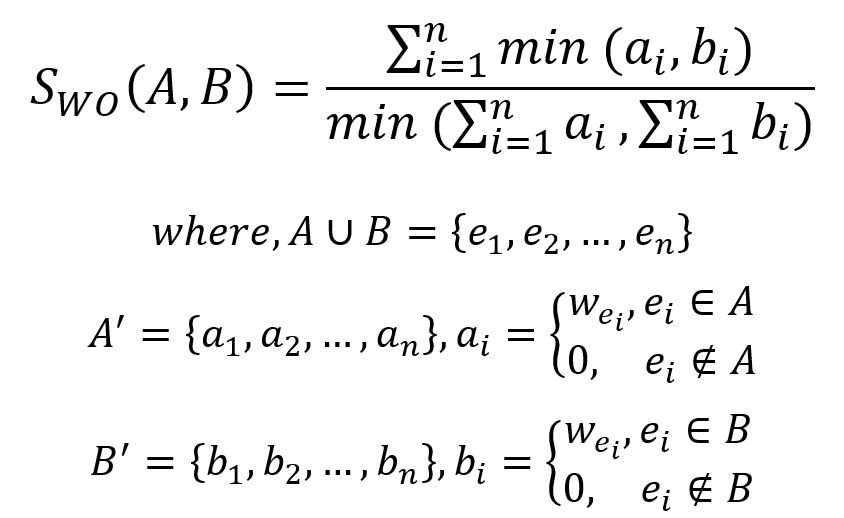
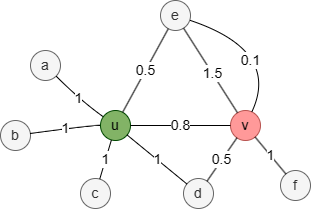
In this weighted graph, the union of the 1-hop neighborhood sets Nu and Nv is {a,b,c,d,e,f}. For each element in the union set, assign a value equal to the sum of the edge weights between the target node and the corresponding node; assign 0 if no edge exists between them:
| a | b | c | d | e | f | sum | |
|---|---|---|---|---|---|---|---|
| N'u | 1 | 1 | 1 | 1 | 0.5 | 0 | 4.5 |
| N'v | 0 | 0 | 0 | 0.5 | 1.5 + 0.1 =1.6 | 1 | 3.1 |
Therefore, the Weighted Overlap Similarity between nodes u and v is (0+0+0+0.5+0.5+0) / 3.1 = 0.322581.
Please ensure that the sum of the edge weights between the target node and the neighboring node is greater than or equal to 0.
Considerations
- The Overlap Similarity algorithm treats all edges as undirected, ignoring their original direction.
- The Overlap Similarity algorithm ignores any self-loop.
Example Graph
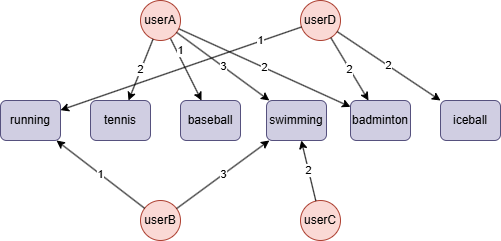
Run the following statements on an empty graph to define its structure and insert data:
ALTER GRAPH CURRENT_GRAPH ADD NODE {
user (),
sport()
};
ALTER GRAPH CURRENT_GRAPH ADD EDGE {
like ()-[{weight int32}]->()
};
INSERT (userA:user {_id: "userA"}),
(userB:user {_id: "userB"}),
(userC:user {_id: "userC"}),
(userD:user {_id: "userD"}),
(running:sport {_id: "running"}),
(tennis:sport {_id: "tennis"}),
(baseball:sport {_id: "baseball"}),
(swimming:sport {_id: "swimming"}),
(badminton:sport {_id: "badminton"}),
(iceball:sport {_id: "iceball"}),
(userA)-[:like {weight: 2}]->(tennis),
(userA)-[:like {weight: 1}]->(baseball),
(userA)-[:like {weight: 3}]->(swimming),
(userA)-[:like {weight: 2}]->(badminton),
(userB)-[:like {weight: 1}]->(running),
(userB)-[:like {weight: 3}]->(swimming),
(userC)-[:like {weight: 2}]->(swimming),
(userD)-[:like {weight: 1}]->(running),
(userD)-[:like {weight: 2}]->(badminton),
(userD)-[:like {weight: 2}]->(iceball);
create().node_schema("user").node_schema("sport").edge_schema("like");
create().edge_property(@like, "weight", int32);
insert().into(@user).nodes([{_id:"userA"}, {_id:"userB"}, {_id:"userC"}, {_id:"userD"}]);
insert().into(@sport).nodes([{_id:"running"}, {_id:"tennis"}, {_id:"baseball"}, {_id:"swimming"}, {_id:"badminton"}, {_id:"iceball"}]);
insert().into(@like).edges([{_from:"userA", _to:"tennis", weight:2}, {_from:"userA", _to:"baseball", weight:1}, {_from:"userA", _to:"swimming", weight:3}, {_from:"userA", _to:"badminton", weight:2}, {_from:"userB", _to:"running", weight:1}, {_from:"userB", _to:"swimming", weight:3}, {_from:"userC", _to:"swimming", weight:2}, {_from:"userD", _to:"running", weight:1}, {_from:"userD", _to:"badminton", weight:2}, {_from:"userD", _to:"iceball", weight:2}]);
Creating HDC Graph
To load the entire graph to the HDC server hdc-server-1 as my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}
hdc.graph.create("my_hdc_graph", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}).to("hdc-server-1")
