Overlap Similarity
Overview
Overlap similarity is derived from Jaccard similarity, which is also called the Szymkiewicz–Simpson coefficient. It divides the size of the intersection of two sets by the size of the smaller set with the purpose to indicate how similar the two sets are.
Overlap similarity ranges from 0 to 1, where 1 indicates that one set is the subset of the other or that the two sets are identical, and 0 indicates that the sets have no elements in common.
Concepts
Overlap Similarity
Given two sets A and B, the overlap similarity between them is computed as:
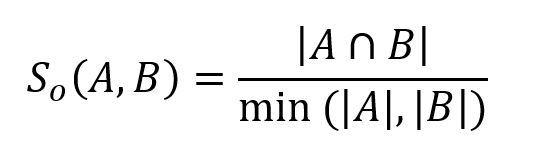
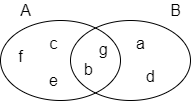
In the following example, set A = {b,c,e,f,g}, set B = {a,d,b,g}, their intersection A⋂B = {b,g}, hence the overlap similarity between A and B is 2 / 4 = 0.5.
When applying Overlap Similarity to compare two nodes in a graph, each node is represented by its 1-hop neighborhood set. The 1-hop neighborhood set:
- contains no repeated nodes;
- excludes the two target nodes.
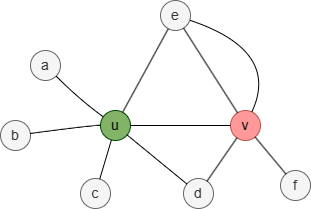
In this graph, the 1-hop neighborhood set of nodes u and v is:
- Nu = {a,b,c,d,e}
- Nv = {d,e,f}
Therefore, the overlap similarity between nodes u and v is 2 / 3 = 0.666667.
Weighted Overlap Similarity
The Weighted Overlap Similarity is an extension of the classic Overlap Similarity that takes into account the weights associated with elements in the sets being compared.
The formula for Weighted Overlap Similarity is given by:
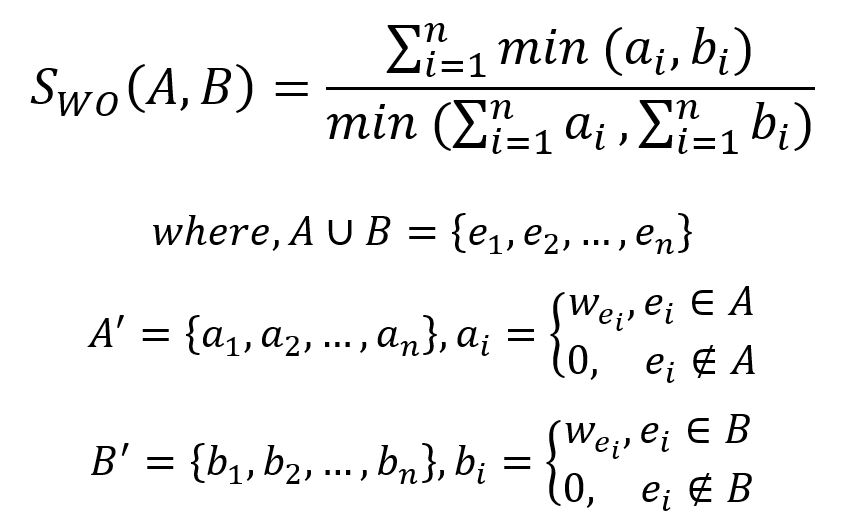
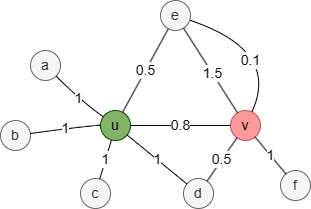
In this weighted graph, the union of the 1-hop neighborhood sets Nu and Nv is {a,b,c,d,e,f}. For each element in the union set, assign a value equal to the sum of the edge weights between the target node and the corresponding node; assign 0 if no edge exists between them:
| a | b | c | d | e | f | sum | |
|---|---|---|---|---|---|---|---|
| N'u | 1 | 1 | 1 | 1 | 0.5 | 0 | 4.5 |
| N'v | 0 | 0 | 0 | 0.5 | 1.5 + 0.1 =1.6 | 1 | 3.1 |
Therefore, the Weighted Overlap Similarity between nodes u and v is (0+0+0+0.5+0.5+0) / 3.1 = 0.322581.
Considerations
- The algorithm treats all edges as undirected.
- Self-loops are ignored when computing neighborhoods.
