What Caused Performance Issues When Filtering Node Properties During Path Queries
February 21, 2024
Jason Zhang
Director of Engineering
Ultipa Inc.
I met performance issue for this request:
"n({@comment && year(Date)==2012}).e().n({@person}) as p return p{*} limit 100"
It only contains a simple year filtering with property "Date" already loaded to engine.
What led to the performance issue?
Many users face issues when searching for paths with a large number of start nodes. The initial start nodes of an n().e().n() path-finding query include all the nodes whose schemas are specified in the first node filter n(). When no schema is set, the initial start nodes are all the nodes in the graph.
In this particular case, our customer has over 2 million nodes under schema comment. When the query is executed, Ultipa performs a full-schema scan to locate these start nodes and then calls function year() for each start node before initiating this path-finding query.
When such a large amount of data are loaded from disk to compute for paths, it will certainly take a considerable amount of time:
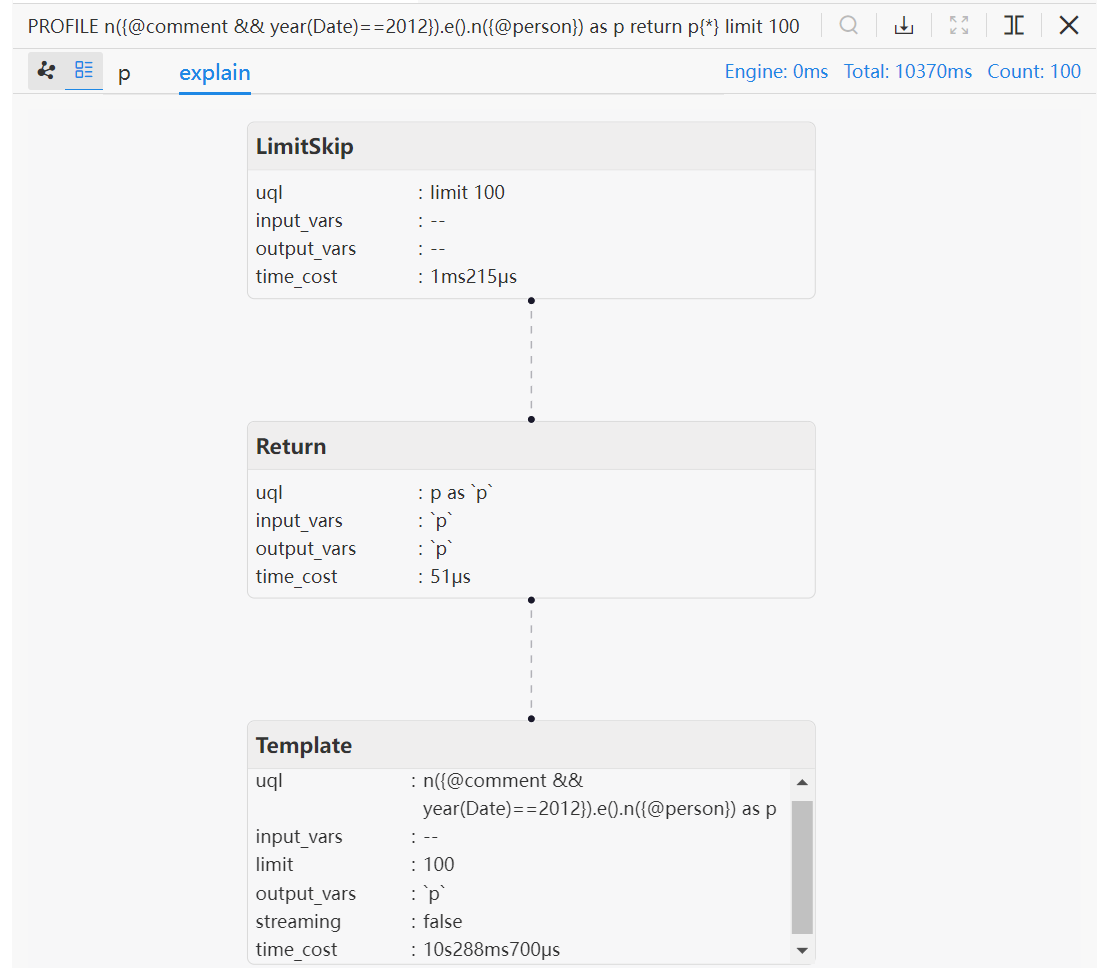
Total cost of the original query: 10.37 seconds
Procedure of performance tuning
Step 1: Moving the start node filter to find-node clause
Filtering nodes in a find-node clause has a different processing logic than filtering start nodes in a path-finding query. Simply put, moving the node filter to a separate find-node clause can reduce unnecessary computations and enables a smaller amount of data to initiate the path-finding query, instead of initiating from all the start nodes:
find().nodes({@comment && year(Date) == 2012}) as start
n(start).e().n({@person}) as p
return p{*} limit 100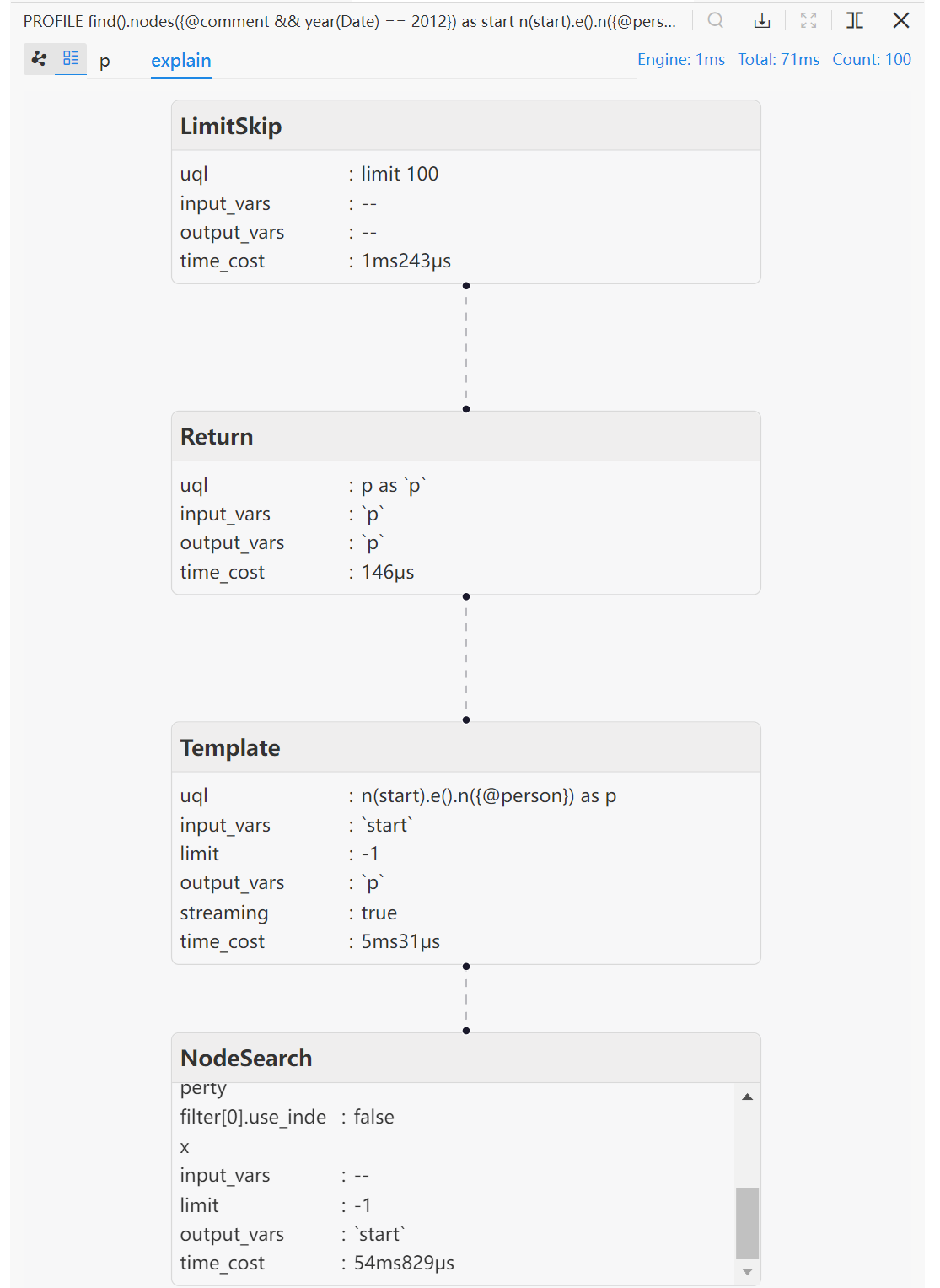
Total cost when filtering start nodes in find-node: 71 milliseconds
Step 2: Using range comparison to replace year() function
