Bloor InBrief – Ultipa (2023)
July 3, 2023
Daniel Howard
Senior Analyst
Bloor Research

The company
Ultipa is a relatively new graph database vendor. It was founded in 2019, and its flagship product (of the same name) was first commercialised in 2021. Despite this, the company has offices across Europe, Asia, and the United States, as well as a substantial customer base in (retail) banking.
What is it?
Ultipa is a highly performant property graph database. It has been designed and built from the ground up to provide deep search and analytic capabilities that operate in real time via an intuitive and easy to use query interface. This can be used to support the creation and use of knowledge graphs, to accelerate querying on big data sources (enhancing their visibility), and more. To wit, some Ultipa customers are currently using it to process hundreds of millions of transactions per day, in real-time. It is also translytic: it can be used for both transactional and analytical processing, as well as for HTAP (Hybrid Transactional/Analytical Processing).
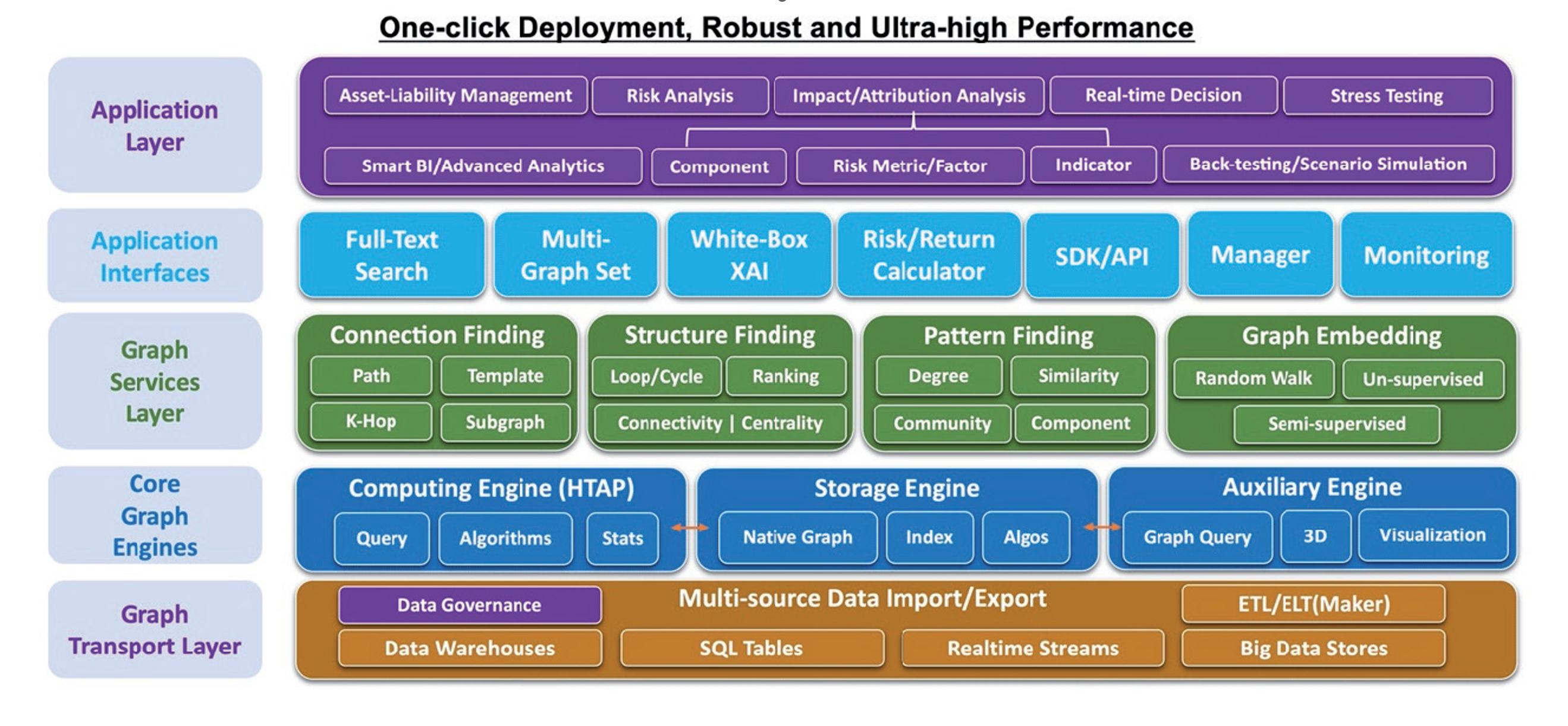
Figure 1- Ultipa graph system architecture
"With great efficiency and white-box interpretability, Ultipa’s solution has been playing a key role for us that no other vendor has ever managed to.” - China Merchants Bank
Moreover, Ultipa is particularly notable for – and puts particular emphasis on – its ability to support AI, and especially XAI (“eXplainable AI”). For instance, the degree of performance it provides can make a very significant difference to the amount of time it takes to generate your AI models, thus allowing you to act on the predictions they make much more quickly. What is more, by analysing and discovering key features of your network and communicating them to downstream AI and modelling applications, it can be used to drive model explainability and improve model accuracy.
