Graph Chatbot - Leveraging Ultipa, Langchian, LLM, and Chroma Vector DB with Python
December 28, 2023
Jason Zhang
Director of Engineering
Ultipa Inc.

The Gap from Relevant to Precise
Utilizing vector DB and embedding technology enables us to efficiently identify the most relevant content in response to a user's query. However, a significant challenge arises in pinpointing the precise related answers within this framework. For instance, when presented with three distinct contents — an image file (ultipa-logo.jpg); information about Ultipa, the company offering graph solutions; and details about Ultipa's partner named SP — traditional Question and Answer (QA) systems often struggle to address queries like "What is the logo of SP's partner?" or "How does SP formulate graph solutions?"
Conventional QA systems encounter limitations when faced with multi-format data scattered across various sources, hindering their ability to uncover answers hidden within the interconnectedness of diverse data relationships.
A Solution to More Context with Graphs
This post aims to showcase the strategic integration of OpenAI, LangChain, Chroma Vector DB and Ultipa for the optimal performance of a QA System, referred to as Ultipa GraphBot. In this approach, we leverage Ultipa Graph to gather knowledge from pathfinding queries and node properties, answering questions by delving deep into the available data.
Preparations
To set up the essential components, install the packages of scikit-learn, Ultipa, LangChain, and OpenAI.
pip install scikit-learn ultipa langchain openaiImport Demo Dataset: Import the dataset into Ultipa Graph using Ultipa Transporter. Configure the server and graphset information, and specify the node/edge schemas and properties in the import.yml file.

CSV and YML files used for importing the dataset
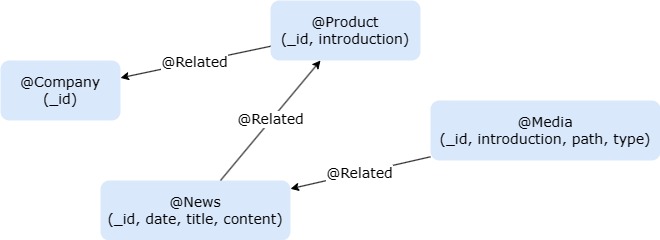
Graph model of the dataset
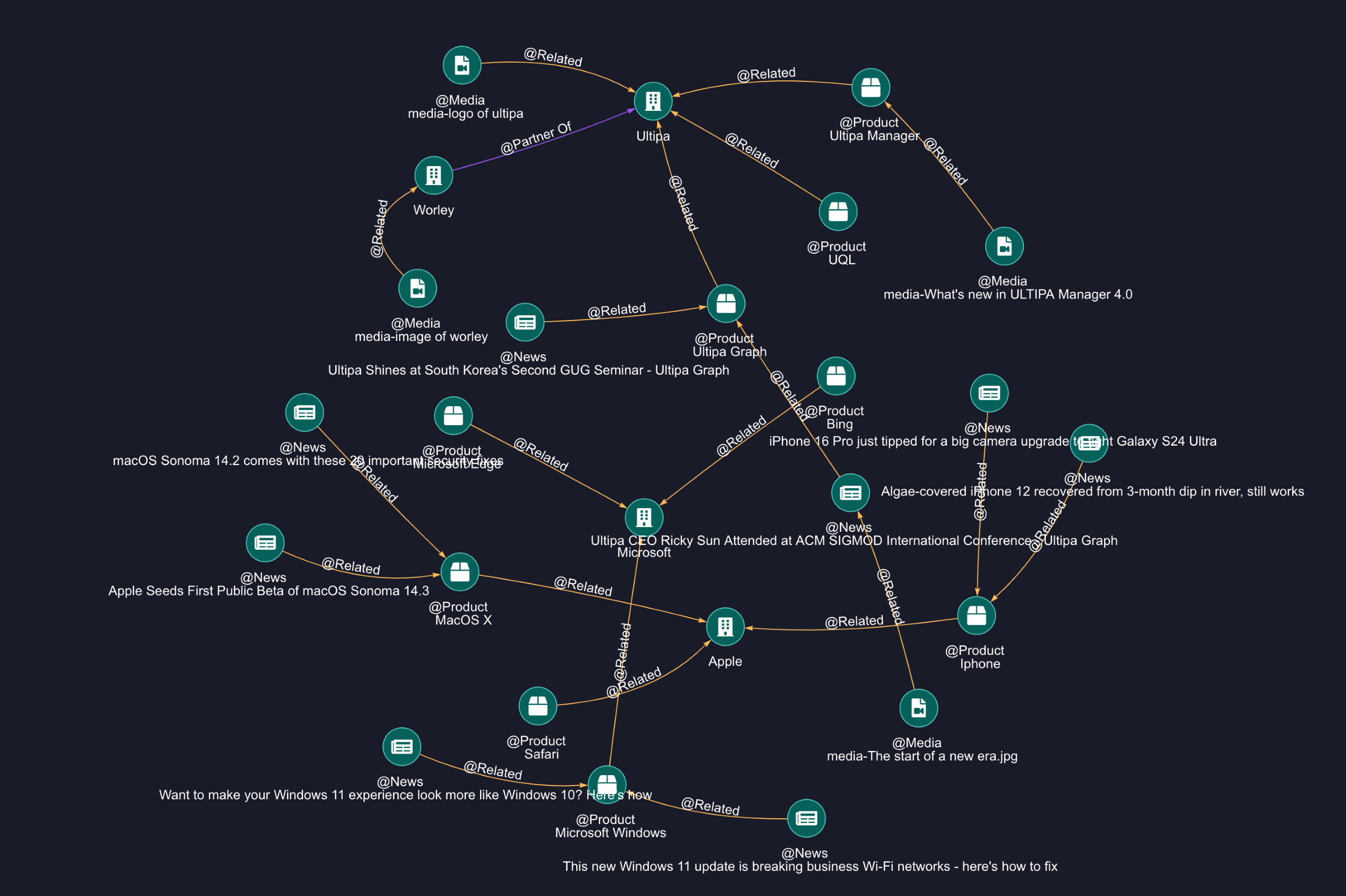
Overview of the imported graph
Connect to Ultipa Graph via Python SDK: Connect to Ultipa Graph via Python SDK, and create a new property called "embedding" for all nodes.
import os
Utilizing Ultipa-Transporter to Import all demo data
# Create the connection to Ultipa
from ultipa import Connection, UltipaConfig
