Cosine Similarity
Overview
In cosine similarity, data objects in a dataset are treated as vectors, and it uses the cosine value of the angle between two vectors to indicate the similarity between them. In the graph, N numeric node properties (features) are specified to form N-dimensional vectors; two nodes are considered similar if their vectors are similar.
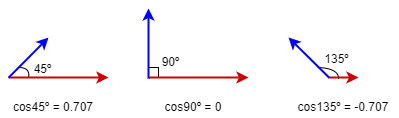
Cosine similarity ranges from -1 to 1, where 1 indicates that the two vectors point in the same direction, and -1 indicates they point in opposite directions.
Concepts
Cosine Similarity
In 2-dimensional space, the cosine similarity between vectors A = [a1, a2] and B = [b1, b2] is computed as:
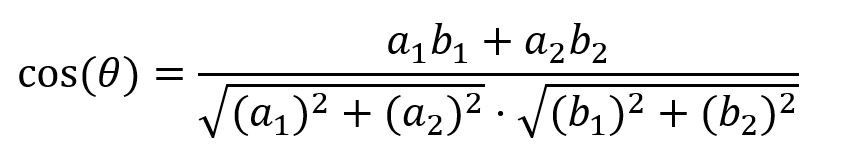
In 3-dimensional space, the cosine similarity between vectors A = [a1, a2, a3] and B = [b1, b2, b3] is computed as:
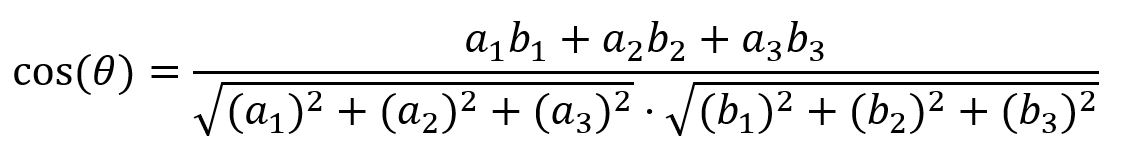
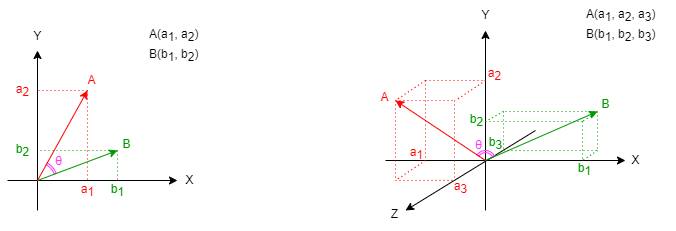
The following diagram shows the relationship between vectors A and B in 2D and 3D spaces, as well as the angle θ between them:
Generalized to N-dimensional space, cosine similarity is computed as:
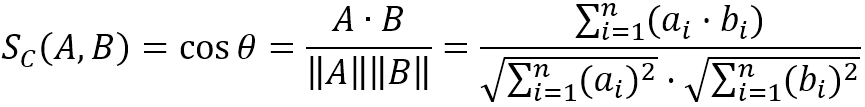
Considerations
- The calculation of cosine similarity between two nodes is independent of their connectivity in the graph.
- The value of cosine similarity is independent of the length of the vectors, but only the direction of the vectors.
Example Graph
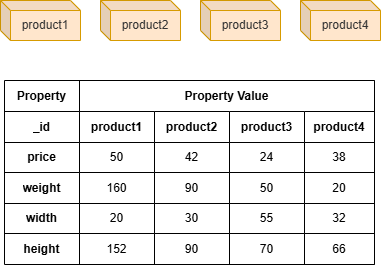
GQLINSERT (:product {_id: "product1", price: 50, weight: 160, width: 20, height: 152}), (:product {_id: "product2", price: 42, weight: 90, width: 30, height: 90}), (:product {_id: "product3", price: 24, weight: 50, width: 55, height: 70}), (:product {_id: "product4", price: 38, weight: 20, width: 32, height: 66})
Parameters
| Name | Type | Default | Description |
|---|---|---|---|
type | STRING | jaccard | Type of similarity to compute: cosine. |
ids | LIST | / | First group of node _ids. If empty, all nodes are used. |
ids2 | LIST | / | Second group of node _ids for pairing mode. If empty, selection mode is used. |
node_property | LIST | / | Required. Numeric node properties to form a vector for each node. |
degreeCutoff | INT | 0 | Minimum degree to include a node (0 = no cutoff). |
order | STRING | / | Sorts results by similarity: asc or desc. |
limit | INT | -1 | Maximum total results returned (-1 = all). |
top_limit | INT | -1 | Maximum results per source node in selection mode (-1 = all). |
Supports three computation modes:
- All-pairs: When both
idsandids2are empty, computes similarity between all node pairs in the graph. - Pairing: When both
idsandids2are specified, computes similarity between each node inidsand each node inids2. - Selection: When only
idsis specified (noids2), computes similarity between each node inidsand all other nodes. Usetop_limitto limit results per source node.