Parameters
Algorithm name: similarity
| Name | Type | Spec | Default | Optional | Description | |
|---|---|---|---|---|---|---|
ids/uuids |
_id/_uuid |
Yes | Specifies the first group of nodes by their _id or _uuid. If unset, all nodes in the graph are used as the first group of nodes. |
The algorithm supports two calculation modes:
|
||
ids2/uuids2 |
_id/_uuid |
Yes | Specifies the second group of nodes for pairwise similarity by their _id or _uuid. If only ids2/uuids2 is set (and ids/uuids is not), the algorithm returns no result. |
|||
type |
String | overlap |
cosine |
No | Specifies the type of similarity to compute; for Overlap Similarity, keep it as overlap. |
|
edge_weight_property |
[]"<@schema.?><property>" |
Yes | Specifies numeric edge properties to be used as edge weights by summing their values; edges without these properties are ignored. | |||
return_id_uuid |
String | uuid,id,both |
uuid |
Yes | Includes _uuid, _id, or both to represent nodes in the results. |
|
order |
String | asc,desc |
Yes | Sorts the results by similarity. |
||
limit |
Integer | ≥-1 | -1 |
Yes | Limits the number of results returned. Set to -1 to include all results. |
|
top_limit |
Integer | ≥-1 | -1 |
Yes | Limits the number of results returned for each node specified with ids/uuids in selection mode. Set to -1 to include all results with a similarity greater than 0. This parameter is invalid in pairing mode. |
|
File Writeback
CALL algo.similarity.write("my_hdc_graph", {
return_id_uuid: "id",
ids: "userC",
ids2: ["userA", "userB", "userD"],
type: "overlap"
}, {
file: {
filename: "overlap"
}
})
algo(similarity).params({
projection: "my_hdc_graph",
return_id_uuid: "id",
ids: "userC",
ids2: ["userA", "userB", "userD"],
type: "overlap"
}).write({
file: {
filename: "overlap"
}
})
Result:
_id1,_id2,similarity
userC,userA,1
userC,userB,1
userC,userD,0
Full Return
Computes similarities in pairing mode:
CALL algo.similarity.run("my_hdc_graph", {
return_id_uuid: "id",
ids: ["userA","userB"],
ids2: ["userB","userC","userD"],
type: "overlap"
}) YIELD overlap
RETURN overlap
exec{
algo(similarity).params({
return_id_uuid: "id",
ids: ["userA","userB"],
ids2: ["userB","userC","userD"],
type: "overlap"
}) as overlap
return overlap
} on my_hdc_graph
Result:
| _id1 | _id2 | similarity |
|---|---|---|
| userA | userB | 0.5 |
| userA | userC | 1 |
| userA | userD | 0.333333 |
| userB | userC | 1 |
| userB | userD | 0.5 |
Stream Return
CALL algo.similarity.stream("my_hdc_graph", {
return_id_uuid: "id",
ids: ["userA"],
type: "overlap",
edge_weight_property: "weight",
top_limit: 2
}) YIELD overlap
RETURN overlap
exec{
algo(similarity).params({
return_id_uuid: "id",
ids: ["userA"],
type: "overlap",
edge_weight_property: "weight",
top_limit: 2
}).stream() as overlap
return overlap
} on my_hdc_graph
Result:
| _id1 | _id2 | similarity |
|---|---|---|
| userA | userC | 1 |
| userA | userB | 0.75 |