from ultipa.types import ULTIPA
from ultipa import structs, ULTIPA_REQUEST
from ultipa.structs.Path import Path
ultipaConfig = UltipaConfig()
ultipaConfig.hosts = [os.getenv("HOST")]
ultipaConfig.username = os.getenv("USER")
ultipaConfig.password = os.getenv("PASS")
ultipaConfig.defaultGraph = os.getenv("GRAPH")
ultipaConfig.heartbeat = 0 # disable heartbeat
conn = Connection.NewConnection(defaultConfig=ultipaConfig)
conn.test().Print()
# Create the property embedding for all nodes
conn.uql("create().node_property(@*,'embedding',float[],'vectors')")Configure OpenAI and others: To proceed, you need an OPENAI_API_KEY for this. If you don't have one, follow the steps outlined here to apply for one.
Import the necessary libraries:
from typing import List
from IPython.display import display, clear_output
from IPython.display import HTML
# Initialize OpenAI
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
from openai import OpenAI
client = OpenAI()
# Import all dependence
from sklearn.metrics.pairwise import cosine_similarity
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParserOur primary task is to extract valuable context from graph data, including node properties (e.g., news content) as well as relations and paths, and then pass it to the Large Language Model (LLM) to generate answer for the question.
The extracted context will be stored in two variables:
1. FinalGraphContext: To store the relations and paths
2. FinalDetailContext: To store the detail of node properties
# The target is to find the most related content from the graph structure and node properties
FinalGraphContext: List[str] = []
FinalDetailContext: List[str] = []Generate Node Vectors
The OpenAI text-embedding-ada-002 model enables us to convert any text into a set of high-dimensional vectors. These vectors serve as representations for the nodes and facilitate computing similarities later on.
For this purpose, we establish three functions:
1. Embed: The function dedicated to embedding text into vectors.
2. UpdateEmbedding: The function for updating the vector of one node.
3. UpdateAllNodesEmbeddings: The function for updating the vectors of all nodes. This function should be called only once.