Run Mode
Returns:
| Column | Type | Description |
|---|---|---|
node1 | STRING | First node identifier (_id) |
node2 | STRING | Second node identifier (_id) |
similarity | FLOAT | Computed cosine similarity score |
Cosine similarity in pairing mode:
GQLCALL algo.similarity({ type: "cosine", ids: ["product1"], ids2: ["product2", "product3", "product4"], node_property: ["price", "weight", "width", "height"] }) YIELD node1, node2, similarity
Result:
| node1 | node2 | similarity |
|---|---|---|
| product1 | product2 | 0.9865294135291195 |
| product1 | product3 | 0.8788584075196542 |
| product1 | product4 | 0.8168761502672031 |
Cosine similarity in selection mode (top 1 per source node):
GQLCALL algo.similarity({ type: "cosine", ids: ["product1", "product3"], node_property: ["price", "weight", "width", "height"], top_limit: 1 }) YIELD node1, node2, similarity
Result:
| node1 | node2 | similarity |
|---|---|---|
| product1 | product2 | 0.9865294135291195 |
| product3 | product2 | 0.9342165307256634 |
Stream Mode
Returns the same columns as run mode, streamed for memory efficiency.
GQLCALL algo.similarity.stream({ type: "cosine", ids: ["product1"], node_property: ["price", "weight", "width", "height"], order: "desc" }) YIELD node1, node2, similarity RETURN node1, node2, similarity
Result:
| node1 | node2 | similarity |
|---|---|---|
| product1 | product2 | 0.9865294135291195 |
| product1 | product3 | 0.8788584075196542 |
| product1 | product4 | 0.8168761502672031 |
Stats Mode
Returns:
| Column | Type | Description |
|---|---|---|
pairCount | INT | Number of node pairs computed |
minSimilarity | FLOAT | Minimum similarity score |
maxSimilarity | FLOAT | Maximum similarity score |
avgSimilarity | FLOAT | Average similarity score |
GQLCALL algo.similarity.stats({ type: "cosine", node_property: ["price", "weight", "width", "height"] }) YIELD pairCount, minSimilarity, maxSimilarity, avgSimilarity
Result:
| pairCount | minSimilarity | maxSimilarity | avgSimilarity |
|---|---|---|---|
| 12 | 0.8168761502672031 | 0.9865294135291195 | 0.9047702651283608 |
Write Mode
Computes results and writes them back to node properties. The write configuration is passed as a second argument map.
Write parameters:
| Name | Type | Description |
|---|---|---|
db.property | STRING or MAP | Node property to write results to. String: writes the similarity column in results to a property. Map: explicit column-to-property mapping (e.g., {similarity: 'cos_score'}). |
Writable columns:
| Column | Type | Description |
|---|---|---|
similarity | FLOAT | Computed cosine similarity score |
Returns:
| Column | Type | Description |
|---|---|---|
task_id | STRING | Task identifier for tracking via SHOW TASKS |
nodesWritten | INT | Number of nodes with properties written |
computeTimeMs | INT | Time spent computing the algorithm (milliseconds) |
writeTimeMs | INT | Time spent writing properties to storage (milliseconds) |
GQLCALL algo.similarity.write({ type: "cosine", ids: ["product1", "product2"], node_property: ["price", "weight", "width", "height"] }, { db: { property: "sim_score" } }) YIELD task_id, nodesWritten, computeTimeMs, writeTimeMs