Scalably Effective Graph System Architecture
July 6, 2023
Jamie Chen
Senior Graph Developer
Ultipa Inc.
Ricky Sun
Founder & CEO
Ultipa Inc.
(This article is abstracted from paper Designing Highly Scalable Graph Database Systems without Exponential Performance Degradation - Understanding Distributed Native Graph Processing that has been included in ACM Digital Library.)
The main challenge faced by today’s graph database systems is sacrificing performance (computation) for scalability (storage). Such systems probably can store a large amount of data across many instances but can’t offer adequate graph-computing power to deeply penetrate dynamic graph dataset in real time. A seemingly simple and intuitive graph query like K-hop traversal or finding all shortest paths may lead to deep traversal of large amount of graph data, which tends to cause a typical BSP (Bulky Synchronous Processing) system to exchange heavily amongst its distributed instances, therefore causing significant latencies.
A major drawback with many distributed graph systems is that they were not designed to handle real-world graph datasets which are often either densely populated (i.e., financial transactions) with hotspot vertices, or insanely large which demands partitioning (or sharding) to go horizontally scalable, but not sacrificing exponential performance drop. We call this kind of distributed graph systems are scalably ineffective.
How to make a graph system that is scalably effective? To figure this out, we need to know the evolutionary pathway from a standalone (graph database) instance to a fully distributed and horizontally scalable cluster of graph database instances (See Figure 1).
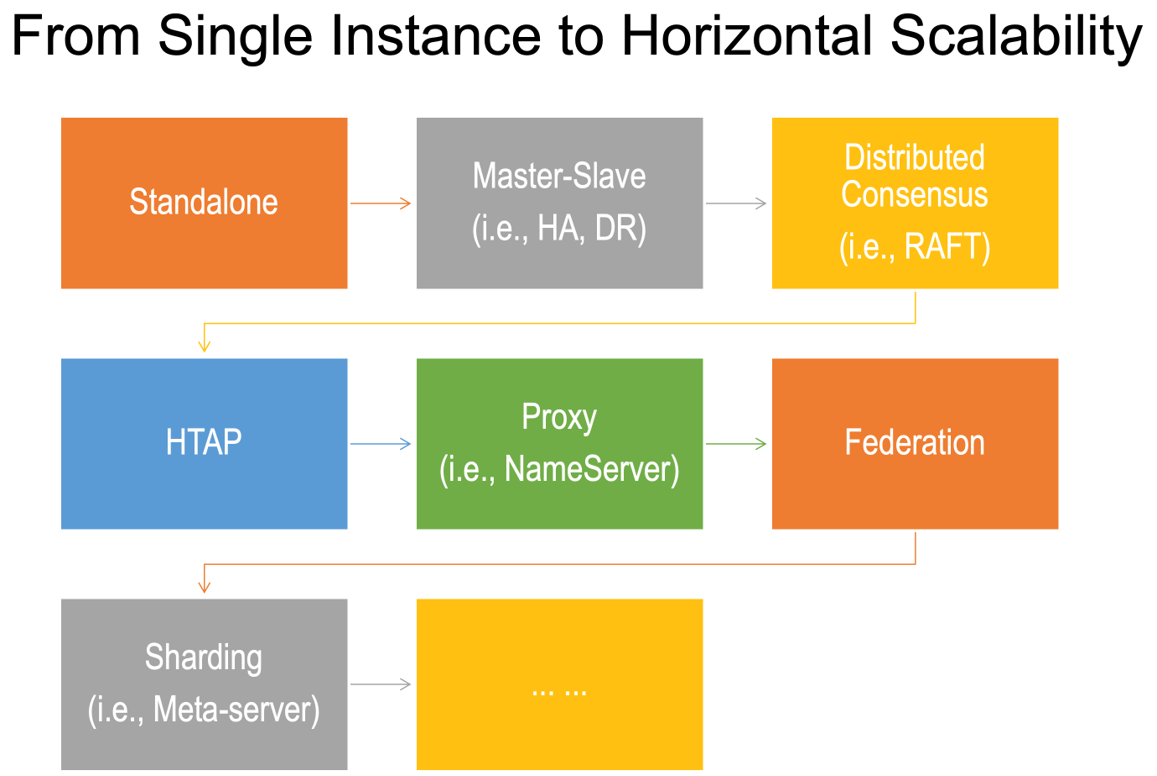
Figure 1: Evolution of Distributed (Graph) Systems
We proposes three schools of architectural designs for distributed and horizontally scalable graph database while achieving highly performant graph data processing capabilities.
