Label Propagation
Overview
The Label Propagation algorithm (LPA) is a community detection method based on label propagation. Initially, each node is assigned a unique label. During each iteration, every node updates its label to the one most common among its neighbors. Through this iterative process, densely connected groups of nodes tend to reach a consensus on a shared label, with nodes sharing the same label ultimately forming a community.
LPA does not optimize any specific predefined measure of community quality, nor does it require the number of communities to be specified in advance. Instead, it relies purely on the network's structure to guide the progression. Its simplicity makes LPA highly efficient for analyzing large and complex networks.
Related material of the algorithm:
- U.N. Raghavan, R. Albert, S. Kumara, Near linear time algorithm to detect community structures in large-scale networks (2007)
Concepts
Label
Each node is initialized with a unique label (based on its internal ID). Nodes sharing the same label at the end of the algorithm are considered members of the same community.
Label Propagation
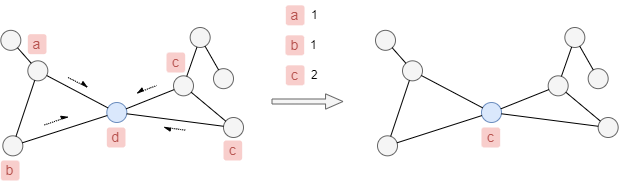
At each propagation iteration, a node updates its label to the one held by the largest number of its neighbors.
For example, in the diagram below, the blue node's label will change from d to c.
Considerations
- The algorithm treats all edges as undirected.
- A node with self-loops propagates its current label to itself, with each self-loop counted twice.
- LPA follows a synchronous update principle, where all nodes update their labels simultaneously based on their neighbors' current labels. However, in some cases—especially in bipartite graphs—label oscillations may occur.
- Due to factors such as the order of nodes, random tie-breaking when multiple labels have equal counts, and parallel computations, the results may vary between runs. Use the
seedparameter for reproducibility.
Example Graph

GQLINSERT (A:user {_id: "A"}), (B:user {_id: "B"}), (C:user {_id: "C"}), (D:user {_id: "D"}), (E:user {_id: "E"}), (F:user {_id: "F"}), (G:user {_id: "G"}), (H:user {_id: "H"}), (I:user {_id: "I"}), (J:user {_id: "J"}), (K:user {_id: "K"}), (L:user {_id: "L"}), (M:user {_id: "M"}), (N:user {_id: "N"}), (O:user {_id: "O"}), (A)-[:connect]->(B), (A)-[:connect]->(C), (A)-[:connect]->(F), (A)-[:connect]->(K), (B)-[:connect]->(C), (C)-[:connect]->(D), (D)-[:connect]->(A), (D)-[:connect]->(E), (E)-[:connect]->(A), (F)-[:connect]->(G), (F)-[:connect]->(J), (G)-[:connect]->(H), (H)-[:connect]->(F), (I)-[:connect]->(F), (I)-[:connect]->(H), (J)-[:connect]->(I), (K)-[:connect]->(F), (K)-[:connect]->(N), (L)-[:connect]->(M), (L)-[:connect]->(N), (M)-[:connect]->(K), (M)-[:connect]->(N), (N)-[:connect]->(M), (O)-[:connect]->(N)
Parameters
| Name | Type | Default | Description |
|---|---|---|---|
maxIterations | INT | 100 | Maximum number of propagation iterations. |
seed | INT | -1 | Random seed. -1 uses a time-based seed (non-deterministic). Any other value produces reproducible results. |
limit | INT | -1 | Limits the number of results returned (-1 = all). |
order | STRING | / | Sorts the results by community: asc or desc. |
Run Mode
Returns:
| Column | Type | Description |
|---|---|---|
nodeId | STRING | Node identifier (_id) |
community | INT | Community identifier |
iterations | INT | Number of iterations until convergence |
GQLCALL algo.lpa({}) YIELD nodeId, community, iterations
Result:
| nodeId | community | iterations |
|---|---|---|
| E | 0 | 3 |
| D | 0 | 3 |
| G | 1 | 3 |
| F | 1 | 3 |
| A | 0 | 3 |
| C | 0 | 3 |
| B | 0 | 3 |
| M | 2 | 3 |
| L | 2 | 3 |
| O | 2 | 3 |
| N | 2 | 3 |
| I | 1 | 3 |
| H | 1 | 3 |
| K | 2 | 3 |
| J | 1 | 3 |
Stream Mode
Returns the same columns as run mode, streamed for memory efficiency.
GQLCALL algo.lpa.stream() YIELD nodeId, community RETURN community, COLLECT(nodeId) AS members, COUNT(nodeId) AS size GROUP BY community
Result:
| community | members | size |
|---|---|---|
| 0 | ["E", "D", "A", "C", "B"] | 5 |
| 1 | ["G", "F", "I", "H", "J"] | 5 |
| 2 | ["M", "L", "O", "N", "K"] | 5 |
Stats Mode
Returns:
| Column | Type | Description |
|---|---|---|
nodeCount | INT | Total number of nodes |
communityCount | INT | Number of communities detected |
largestCommunitySize | INT | Size of the largest community |
smallestCommunitySize | INT | Size of the smallest community |
GQLCALL algo.lpa.stats() YIELD nodeCount, communityCount, largestCommunitySize, smallestCommunitySize
Result:
| nodeCount | communityCount | largestCommunitySize | smallestCommunitySize |
|---|---|---|---|
| 15 | 3 | 5 | 5 |
Write Mode
Computes results and writes them back to node properties. The write configuration is passed as a second argument map.
Write parameters:
| Name | Type | Description |
|---|---|---|
db.property | STRING or MAP | Node property to write results to. String: writes the community column in results to a property. Map: explicit column-to-property mapping (e.g., {community: 'comm_id'}). |
Writable columns:
| Column | Type | Description |
|---|---|---|
community | INT | Community identifier |
Returns:
| Column | Type | Description |
|---|---|---|
task_id | STRING | Task identifier for tracking via SHOW TASKS |
nodesWritten | INT | Number of nodes with properties written |
computeTimeMs | INT | Time spent computing the algorithm (milliseconds) |
writeTimeMs | INT | Time spent writing properties to storage (milliseconds) |
GQLCALL algo.lpa.write({}, { db: { property: "comm_id" } }) YIELD task_id, nodesWritten, computeTimeMs, writeTimeMs