
Graph database has traditionally been considered a sub-type of NoSQL database (in contrast to SQL-centric database, also known as relational database which has been the dominant type of database since the late 1980s and is still very popular amongst enterprise IT environment, large or small). Its core concept is based on Graph Theory that's best known for the Seven Bridges of Königsberg problem that's published by the world-renown mathematician Leonhard Euler in 1735-1736. Of course, Graph databases didn't start taking their shapes and forms until the recent 10 years and nearly about 40 years after the invention of the Internet, not to mention the appearance of the modern-sense computer.
A lot of Graph algorithms have been invented, from the very famous Dijkstra's algorithm (1956 - shortest path problem in graph) to PageRank that's invented by the co-founder of Google in the late 1990s, and to Louvain Modularity (detecting communities in a graph).
In a sense, a lot of today's greatest Internet companies are built on top of graph technologies, to name a few:
- Google: PageRank is a large-scale web-page (or URL if you will) ranking algorithm.
- Facebook: The core feature of Facebook is its Social Graph, and the last thing that it will ever open-source will be it. It's all about Friends-of-Friends-of-Friends, and if you have heard of the Six-Degree-of-Separation theory, yes, Facebook builds a huge network of friends, and for any two people to connect, the hop in between won't be exceeding 5 or 6.
- Twitter: Twitter is the American (or worldwide) edition of Chinese Weibo (and you can say the same thing that Weibo is the Chinese edition of Twitter), it ever open-sourced FlockDB in 2014, but soon abandoned it on Github. The reason is simple, though most of you open-source aficionados find it difficult to digest, that is, graph is the backbone of Twitter's core business, and open-source it simply makes no business sense!
- LinkedIn: LinkedIn is a professional social network, one of the core social features it provides is to recommend a professional that's either 2 or 3-hop away from you, and this is only made possible by powering the recommendation using a Graph engine (or database).
- Goldman Sachs: If you recall the last worldwide financial crisis in 2007-2008, Lehman Brothers went bankrupt, and the initial lead was Goldman Sachs withdrawing deals with Lehman Brothers. The reason for the withdrawal was that Goldman employs a powerful Graph DB system – SecDB, which was able to calculate and predict the imminent bubble burst.
- Paypal, eBay, and many other BFSI or eCommerce players: Graph computing is NOT uncommon to these tech-driven new era Internet companies – the core competency of graph is that it helps reveal correlations or connectivities that are NOT possible or too slow with regular relational databases or traditional big-data technologies, which were not designed to handle deep connections.
The modern concept of Graph was arguably (re)invented by the father of the Internet -- Tim Berners-Lee, who coined the concept of Semantic Web. He proposed that the Internet can be seen as a gigantic graph with all its URLs, each matching to a web page with contents embedded and linked inside of it, being the entities within the graph, and all the entities cross-referencing each other, therefore forming the web of WWW (World Wide Web). The Semantic Web concept was coined in the early 1990s, but the first industrial-grade Graph systems didn't come into realization until many years later. Initially, academic researchers created RDF specification (first edition in 2004, adopted by W3C in 1999, and v1.1 in 2014), which was originally data-modeling for metadata, and usually used within academic fields for knowledge management, the default query language for RDF is SPARQL. One thing about RDF is that it's heavy, it's verbose and it's difficult to maintain -- in short, developers don't like it. To draw a comparison, would you prefer XML or JSON? Probably JSON since it's simple, it's lightweight and it's fast, period.
The same holds true for the invention of LPG -- Labeled Property Graph, which didn't come into existence until 20 years after the invention of the Semantic Web, and it was populated by Neo4J, a Swedish-founded tech firm that has released the first LPG graph in 2011. A few other players have also invested in this area, to name a few: TitanDB (defunct since 2016), Apache TinkerPop, JanusGraph, Amazon Neptune, Baidu HugeGraph, Google's GraphD (and DGraph) ...