# Get str embedding from OpenAI, you can also use LangChain do the same thing
def Embed(str:str):
res = client.embeddings.create(
model="text-embedding-ada-002",
input=str,
encoding_format="float"
)
return [float(x) for x in res.data[0].embedding]
# Update the embedding of node with an id
def UpdateEmbedding(id: str, vectors: List[float]):
uql = "update().nodes({{ _id == `{}` }}).set({{ embedding: {} }})".format(id, vectors)
return conn.uql(uql)
# Update the embeddings of all nodes
def UpdateAllNodesEmbeddings():
res = conn.uql("find().nodes() return nodes{*} limit 100")
for node in res.alias("nodes").asNodes():
content = node.getID()
content += {
"News": node.get("content") or "",
"Media": node.get("path") or "",
"Product": node.get("introduction") or ""
}.get(node.getSchema(), "")
# Display(content, node.getSchema())
vectors = Embed(content)
res = UpdateEmbedding(node.getID(), vectors)
if res.status.code != ULTIPA.Code.SUCCESS:
res.Print()
else:
clear_output()
display("finished embed: " + node.getID())Find Similar Nodes for the Question
Option 1 - Ultipa: When a user poses a question, we can apply the same text-to-vector embedding technique to convert the question into a vector. Subsequently, we compare the question vector with the node vectors in Ultipa to identify the most similar nodes.
# Calc the most similar nodes for the question, you can also use a vector DB to do the same thing
def FindSimilarNodes(question="", min=0.8)->List[dict]:
res = conn.uql("find().nodes({}) return nodes{*} limit 100")
embed2 = Embed(question)
results = []
for node in res.alias("nodes").asNodes():
embeddings = []
embeddings.append(embed2)
embeddings.append(node.get("embedding"))
res = cosine_similarity(embeddings)
results.append({
"id": node.getID(),
"similarity": res.min()
})
results = [x for x in results if x.get("similarity") > min]
return resultsOption 2 - Vector DB: To identify similar nodes, leveraging vector databases proves instrumental. VectorDB provides a range of services customized for AI operations, facilitating the storage of vectors, documents, metadata, and more. Harnessing the capabilities of both Graph Databases and VectorDB ushers in a new era in QA systems.
In this example, we will use chromaDB, an open-source vector database.
# Use data via a Vector DB - ChromaDB for example
import chromadb
# Create a temporary db
vDB = chromadb.Client()
# Get or create collection to store vector and ids
try:
vDB.delete_collection("graph-qa")
except:
pass
vCollection = vDB.get_or_create_collection(name="graph-qa")
def UpdateVectorDB():
res = conn.uql("n(as nodes) return nodes{_id, embedding}")
nodes = res.alias("nodes").asNodes()
for node in nodes:
exist = vCollection.get(ids=node.getID())
if exist.get("embeddings") is None:
vCollection.add(
ids=[node.getID()],
embeddings=[node.get("embedding")]
)
def FindSimilarNodesFromVectorDB(question = "") -> List[dict]:
results = vCollection.query(query_embeddings=[Embed(question)], n_results=3)
ids = results.get("ids")[0]
resp = conn.uql("n({_id in ["%s"]} as nodes) return nodes{*}" % '","'.join(ids))
return [{"id": n.getID()} for n in resp.alias("nodes").asNodes()]Pathfinding Queries
Once the most similar nodes have been identified, we can proceed to execute path queries to discover in-depth information that may aid in answering the posed question.
To retrieve the graph data, we'll utilize the autonet and path template queries.