When filtering all the start nodes whose Date is in year 2012, calling function year() that leads a full-schema computation will induce extra time cost in contrast to just using comparison operators such as ==, <> or <=>. The performance difference is impressive when the amount of start nodes is huge:
find().nodes({@comment && Date <=> ["2012-01-01","2012-12-31 23:59"]}) as start
n(start).e().n({@person}) as p
return p{*} limit 100
Total cost after removing function year(): 9 milliseconds
Step 3: Create the right index instead of loading to Engine (LTE)
LTE is often thought of as the best way to speed up query performance, but that’s not accurate.
LTE is designed to provide high-performance path-finding by minimizing the I/O of disk when searching for each subsequential node and edge from the start node. The filtering of the start node itself in path-finding or in a find-node or find-edge clause, on the other hand, is not closely related to disk I/O and in which case an index tree is the right thing to be created in the disk:
//it may cost seconds
create().node_index(@comment.Date);
find().nodes({@comment && Date <=> ["2012-01-01","2012-12-31 23:59"]}) as start
n(start).e().n({@person}) as p
return p{*} limit 100;
Total cost when using disk index: 6 milliseconds
Please read UQL Accelerations for more details.
Conclusion
The above steps of optimization demonstrate how the efficiency of a path-finding query is gradually improved, the total execution time drops down from a few seconds to a couple of milliseconds. We can see that a transcendence occurs in NodeSearch (find-node) in each step, the key of which is understanding the query mechanism of Ultipa graph computing engine.
Table of performance efficiency comparison of different optimizations
| Original Path-finding | Step 1 (Node-finding) | Step 2 (Remove year()) | Step 3 (Use index) | |
| Cost of Template | 10s288ms700us | 5ms31us | 4ms281us | 4ms444us |
| Cost of NodeSearch | NA | 54ms829us | 3ms668us | 661us |
| Total cost | 10.37s | 71ms | 9ms | 6ms |