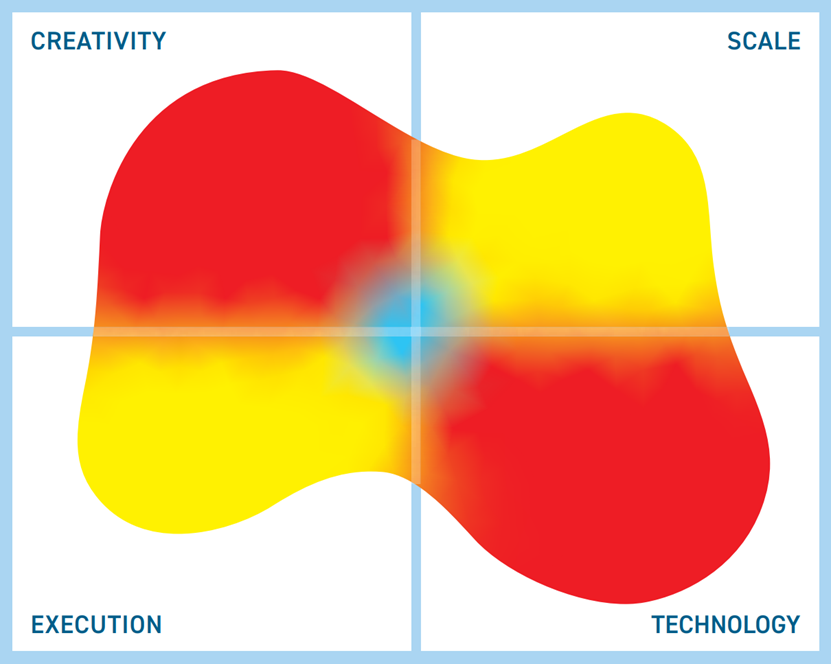
The image in this Mutable Quadrant is derived from 13 high level metrics, the more the image covers a section the better. Execution metrics relate to the company, Technology to the product, Creativity to both technical and business innovation and Scale covers the potential business and market impact.
What does it do?
Ultipa’s most significant differentiator is its performance, which (the company claims) outstrips or at the very least competes with all of the most popular and relevant graph databases in use today. This includes both open-source databases (which is frankly not very impressive) and proprietary offerings (which is). There are a number of factors that contribute to the performance Ultipa offers. For example, it leverages high-density parallel computing in order to maximise the power of every CPU core available. For another example, the product also uses multidimensional vector mechanisms to search in graphs, rather than something more primitive like a doublelinked list. One of the major benefits of this technique is that it is highly scalable: in fact, Ultipa boasts linear scalability. Together, along with various other optimisations, these qualities can result in improved concurrency and significantly reduced latency.
For a concrete example of what this performance does for you, consider the concept of a “supernode”. Supernodes are graph nodes that connect to an abnormally large (read: massive) number of other nodes, and therefore have a large number of edges connected to them. Many real-world systems are centralised around supernodes, and due to their nature supernodes tend to have a very substantial presence in whatever system they are found in.
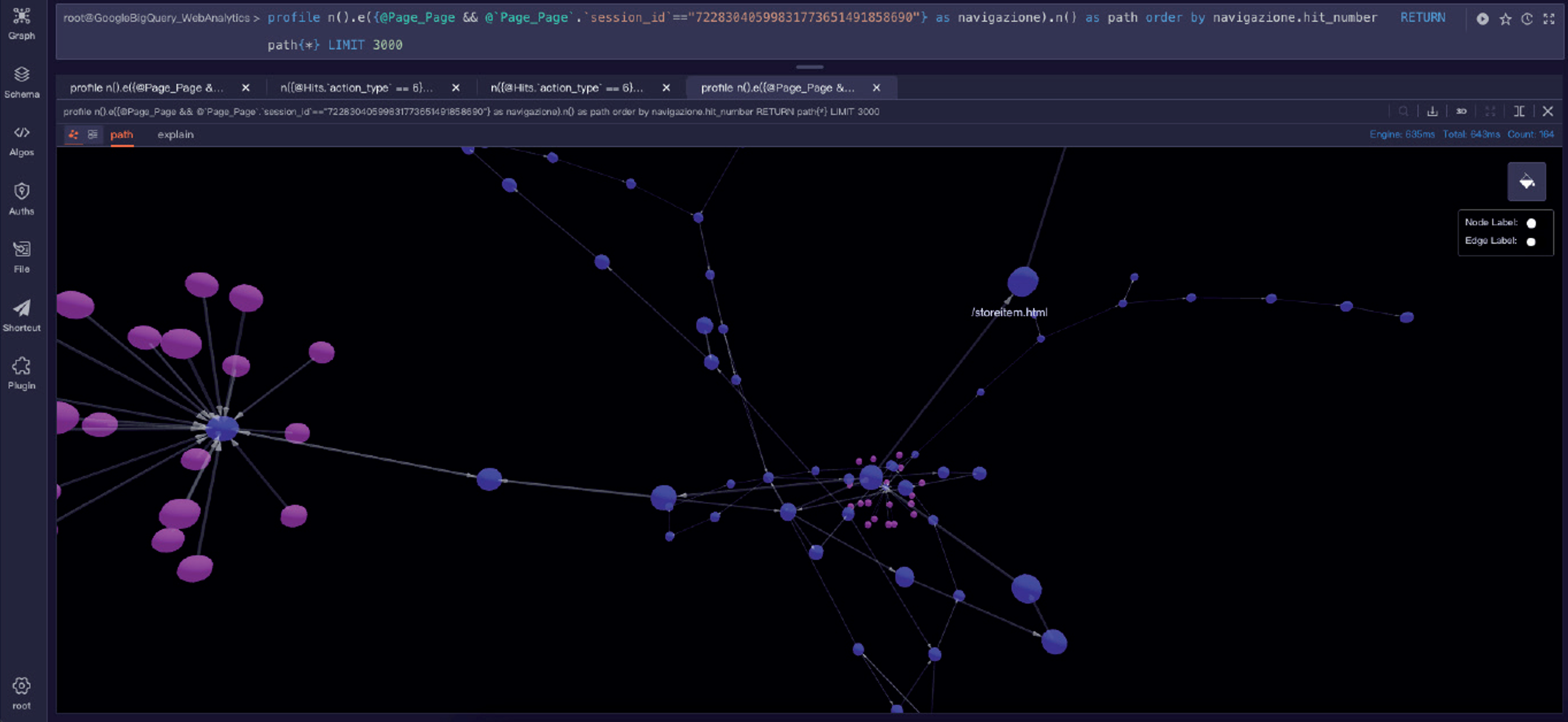
Figure 2 – 3D graph visualisation using Ultipa
In addition, Ultipa provides an extensible and hot-pluggable collection of semi-/unsupervised graph algorithms, as well as graph embedding algorithms that convert high-dimensional, sparse graphs into low-dimensional, dense, continuous vector spaces while preserving graph structure properties. Graph embeddings in particular can be very beneficial for performance, especially for machine learning-based applications such as link prediction and node classification. This makes Ultipa wellsuited for addressing such use cases.
The other major point about Ultipa is that it is easy to use. Although it provides a bespoke query language (which has the inherent problem of making it harder to onboard), the “Ultipa Query Language” (UQL) is genuinely simpler and easier to use than much of what else is available. The fact that it hews close to Cypher certainly helps matters, and there is even an adaptor for moving code from Cypher to UQL. GQL support is also provided via UQL. In addition, Ultipa provides easy multi-graph capabilities (which is to say, it supports multiple edges between nodes without intermediaries) and comes with a variety of graph algorithms built-in.