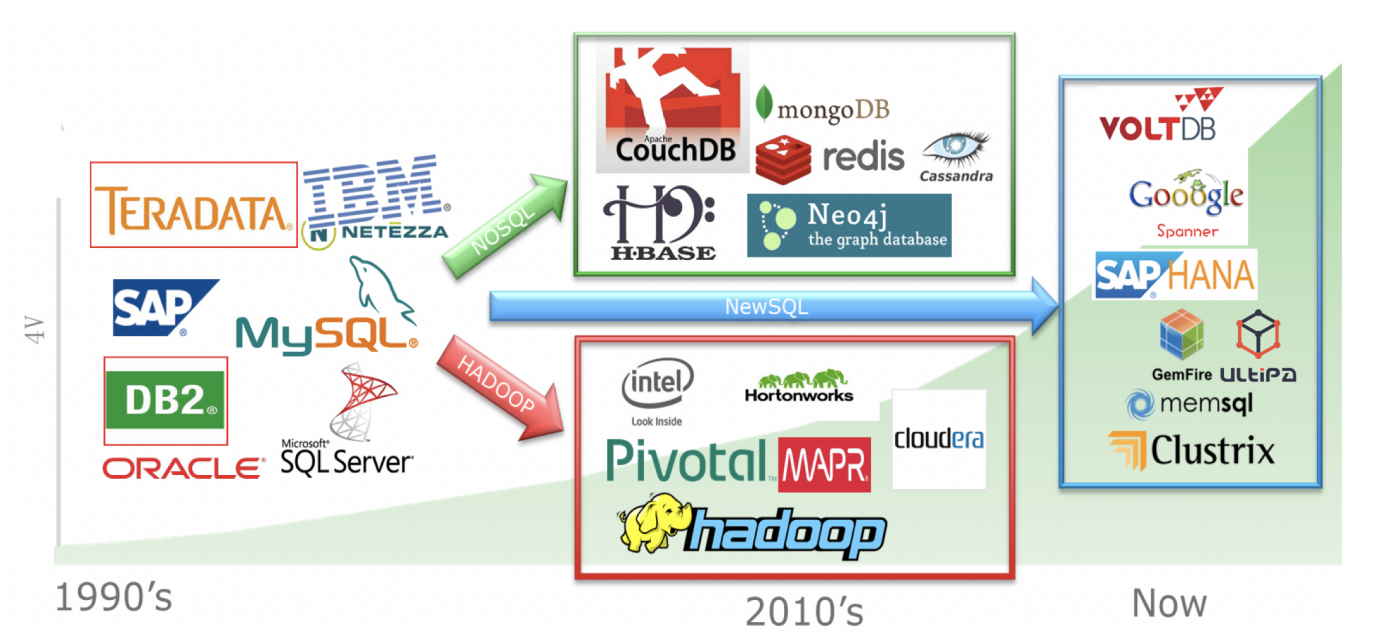
The Evolution of Data → Big Data → Fast Data → Deep Data
Graph database (or generally Graph system, Graph platform, Graph solution or Graph engine, these all refer to the same thing -- a system that's graph centric, works around a graph and computes within a graph...) is considered the crown-jewel of NoSQL, especially in the era of data connections, in the era of maximizing the value of large volume of data through deep and fast mining.
Graph is the ideal solution, if you also consider the timing factor, say, real-time restriction, it makes graph the only tangible solution. You can't otherwise achieve real-time deep data correlations with other types of NoSQL or relational databases. Key-Value Stores, Column databases, Hadoop or Sparks, Document databases are simply ill-equipped to handle the data correlation problems. It is this aforementioned problem and challenge that gives birth to and enables the speedy growth of Graph database market.
