PageRank
Overview
PageRank was originally proposed in the context of World Wide Web (WWW), it takes advantage of the link structure of WWW to produce a global objective 'importance' ranking of webpages that can be used by search engines. This algorithm was proposed in 1997-1998 by Google co-founders Larry Page and Sergey Brin.
- L. Page, S Brin, R. Motwani, T. Winograd, The PageRank Citation Ranking: Bringing Order to The Web (1998)
With the development of technology and the emergence of enormous correlation data, PageRank has been adopted in many other fields too.
Concepts
Link Structure and PageRank
In WWW, hypertexts contained in webpages create links between webpages. Every webpage (node) can have some forward links (via out-edges) and backlinks (via in-edges). In the following graph, A and B are backlinks of C, D is a forward link of C.
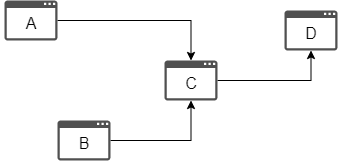
Webpages vary greatly in terms of the number of backlinks they have. Naturally, webpages that are more important, authoritative or of high quality are likely to receive more or more important backlinks.
PageRank can be described as this: a page has high rank if the sum of the ranks of its backlinks is high. This covers both the case when a page has many backlinks and when a page has a few highly ranked backlinks.
Rank Propagation
The ranks (scores) of all pages are computed in a recursive way by starting with equals ranks and iterating the computation until it converges. In each iteration, a page gives out its rank to all its forward links evenly to contribute to the ranks of the pages it points to; meanwhile every page receives ranks from its backlinks, so the rank of page u after one iteration is:
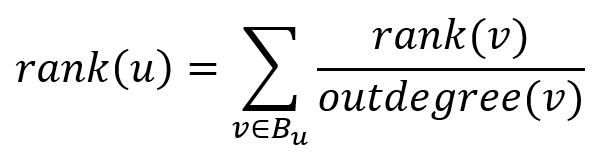
where Bu is the backlink set of u.
Below shows a steady state of a set of pages:
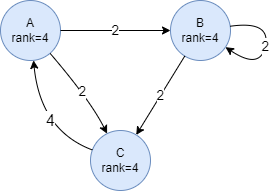
Damping Factor
Consider the following kinds of webpages:
- Webpages with no backlinks. The rank they receive is 0, but they still need to be browsed in the Internet.
- Webpages with no forward links. Their ranks are lost from the system.
- A group of webpages that only point to pages within the group, but not any page outside the group.
To overcome these problems, a damping factor, whose value is between 0 and 1, is introduced. It gives each webpage a base rank while weakening the ranks passed from backlinks. The rank of page u after one iteration becomes:
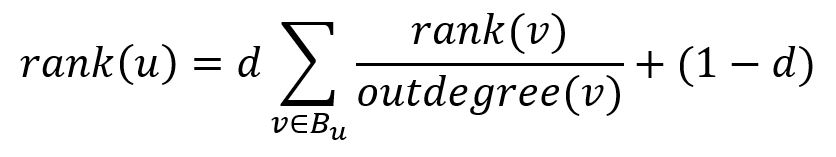
where d is the damping factor. For example, when d is 0.7, if a webpage receives 8 ranks in total from backlinks, then the rank of this webpage is updated to 0.7 * 8 + (1 - 0.7) = 5.9.
Damping factor can also be understood as the probability that a web surfer randomly jump to a webpage that is not one of the forward links of the current webpage.
Considerations
- The implementation uses a normalized variant where scores sum to 1. The base rank
(1 - d)is replaced by(1 - d) / n, wherenis the total number of nodes. Additionally, ranks from dangling nodes (nodes with no outgoing edges) are redistributed equally to all nodes. - Self-loop is regarded as a forward link and a backlink, a webpage would pass some rank to itself through self-loop. If a network has many self-loops, it will take more iterations to converge.