# Make the path string
def MakePathStrings(paths: List[Path]) -> (List[str], List[List[str]]):
strs = []
pathNodes:List[List[str]] = []
for path in paths:
pathString: List[str] = []
nodes = path.getNodes()
edges = path.getEdges()
for index, node in enumerate(nodes):
if(index > 0):
edge = edges[index - 1]
if edge.to_id != node.getID():
pathString += [" <- ", edge.getSchema(), " - "]
else:
pathString += [" - ", edge.getSchema(), " -> "]
nodeStr = node.getID()
if nodeStr.startswith(("media-")):
nodeStr = nodeStr.replace("media-", "(%s)" % node.get("type"))
pathString.append(nodeStr)
strs.append(" ".join(pathString))
pathNodes.append([ node.getID() for node in path.getNodes()])
return (strs, pathNodes)
# Find relations and paths by the autonet and template queries
def FindRelationsAndPaths(starts: List[dict])->(List[str], List[List[str]]):
res = conn.uql("""autonet().src({_id in %s}).depth(2).shortest() as paths return paths{*}""" % ([x.get("id") or "" for x in starts]))
paths = res.alias("paths").asPaths()
contextAutoNet, ids1 = MakePathStrings(paths)
res = conn.uql("""n({_id in %s} as start).e()[:3].n() as paths return paths{*} limit 10""" % ([x.get("id") or "" for x in starts]))
paths = res.alias("paths").asPaths()
contextPathFinding, ids2 = MakePathStrings(paths)
context = contextAutoNet + contextPathFinding
PathIds = ids1 + ids2
return (context, PathIds)Path Filtering
The paths discovered by the FindRelationsAndPaths() function might contain ambiguous or unclear data. To refine, we employ the LLM to identify the most useful paths.
This time we use LangChain instead of OpenAI API, as the former offers prompt templates, model creation, result output, and more functionalities.
def LLMFindRelatedGraphInfo(question="", pathContext: List[str] = [], pathIDs = []) -> List[str]:
prompt = ChatPromptTemplate.from_template("Recommend up to 10 paths related to the question or containing words related to the question, -- PATHS --
{context}
-- END --
Question: {question}
path indices split by `,`:")
model = ChatOpenAI(model = "gpt-4")
output_parser = StrOutputParser()
chain = prompt | model | output_parser
res = chain.invoke({
"context": "
".join(pathContext),
"question": question
})
nodeIDs = set()
print("pathIDs", res, pathIDs)
for i in res.split(","):
index = int(i.strip()) -1
nodeIDs = nodeIDs.union(pathIDs[index])
FinalGraphContext.append(pathContext[index])
return nodeIDsIn this code snippet, we've assigned all the useful relations and paths to FinalGraphContext variable!
More Context from the Graph
We believe that relying solely on these paths is still insufficient. To provide a richer context for the LLM, we want to extract additional information from the properties of each schema. Specifically, our focus is on finding the image path and news content. This can be achieved through a node query with an _id filter.
def FindDetailContext(nodeIDs) -> (List[str],List[str]):
uql = "find().nodes({_id in %s}) return nodes{*}" % list(nodeIDs)
print(uql)
res = conn.uql(uql)
details = []
medias = []
for node in res.alias("nodes").asNodes():
if node.getSchema() == "News":
details.append("--- (Knowledge) %s ---
%s
--- Article END ---
" % (node.getID(), node.get("content")))
elif node.getSchema() == "Media":
details.append("--- (%s) ---
Name:[%s]
URL[%s]
--- Media END ---
" % (node.get("type"),node.getID(), node.get("path")))
medias += [node]
return (details, medias)This is where the FinalDetailContext variable is used.
Pass Context to LLM for the Answer!
To display the results, we will pass FinalGraphContext and FinalDetailContext to LLM and request it to return HTML for display.
# Answer question based on context
def LLMAnswer(question = "") -> str:
prompt = ChatPromptTemplate.from_template("Answer the question as an expert with comprehensive knowledge of the given context:
{context}
!!CONTEXT END!!
Question: {question}
Answer(Ensure the output is rich, including media and styles, in HTML format):")
model = ChatOpenAI(model = "gpt-4")
output_parser = StrOutputParser()
chain = prompt | model | output_parser
res = chain.invoke({
"context": "
".join(FinalGraphContext + FinalDetailContext),
"question": question
})
return resPut All Together
# Step 0, set embeddings/vectors to each nodes
# UpdateAllNodesEmbeddings()
# question = "what is the logo of SP's partner?"
# question = "What is the advantages about Ultipa?"
vectorDB = True
question = "How can SP build an architecture design for graph databases using Ultipa?"