1. Distributed Consensus & HTAP Architecture
The first school is setup as distributed consensus cluster where typically 3 instances form a graph database cluster. The reason to have 3 or an odd number of instances in the same cluster is because it’s easy to vote for a leader of the cluster. For instance, Neo4j’s Enterprise Edition v4.x supports the original RAFT protocol with only 1 instance handles workload, while the other 2 instances passively synchronizing data from the primary instance.
A more practical way to handle workload is to augment the RAFT protocol to allow all instances to work in a load-balanced way, for instance, having the leader instance to handle read-and-write operations, while the other instances can at least handle read type of queries to ensure data consistencies across the entire cluster.
A more sophisticated way is HTAP (Hybrid Transactional and Analytical Processing) with varied roles assigned to the cluster instances, the leader handles TP operations as well as AP operations , while the followers handles various AP operations (graph algorithms, path queries, etc.). What’s illustrated below (Figure 2) is a novel HTAP architecture from Ultipa:
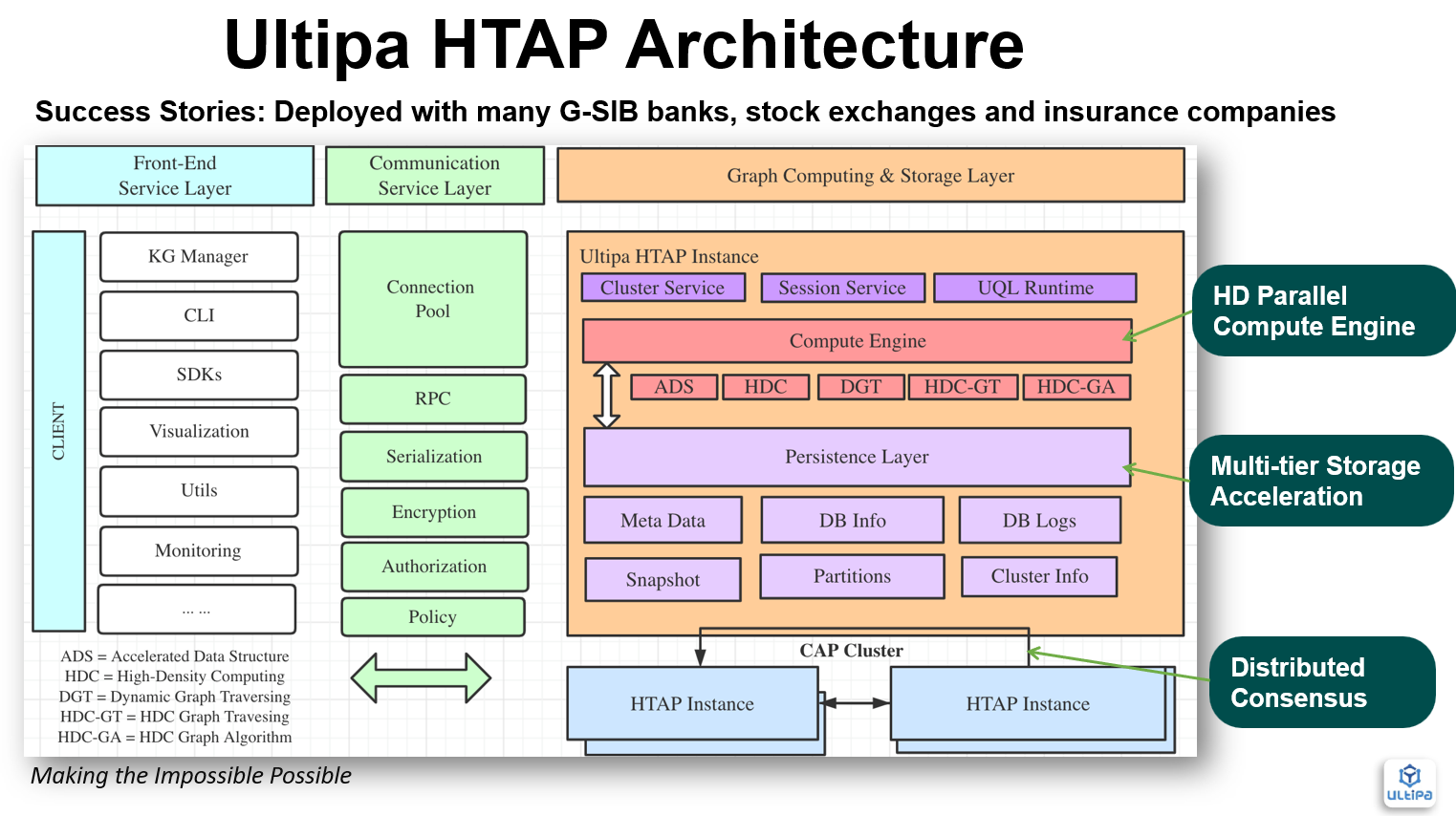
Figure 2: HTAP Architecture by Ultipa Graph
The pros and cons of distributed consensus include:
- Small hardware footprint (cheaper)
- Great data consistency (easier to implement)
- Best performance on sophisticated and deep queries
- Limited scalability (relying more on vertical scalability)
2. Grid Architecture
The key difference between the second school and the first school lies with the nameserver(s) functioning as a proxy between client side and server side. The nameserver is for routing queries and forwarding data. On top of this, except for running graph algorithm, the nameserver has the capacity to aggregate data from the underpinning instances. Proxied queries can be run against multiple underpinning instances (query-federation).