Example Graph
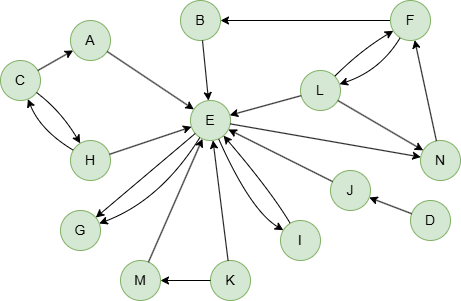
GQLINSERT (A:account {_id: "A"}), (B:account {_id: "B"}), (C:account {_id: "C"}), (D:account {_id: "D"}), (E:account {_id: "E"}), (F:account {_id: "F"}), (G:account {_id: "G"}), (H:account {_id: "H"}), (I:account {_id: "I"}), (J:account {_id: "J"}), (K:account {_id: "K"}), (L:account {_id: "L"}), (M:account {_id: "M"}), (N:account {_id: "N"}), (A)-[:follow]->(E), (B)-[:follow]->(E), (C)-[:follow]->(A), (C)-[:follow]->(H), (D)-[:follow]->(J), (E)-[:follow]->(G), (E)-[:follow]->(G), (E)-[:follow]->(I), (E)-[:follow]->(N), (F)-[:follow]->(L), (F)-[:follow]->(B), (H)-[:follow]->(C), (H)-[:follow]->(E), (I)-[:follow]->(E), (J)-[:follow]->(E), (K)-[:follow]->(E), (K)-[:follow]->(M), (L)-[:follow]->(E), (L)-[:follow]->(F), (L)-[:follow]->(N), (M)-[:follow]->(E), (N)-[:follow]->(F)
Parameters
| Name | Type | Default | Description |
|---|---|---|---|
damping | FLOAT | 0.85 | Damping factor (0, 1). |
maxIterations | INT | 20 | Maximum number of iterations. |
tolerance | FLOAT | 0.0001 | Convergence tolerance. The algorithm terminates when score changes between iterations are less than this value. |
weight | STRING or LIST | / | Numeric edge property for weighted rank distribution. |
limit | INT | -1 | Limits the number of results returned (-1 = all). |
order | STRING | / | Sorts the results by score: asc or desc. |
Run Mode
Returns:
| Column | Type | Description |
|---|---|---|
nodeId | STRING | Node identifier (_id) |
score | FLOAT | PageRank score |
PageRank for all nodes:
GQLCALL algo.pagerank({ damping: 0.8, maxIterations: 50, order: "desc" }) YIELD nodeId, score
Result:
| nodeId | score |
|---|---|
| E | 0.2550063371540463 |
| G | 0.12333269655544102 |
| F | 0.11070550559238909 |
| N | 0.08983117739672632 |
| I | 0.0723337230447896 |
| B | 0.06559521101715528 |
| L | 0.06559521101715528 |
| J | 0.038396473053816244 |
| A | 0.035556184935409005 |
| C | 0.035556184935409005 |
| H | 0.035556184935409005 |
| M | 0.029865611293977218 |
| D | 0.02133474953413819 |
| K | 0.02133474953413819 |
Stream Mode
Returns the same columns as run mode, streamed for memory efficiency.
GQLCALL algo.pagerank.stream({ order: "desc", limit: 5 }) YIELD nodeId, score RETURN nodeId, score
Result:
| nodeId | score |
|---|---|
| E | 0.25846767606283216 |
| G | 0.12838400892861568 |
| F | 0.11660864291160089 |
| N | 0.09272286734279425 |
| I | 0.0734462966191566 |
Stats Mode
Returns:
| Column | Type | Description |
|---|---|---|
nodeCount | INT | Total number of nodes |
minScore | FLOAT | Minimum PageRank score |
maxScore | FLOAT | Maximum PageRank score |
avgScore | FLOAT | Average PageRank score |
GQLCALL algo.pagerank.stats() YIELD nodeCount, minScore, maxScore, avgScore
Result:
| nodeCount | minScore | maxScore | avgScore |
|---|---|---|---|
| 14 | 0.018508584309697512 | 0.25846767606283216 | 0.07142857142857142 |
Write Mode
Computes results and writes them back to node properties. The write configuration is passed as a second argument map.
Write parameters:
| Name | Type | Description |
|---|---|---|
db.property | STRING or MAP | Node property to write results to. String: writes the score column in results to a property. Map: explicit column-to-property mapping (e.g., {score: 'pr_score'}). |
Writable columns:
| Column | Type | Description |
|---|---|---|
score | FLOAT | PageRank score |
Returns:
| Column | Type | Description |
|---|---|---|
task_id | STRING | Task identifier for tracking via SHOW TASKS |
nodesWritten | INT | Number of nodes with properties written |
computeTimeMs | INT | Time spent computing the algorithm (milliseconds) |
writeTimeMs | INT | Time spent writing properties to storage (milliseconds) |
GQLCALL algo.pagerank.write({damping: 0.85}, { db: { property: "pr_score" } }) YIELD task_id, nodesWritten, computeTimeMs, writeTimeMs