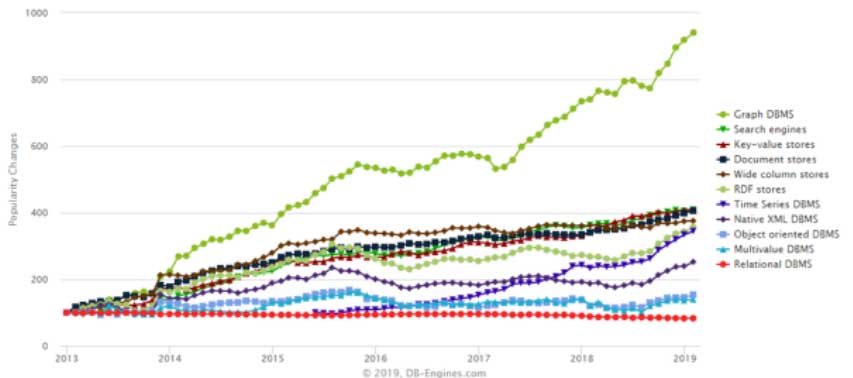
The Growth of Graph Is Much Faster Than Other Types of Databases
As you can see in the above chart, DB-Engines.com tracked all types of databases since 2013, and in the past 6 years (Q1 2013- Q1 2019), Graph database (the green dotted line) grows about 3-4 times faster than other types of data solutions like Search engines, KV stores, RDF stores or Relational DBMS. The Relational DB market basically is NOT growing at all and is speculated (most likely to happen) that in the next 10 years, more and more relational DBMS will be replaced by Graph database and other types of databases (some have predicted that 40-50% of SQL workload will be shifted over to Graph databases). And, industrial giants like Microsoft and Amazon predicted that Graph system's adoption rate by worldwide enterprises will grow 50-to-100 times in the next 8-to-10 years, which means that the number of enterprises using graph systems will grow from 5,000 to over 500,000 which is very significant.
The New Era of Connections
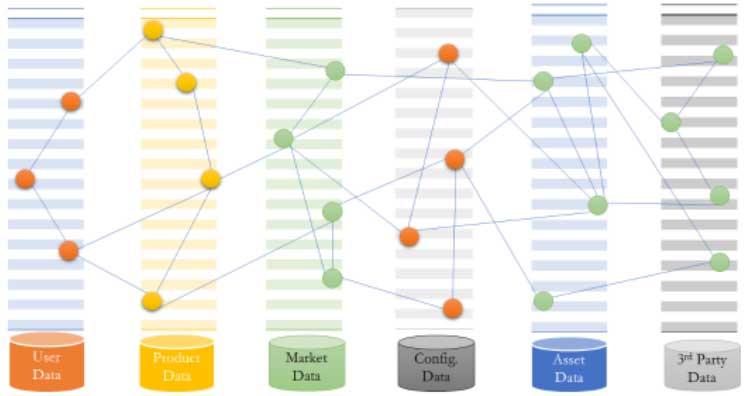
Network Analytics With Graph on Top of Other Types of Data Stores
If you ever wondered about the limitation of relational databases, now think this: with only relational DBMS, how would you figure out problems like:
- How do I find a person's friends of friends of friends?
- How do I find an account's relationship to a group of identified black-listed accounts?
- How do I know if any two accounts' behavior (transaction records) in a given time frame are normal or not?
- In a supply-chain network, if one factory/plant in South Africa is shut down, how would it affect a flagship store in South Korea?
- In a carrier network, if one network node is down (offline), what's the ripple effect (scope of impact)?
- In the healthcare business, if a customer submits his EMR and EHR, is there a way to offer real-time customized recommendations for major-disease insurance to him?
- In Anti-money-laundering scenarios, how do I know if an account holder has moved his money around via layers of intermediary accounts and eventually collected (laundered) his money back into his own account(s)?
- Today's search engine can only do 1-dimensional thinking, for instance, if you enter something like "Isaac Newton and Genghis Khan", none of today's search engines would return any meaningful, deep-thinking results.
The 8 questions raised above are only a small set of challenges that you would expect today's traditional DBMS (even NoSQLs) or search engines unable to address.