Note that the second school is different from third school in one area: data is artificially (just route GQL requests and then simply merge their results.) partitioned, such as per time series (horizontal partitioning) or per business logics (vertical partitioning).
Assuming you have 12 months’ worth of credit card transactions, in artificial partition mode, you naturally divide the network of data into 12 graphsets, one graphset with one-month worth of transactions stored on one cluster of 3 instances. This logic is predefined by the database admin in a vertex-centric way, ignoring potential connectivity between the graphset data. It's business (logics) friendly, without slow data migration, and has good query performance as HTAP.
In Figure 3, a grid architecture is illustrated, the 2 extra components added on top of Figure 2’s HTAP architecture are name-server(s) and meta-server(s). Essentially all queries are proxied through the name-server, and the name-sever works jointly with the meta-server to ensure the elasticity of the grid, the server clusters instances are largely the same as the original HTAP architecture.
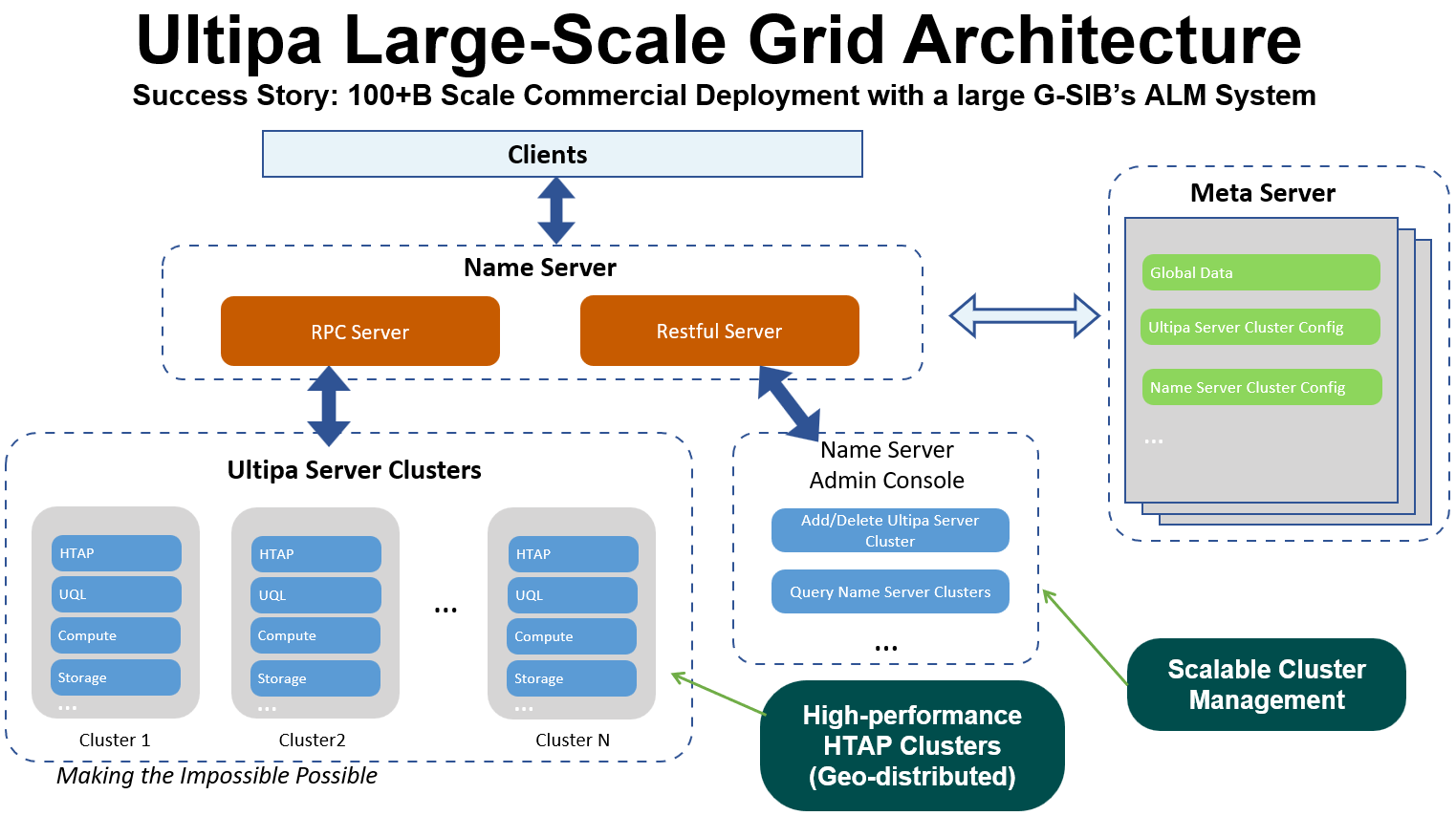
Figure 3: Grid Architecture w/ Name Server & Meta Server
Need to mention that for graph algorithms, however, the performance of the second school is poor (due to data migration, just like how map-reduce works).
The pros and cons of the grid architecture design can be summarized as:
- All pros and benefits of HTAP architecture are retained.
- Scalability is achieved with performance intact.
- Vertex-centric [5] partitioning with DBA/admin intervention.
- Most business logics are performed on distributed server clusters first before interim results sent to the nameserver for simple merge & aggregation before returning to the clients.