if vectorDB == False:
# Step 1, find similar nodes by cosine similarity
display("FindSimilarNodes")
starts = FindSimilarNodes(question, 0.8)
else:
UpdateVectorDB()
# Step 1.1, find similar nodes by vectorDB chroma
display("Find Similar Nodes by VectorDB")
starts = FindSimilarNodesFromVectorDB(question=question)
# display(starts)
# Step 2, find relations entities
display("FindRelationsAndPaths")
PathContext, PathIDs = FindRelationsAndPaths(starts)
# display(PathContext)
# display(PathIDs)
# Step 3, ask LLM to filter the good infos
display("LLMFindRelatedGraphInfo")
nodeIDs = LLMFindRelatedGraphInfo(question=question, pathContext=PathContext, pathIDs= PathIDs)
# clear_output()
# display(nodeIDs)
# Step 4, find more details from the properties
display("FindDetailContext")
FinalDetailContext, medias = FindDetailContext(nodeIDs)
# Step 4, answer the question
display("LLMAnswer")
answer = LLMAnswer(question=question)
clear_output()
display("Question: %s" % question)
display("Answer:")
display(HTML("<style> .ultipa-answer {background: black; color: white; max-width: 600px; font-size: 14px; line-height:1.5;} img {max-width: 100px; } </style> <div class='ultipa-answer'>%s</div>" % answer))
