Demi-Schema: The Secret of UQL
July 10, 2023
As demonstrated in a previsou article The Specific Evolution of Query Languages that the graph database is inherently high-dimensional, and the operations on the graph are also recursive, it is easy to take for granted that the query language of a graph database should also be naturally good at finding association relationships (such as breadth first or depth first path search). In fact, the achievement of this goal depends on many factors, among which the pattern of data plays a crucial role. Let's first compare several graph query languages based on different graph data patterns:
- Cypher (Neo4j): Labels and properties can be defined at any time. However, due to the fact that labels are only a type of special indexes and have no corresponding relationship with properties, this design, although flexible, is low on both performance and storage space utilization, and is not suitable for handling large-scale calculations.
- GSQL (Tiger Graph): As a true 'category' of metadata, a schema is mapped with its own properties. This design requires the schema and its corresponding properties to be pre-defined before being used. In addition, the learning cost of Tiger Graph's GSQL is obviously high.
- UQL (Ultipa): Demi-Schema allows for large-scale processing and precise query filtering through a pre-defined pattern, while allowing for computations without specifying a schema.
Below figure (Figure-1) first illustrates a path describing 'a chef named Areith', and then lists the query statements of Cypher, Gremlin, UQL and GSQL that each implements the query of this path. The efficiency of these statements in writing and reading indirectly reflects the query efficiency of the corresponding Graph databases:

Figure-1: A comparison between Cypher, Gremlin, UQL and GSQL
Things that can be benefited from this demi-schema pattern employed by Ultipa are categorized under both 'schema' and 'schema-free':
Features of schema:
- All features of a schema graph: Inherits all characteristics of a schema graph
- Explicit data types: Defines different types of metadata with specific property combinations based on different business needs, liberates the management and development process
- Efficient serialization and deserialization: Greatly improves the efficiency of converting data from serialized storage to the data structure being used by the query language, and vice versa
- Intuitive graph modeling: Ultipa Manager provides a schema-based graph modelling user interface, allowing a vivid graph model preview, design and adjustment
- Boosted filtering and computing: Ensures an improved efficiency of disk index filtering and computing engine operation
- Full algorithm support: Supports operations over metadata of specified schemas from setting parameters to writing back or returning algorithm results
Features of demi-schema:
- All features of a schema-free graph: Inherits all characteristics of a schema-free graph and meanwhile applys optimizations
- Cross-schema operations: Supports batch creation, deletion, and other operations for all schemas in one statement
- Implicit filtering: Supports query either with or without schema specified
- Implicit conversion: Supports calling uniformly properties with the same name but from different schemas
- Multi-schema visualization: Supports and optimizes query results with metadata from different schemas, to better assist development and business personnel
- Full algorithm support: Supports operations over metadata of any schema from setting parameters to writing back or returning algorithm results
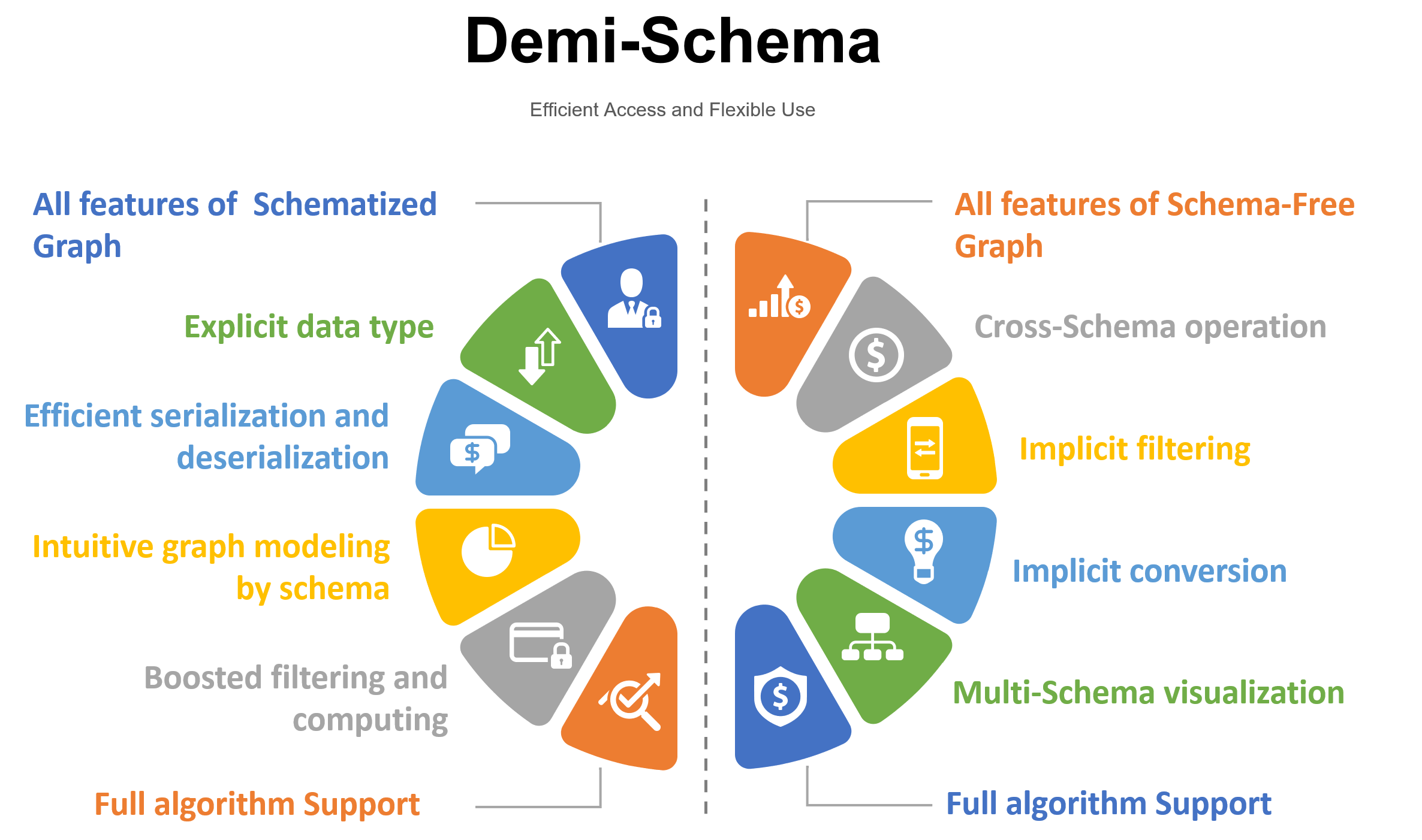
Figure-2: The advantages of Demi-Schema