- Business logics required to work with graph partitioning and querying.
3. Shard Architecture
On the surface, the horizontal scalability of a shard architecture also leverages name-server and meta-server as in the second school of design, but the main difference lies with name-servers do NOT have knowledge about business logics (as in second school) directly. Indirectly, it can roughly judge the category of business logics via automatic statistics collection.
The ultimate goal of the third school is that data are processed on shard-servers and name-servers (peer-to-peer architecture). It is optimized using the principle of minimum I/O cost in terms of data migration, where small amount of data flows to where large amount of data is located. It aims to perform queries as much as possible on the shards (instead of name-servers).
Figure 4 shows the architecture of an optimized shard design. Note that in this peer-to-peer architecture, both the shard servers and name servers have computing capacities (while the shard servers contain the partitioned storage).
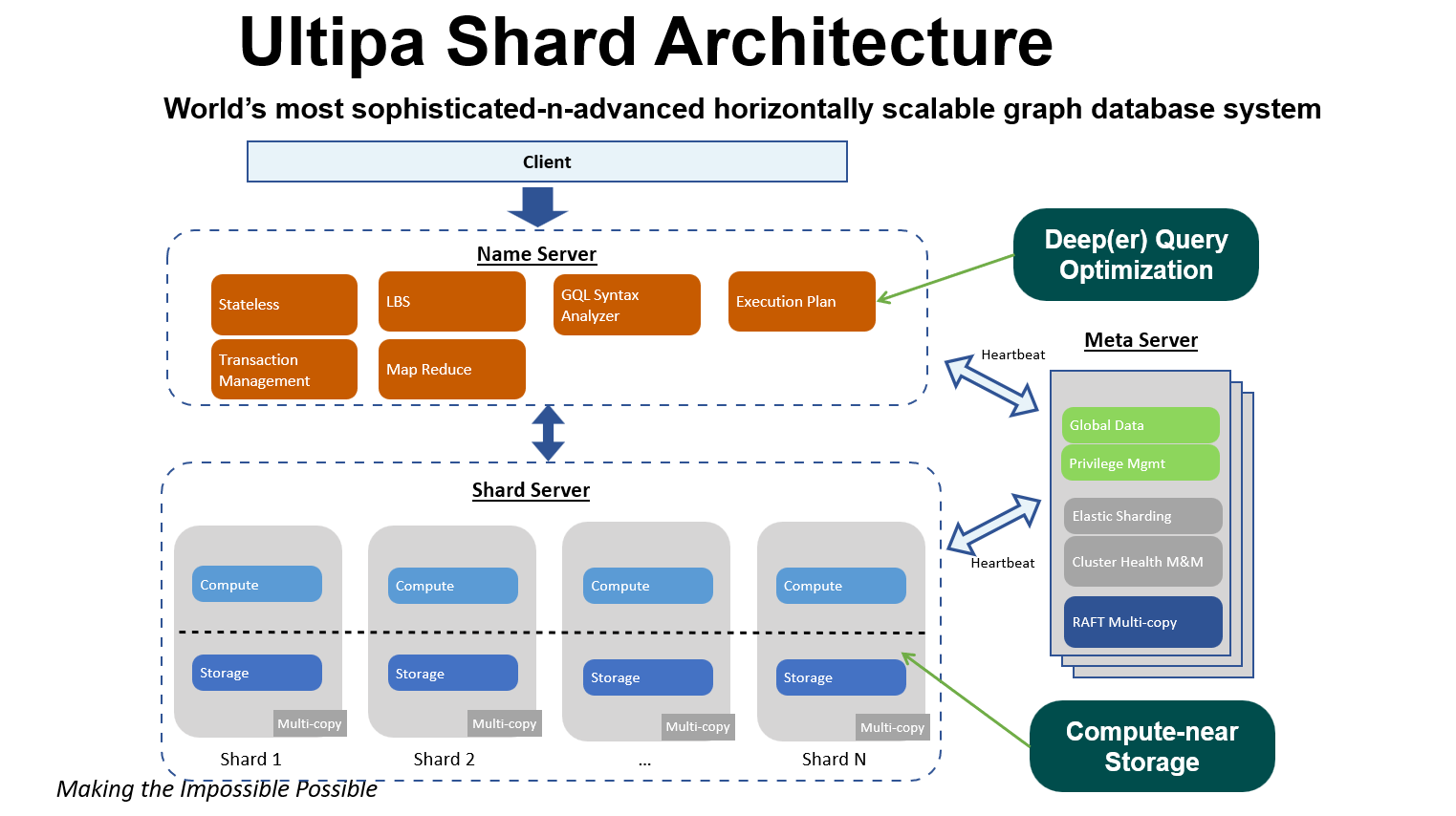
Figure 4: Shard Architecture w/ Name Server & Meta Server
Sharding on graph data can be a Pandora box, and here is why:
- Multiple shards will increase I/O performance, particularly data ingestion speed
- But multiple shards will significantly increase the turnaround time of any graph query that
- spans across the shards, such as path queries, K-hop queries, and most graph algorithms (the latency increase can be exponential!)
- Graph query planning and optimization can be extremely sophisticated, most systems today have done very shallowly. Deep query optimization on-the-fly is pivotal