But with the help of a real-time Graph database and Graph computing engine, there is the possibility of having it serve as the backend data processing engine and find connections between data entities in real-time. For instance, based on an encyclopedic-scale knowledge base, the Ultipa graph engine can enable real-time pathfinding like below:
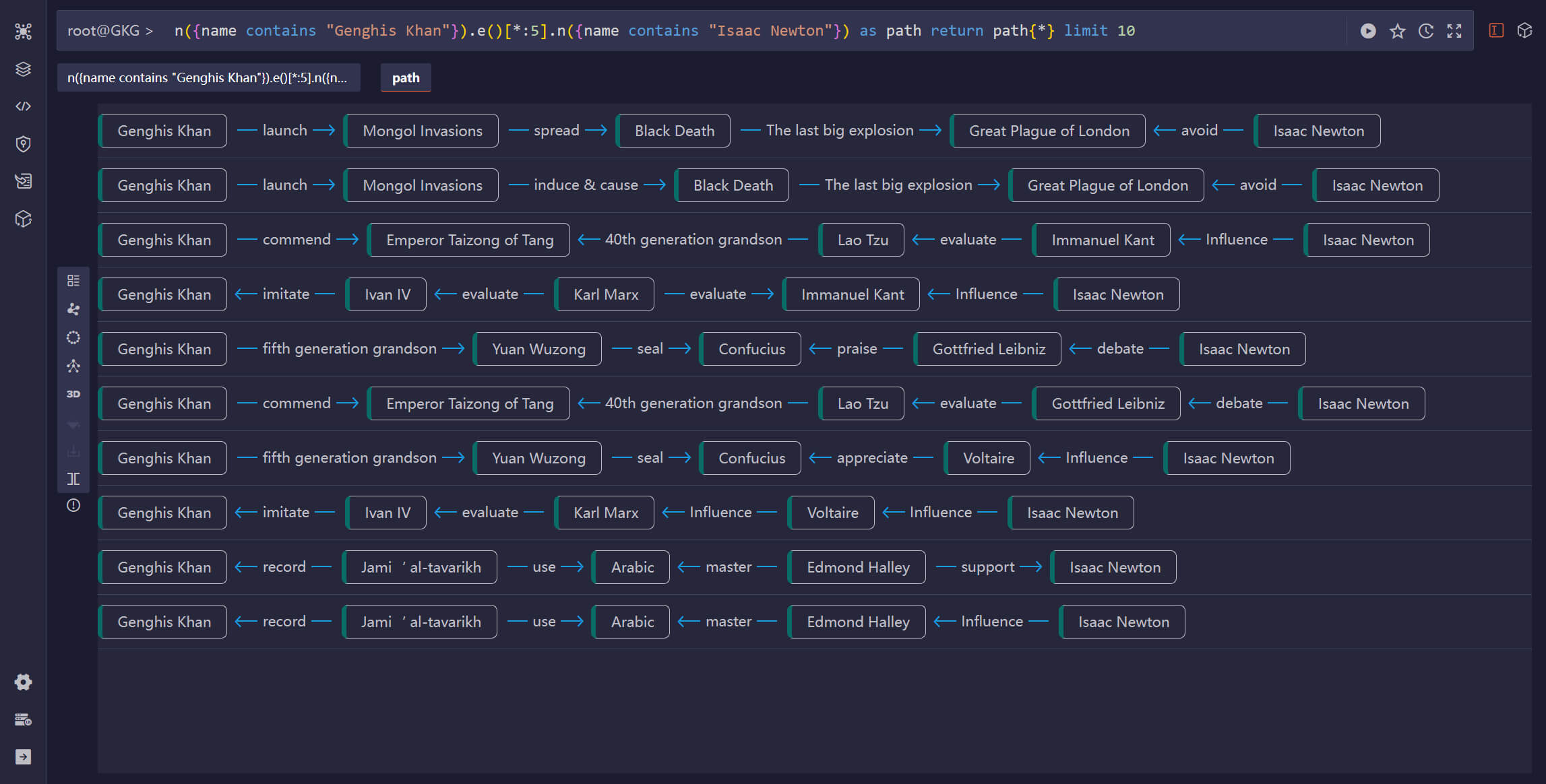
Real-Time Search for Shortest-Path Between Isaac Newton and Genghis Khan (List Mode)

Real-Time Search for Shortest-Path Between Isaac Newton and Genghis Khan (Graph Mode)
Unlike traditional Search engines, which tend to be silent and are not able to return anything meaningful when you are searching for ‘relationships’ (which you do in real life all the time), a search engine powered by a real-time Graph database can return the optimal, human-consumable-n-intelligent path. If you look at the paths carefully, one of which (highlighted as the bottom gray path in Graph Mode) reads as below:
- Genghis Khan started the Mongol Invasion of Europe (in the early 13th century).