"Ultipa system on average is 20 to over 1,000 times faster [than Neo4j] – in one scenario, we tried to explore an enterprise’s investment network which is 32-layer deep, Neo4j takes 2-hour to penetrate, while Ultipa takes only 0.2 second.” - Shenzhen Stock Exchange
Finally, Ultipa is “demi-schematic”, meaning that it can be used both with and without a schema. All of this contributes to its ease of use.
Why should you care?
There are, fundamentally, two reasons to care about Ultipa: performance on the one hand, and ease of use on the other. It is very clear that these are the driving forces behind the product. That said, it is worth bearing in mind that high performance can improve query accuracy as well as speed, as it allows you to extract more information in less time, including details that might otherwise be impossible to extract in a manageable time frame.
The product’s application to AI use cases is an additional factor that may also be worth your consideration. We have already described several of the features that allow Ultipa to perform very competitively with its peers. This is only appropriate, as sheer speed and performance is Ultipa’s main selling point. But in this case, discussing the technology only goes so far: what’s important are the results. Luckily, the company provides some rather impressive benchmarks to this effect on its website, and although we generally feel it pays to be sceptical of these kinds of performance benchmarks, they are nevertheless impressive.
In terms of ease of use, the fact that Ultipa have positioned this as a major selling point is in itself a good sign: too many graph vendors do not seem to overly care how complex or difficult their chosen query language is, so Ultipa’s approach is, at the very least, refreshing. Opting for a bespoke query language is an interesting decision, because even granting that UQL is easier to use than Cypher, and is generally very similar to it, employing any sort of new language is going to be a hard sell if your users are already familiar with an alternative. That said, the aforementioned similarity to Cypher, as well as the provided Cypher-to-UQL accelerator, help matters significantly.
The Bottom Line
Ultipa is a new but promising addition to the graph space. Although the product is clearly still in its early years, the level of performance it purports to provide is both very impressive and, potentially, very beneficial.