#print("Related Path", PathContext)
#print("Detail Nodes", nodeIDs)
#print("Medias", [node.getID() for node in medias])
#print("Context", FinalGraphContext)
#print("Context", FinalDetailContext)Here are some screenshots of the testing results:
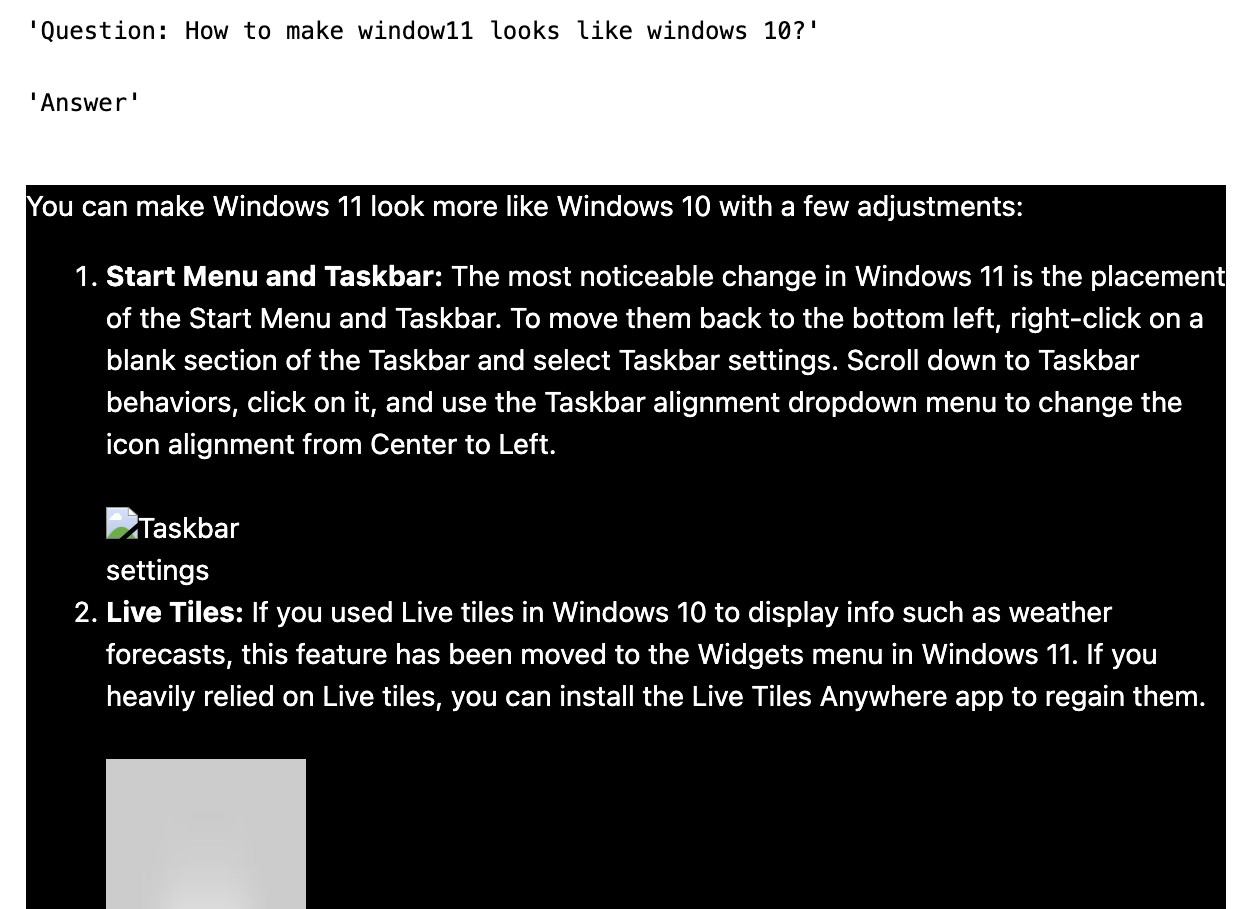
QA - 1
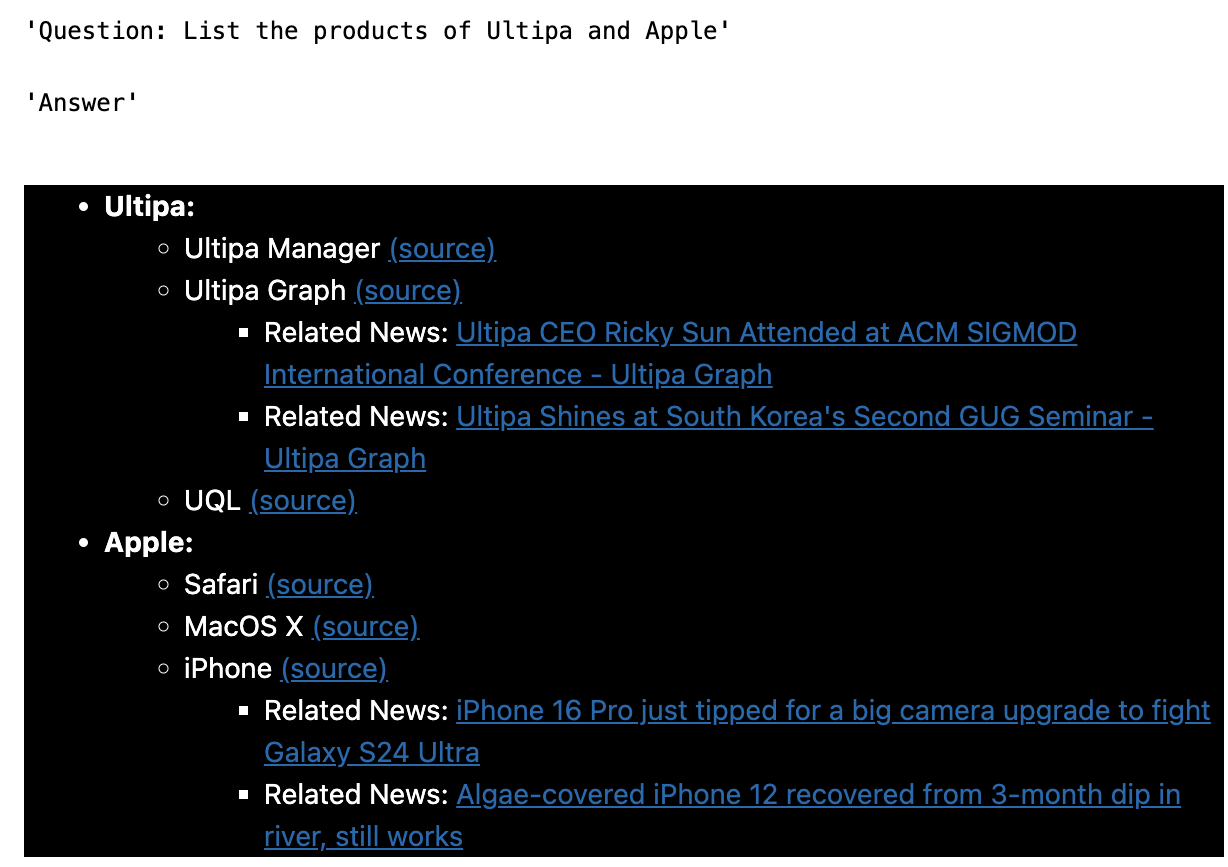
QA - 2

QA - 3
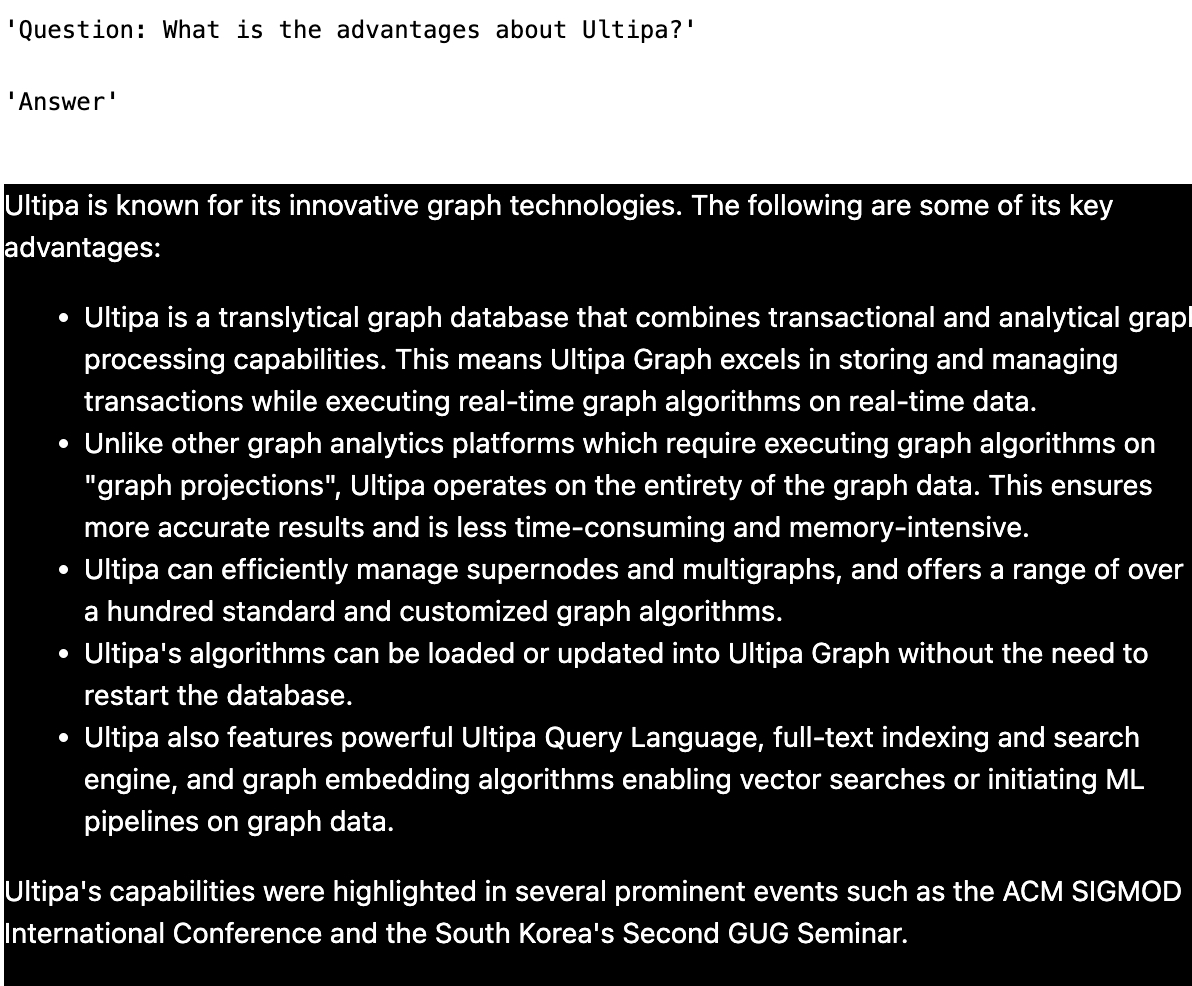
QA - 4
One More Thing
Ultipa Graphbot is now published as a widget available in Ultipa Manager.