Example Graph
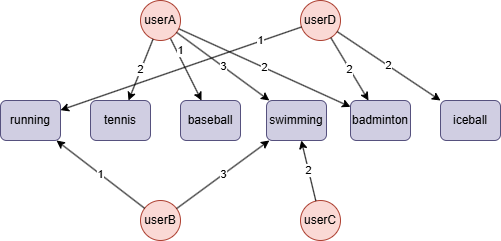
GQLINSERT (userA:user {_id: "userA"}), (userB:user {_id: "userB"}), (userC:user {_id: "userC"}), (userD:user {_id: "userD"}), (running:sport {_id: "running"}), (tennis:sport {_id: "tennis"}), (baseball:sport {_id: "baseball"}), (swimming:sport {_id: "swimming"}), (badminton:sport {_id: "badminton"}), (iceball:sport {_id: "iceball"}), (userA)-[:likes {weight: 2}]->(tennis), (userA)-[:likes {weight: 1}]->(baseball), (userA)-[:likes {weight: 3}]->(swimming), (userA)-[:likes {weight: 2}]->(badminton), (userB)-[:likes {weight: 1}]->(running), (userB)-[:likes {weight: 3}]->(swimming), (userC)-[:likes {weight: 2}]->(swimming), (userD)-[:likes {weight: 1}]->(running), (userD)-[:likes {weight: 2}]->(badminton), (userD)-[:likes {weight: 2}]->(iceball)
Parameters
| Name | Type | Default | Description |
|---|---|---|---|
type | STRING | jaccard | Type of similarity to compute: overlap. |
ids | LIST | / | First group of node _ids. If empty, all nodes are used. |
ids2 | LIST | / | Second group of node _ids for pairing mode. If empty, selection mode is used. |
weight | LIST | / | Numeric edge properties used as weights for weighted overlap. |
degreeCutoff | INT | 0 | Minimum degree to include a node (0 = no cutoff). |
order | STRING | / | Sorts results by similarity: asc or desc. |
limit | INT | -1 | Maximum total results returned (-1 = all). |
top_limit | INT | -1 | Maximum results per source node in selection mode (-1 = all). |
Supports three computation modes:
- All-pairs: When both
idsandids2are empty, computes similarity between all node pairs in the graph. - Pairing: When both
idsandids2are specified, computes similarity between each node inidsand each node inids2. - Selection: When only
idsis specified (noids2), computes similarity between each node inidsand all other nodes. Usetop_limitto limit results per source node.
Run Mode
Returns:
| Column | Type | Description |
|---|---|---|
node1 | STRING | First node identifier (_id) |
node2 | STRING | Second node identifier (_id) |
similarity | FLOAT | Computed overlap similarity score |
Overlap similarity in pairing mode:
GQLCALL algo.similarity({ type: "overlap", ids: ["userA", "userB"], ids2: ["userB", "userC", "userD"] }) YIELD node1, node2, similarity
Result:
| node1 | node2 | similarity |
|---|---|---|
| userA | userB | 0.5 |
| userA | userC | 1 |
| userA | userD | 0.3333333333333333 |
| userB | userC | 1 |
| userB | userD | 0.5 |
Overlap similarity in selection mode:
GQLCALL algo.similarity({ type: "overlap", ids: ["userA"], weight: ["weight"], top_limit: 2 }) YIELD node1, node2, similarity
Result:
| node1 | node2 | similarity |
|---|---|---|
| userA | userC | 1 |
| userA | userB | 0.75 |
Stream Mode
Returns the same columns as run mode, streamed for memory efficiency.
GQLCALL algo.similarity.stream({ type: "overlap", degreeCutoff: 3 }) YIELD node1, node2, similarity RETURN node1, node2, similarity
Result:
| node1 | node2 | similarity |
|---|---|---|
| swimming | userA | 0 |
| swimming | userD | 0 |
| userA | swimming | 0 |
| userA | userD | 0.3333333333333333 |
| userD | swimming | 0 |
| userD | userA | 0.3333333333333333 |
Stats Mode
Returns:
| Column | Type | Description |
|---|---|---|
pairCount | INT | Number of node pairs computed |
minSimilarity | FLOAT | Minimum similarity score |
maxSimilarity | FLOAT | Maximum similarity score |
avgSimilarity | FLOAT | Average similarity score |
GQLCALL algo.similarity.stats({ type: "overlap" }) YIELD pairCount, minSimilarity, maxSimilarity, avgSimilarity
Result:
| pairCount | minSimilarity | maxSimilarity | avgSimilarity |
|---|---|---|---|
| 90 | 0 | 1 | 0.26296296296296295 |
Write Mode
Computes results and writes them back to node properties. The write configuration is passed as a second argument map.
Write parameters:
| Name | Type | Description |
|---|---|---|
db.property | STRING or MAP | Node property to write results to. String: writes the similarity column in results to a property. Map: explicit column-to-property mapping (e.g., {similarity: 'sim_score'}). |
Writable columns:
| Column | Type | Description |
|---|---|---|
similarity | FLOAT | Computed overlap similarity score |
Returns:
| Column | Type | Description |
|---|---|---|
task_id | STRING | Task identifier for tracking via SHOW TASKS |
nodesWritten | INT | Number of nodes with properties written |
computeTimeMs | INT | Time spent computing the algorithm (milliseconds) |
writeTimeMs | INT | Time spent writing properties to storage (milliseconds) |
GQLCALL algo.similarity.write({type: "overlap", ids: ["userA", "userB"]}, { db: { property: "sim_score" } }) YIELD task_id, nodesWritten, computeTimeMs, writeTimeMs