- The Mongol Invasion of Europe caused the eventual outbreak of the Black Death.
- The last pandemic of the Black Death (in the 17th century) is called The Great Plague of London.
- Isaac Newton was attending the University of Cambridge, and he evaded the Great Plague by going home. (And he later invented Calculus, Optics, and Newton's Laws of Motion, ...)
These are all processed in real-time by the underpinning Graph database - Ultipa Graph, and the optimal path (not necessarily the shortest path though) is returned. If the user is interested in exploring further, he can tweak the search by filtering and adjusting, for instance, parameters (a.k.a. attributes) associated with the vertices (a.k.a. nodes) and edges.
Here is another example of real-time detection for anti-money laundering via data-flow tracking: the large red dot has been transferring money, via 10 layers of intermediaries, to the small red hot, the activities of which are hard to uncover unless you can dig more than 10-layer deep in the graph since the money flows do NOT converge at layers that are shallower than that.
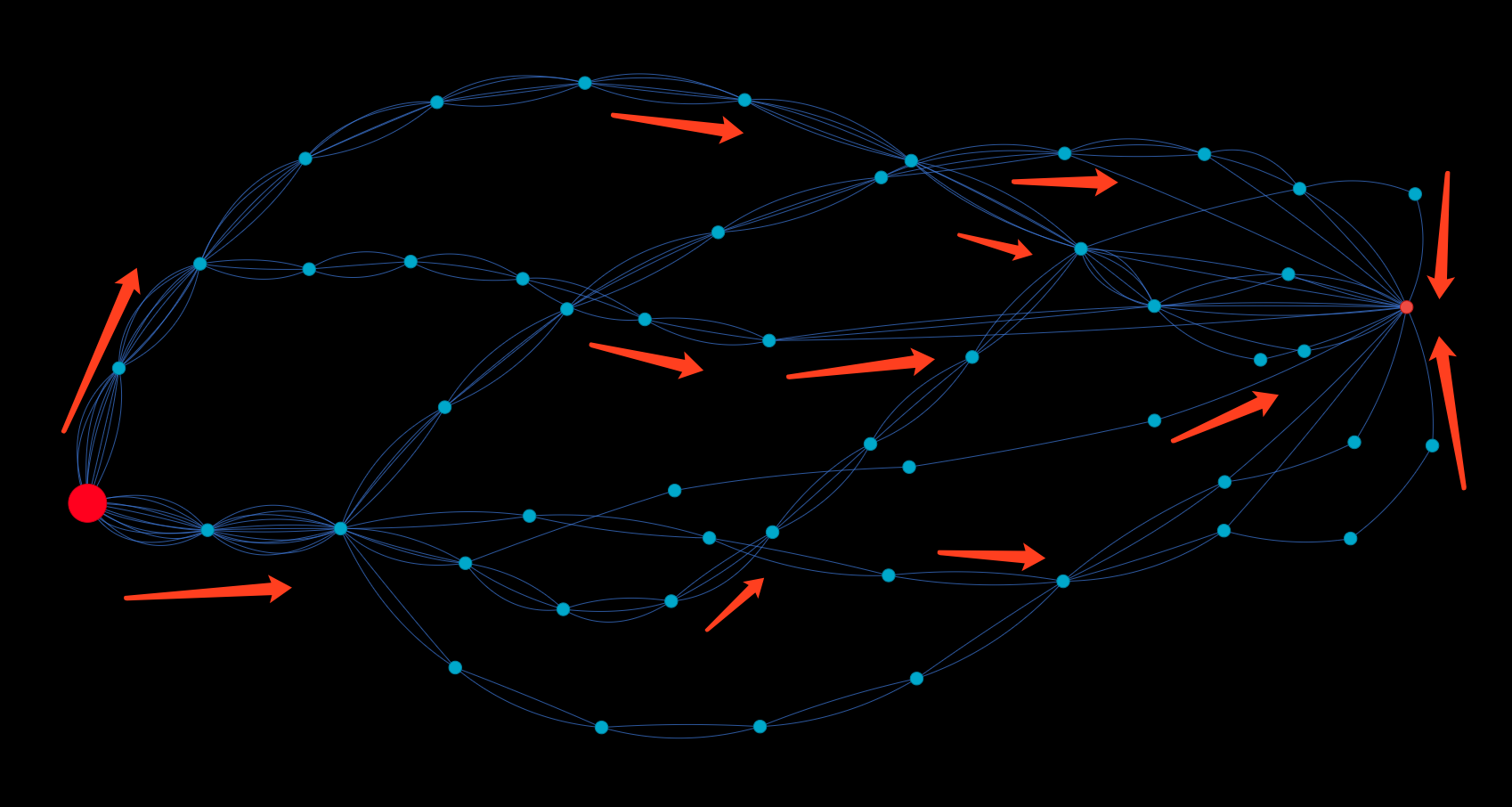
Real-Time Data (Money) Flow Tracking
The examples given above are both dramatic, futuristic (but realized), and meaningful. It shows you that the smart feature you might have dreamed of has been implemented in real-world applications. Dealing with anything like Butterfly Effect is a hard problem as it usually requires dealing with a large volume of data, not to mention dealing with it in real-time. As most of today's analytics are batch-process oriented and therefore are