Application Scenarios
Different scenarios can be optimized specifically to achieve satisfactory performance when designing scalable graph database systems for real-world commercial scenarios. There is no one-size-fits-all. Below table classifies 3 types of distributed graph systems given specific requirements like online/offline, read/write, and query range.
Table: Three schools of Distributed Graph Systems
|
Type |
Characteristics |
Business Scenarios |
|
High Density Parallel Graph Computing (HDPC) |
· Real-time read/write data, online processing & calculation · Ideal for deep range queries |
· Transaction interception · Anti-fraud · Anomaly detection · Real-time recommendation · AI/ML Augmentation · Other real-time scenarios |
|
HDPC & Shard |
· Separation of read/write operations · Elastic compute nodes for shard/offline data |
· Knowledge Graph · LLM Augmentation · Indicator calculation · Audit · Cloud Data Center |
|
Shard |
· Meta-data oriented · Shallow neighborhood calculation (1-2 hop) only |
· Archive · Data Warehouse |
It’s hard to say one architecture is absolutely superior to another, given cost, subjective-preference, design philosophy, business logics, complexity-tolerance, serviceability and many other factors – it would be prudent to conclude that the direction of graph architecture evolution for the long term clearly is to go from the first school to the second school and eventually to the third school, but most customer scenarios can be satisfied with the first two schools, and human-intelligence (DBA intervention) still makes sense in helping achieving an equilibrium of performance and scalability, particularly in the second and third school of designs.
(Read the original paper for more information.)