Katz Centrality
Overview
Katz Centrality measures the influence of a node by considering not only its immediate connections but also its indirect connections at various distances while diminishing importance to more distant nodes.
Katz centrality scores range from 0 to 1, with higher scores indicating nodes that exert greater influence over the flow and connectivity of the network.
References:
- L. Katz, A New Status Index Derived from Sociometric Analysis (1953)
Concepts
Katz Centrality
The Katz centrality is an extension of the eigenvector centrality. In the k-th round of influence propagation in eigenvector centrality, the centrality vector is simply updated as c(k) = Ac(k-1), where A is the adjacency matrix. Katz centrality modifies this computation by introducing two additional parameters, leading to the following update formula (which should be rescaled afterward):
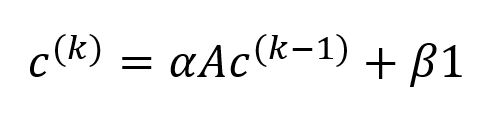
where,
α(alpha) is an attenuation factor that controls how influence decays during each propagation round. In thek-th round, the influences from indirect neighbors that areksteps away are considered, with their contributions cumulatively attenuated by a factor ofαk. To ensure the convergence ofc(k),αmust be smaller than1/λmax, whereλmaxis the dominant eigenvalue of the adjacency matrixA.β(beta) is a baseline centrality constant that ensures each node has a nonzero centrality score, even when it receives no influence. The common choice forβis 1.1is an n × 1 column vector of ones, where n is the number of nodes in the graph.
Example Graph
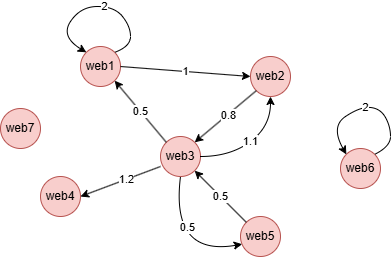
GQLINSERT (web1:web {_id: "web1"}), (web2:web {_id: "web2"}), (web3:web {_id: "web3"}), (web4:web {_id: "web4"}), (web5:web {_id: "web5"}), (web6:web {_id: "web6"}), (web7:web {_id: "web7"}), (web1)-[:link {value: 2}]->(web1), (web1)-[:link {value: 1}]->(web2), (web2)-[:link {value: 0.8}]->(web3), (web3)-[:link {value: 0.5}]->(web1), (web3)-[:link {value: 1.1}]->(web2), (web3)-[:link {value: 1.2}]->(web4), (web3)-[:link {value: 0.5}]->(web5), (web5)-[:link {value: 0.5}]->(web3), (web6)-[:link {value: 2}]->(web6)
Parameters
| Name | Type | Default | Description |
|---|---|---|---|
ids | LIST | / | _ids of nodes to compute (empty = all nodes). |
direction | STRING | in | Edge direction: in, out, or both. |
alpha | FLOAT | 0.1 | Attenuation factor. Must be less than 1/λmax (the inverse of the dominant eigenvalue) to ensure convergence. |
beta | FLOAT | 1.0 | Baseline centrality constant that ensures every node has a nonzero score. |
maxIterations | INT | 20 | Maximum number of iterations. |
tolerance | FLOAT | 0.0001 | Convergence tolerance. The algorithm terminates when score changes between iterations are less than this value. |
weight | STRING or LIST | / | Numeric edge property for weighted adjacency. |
limit | INT | -1 | Limits the number of results returned (-1 = all). |
order | STRING | / | Sorts the results by score: asc or desc. |
Run Mode
Returns:
| Column | Type | Description |
|---|---|---|
nodeId | STRING | Node identifier (_id) |
score | FLOAT | Katz centrality score |
rank | INT | Rank position (1 = highest Katz centrality) |
Katz centrality for all nodes:
GQLCALL algo.katz({ alpha: 0.4, maxIterations: 50, tolerance: 0.00001, direction: "in", order: "desc" }) YIELD nodeId, score, rank
Result:
| nodeId | score | rank |
|---|---|---|
| web1 | 0.5176013388871611 | 1 |
| web2 | 0.5176013388871611 | 2 |
| web3 | 0.4584471552476096 | 3 |
| web5 | 0.310561275163056 | 4 |
| web4 | 0.310561275163056 | 5 |
| web6 | 0.21197131907129865 | 6 |
| web7 | 0.1271827914427794 | 7 |
Stream Mode
Returns the same columns as run mode, streamed for memory efficiency.
GQLCALL algo.katz.stream({ alpha: 0.4, beta: 1, maxIterations: 100, tolerance: 0.00001, direction: "in", weight: ["value"], order: "desc" }) YIELD nodeId, score RETURN nodeId, score
Result:
| nodeId | score |
|---|---|
| web1 | 0.6810846911779451 |
| web2 | 0.47152057141524206 |
| web6 | 0.41913155186031176 |
| web3 | 0.261956256842494 |
| web4 | 0.20956523570603208 |
| web5 | 0.1362175333809225 |
| web7 | 0.08382631743441561 |
Stats Mode
Returns:
| Column | Type | Description |
|---|---|---|
nodeCount | INT | Total number of nodes |
minScore | FLOAT | Minimum Katz centrality score |
maxScore | FLOAT | Maximum Katz centrality score |
avgScore | FLOAT | Average Katz centrality score |
GQLCALL algo.katz.stats() YIELD nodeCount, minScore, maxScore, avgScore
Result:
| nodeCount | minScore | maxScore | avgScore |
|---|---|---|---|
| 7 | 0.3260142211773941 | 0.4070522281639013 | 0.3769151009705816 |
Write Mode
Computes results and writes them back to node properties. The write configuration is passed as a second argument map.
Write parameters:
| Name | Type | Description |
|---|---|---|
db.property | STRING or MAP | Node property to write results to. String: writes the score column in results to a property. Map: explicit column-to-property mapping (e.g., {score: 'katz_score', rank: 'katz_rank'}). |
Writable columns:
| Column | Type | Description |
|---|---|---|
score | FLOAT | Katz centrality score |
rank | INT | Rank position |
Returns:
| Column | Type | Description |
|---|---|---|
task_id | STRING | Task identifier for tracking via SHOW TASKS |
nodesWritten | INT | Number of nodes with properties written |
computeTimeMs | INT | Time spent computing the algorithm (milliseconds) |
writeTimeMs | INT | Time spent writing properties to storage (milliseconds) |
GQLCALL algo.katz.write({alpha: 0.1}, { db: { property: "katz_score" } }) YIELD task_id, nodesWritten, computeTimeMs, writeTimeMs