NOT real-time, we are now talking about turning OLAP into OLTP: what if a real-time Graph database can turn these OLAP tasks into OLTP, making things completely real-time? To further sweeten the pot, with no extra cost of ownership? You would want to adopt such technology, wouldn't you?
In 2017, Gartner Group proposed a 5-layered model of Data Analytics (see below diagram):
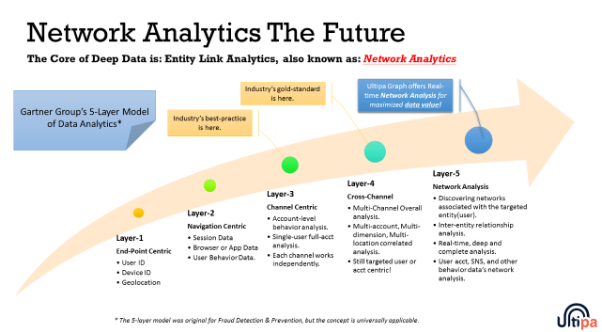
The 5-Layered Model by Gartner Group - Network Analytics Is the Future
In this diagram, the future of data analytics lies with 'Network Analytics', a.k.a Entity Link Analysis, which is only made possible with the help of Graph database -- the reason was previously explained in this document -- Graph system models data entities as a network and searches for connections among the network; it does so far more efficiently than relational DBMS, which would utilize join of tables and may take forever to complete such kind of tasks.
The advancement of data analytics is the natural progress of business needs, which drives the progress of data processing technologies; in Layer-1 to Layer-2, you can take that as standalone application and web application level data analytics; Layer-3 is Channel Centric data analytics that usually happens within the boundary of a channel within an enterprise; Layer-4 is Cross-Channel that requires organizations within a large enterprise to share data across the channel boundary; however, to maximize data value you would want to consolidate the data collected from varied resources and to look at them in a holistic way -- Network Analytics and Graph database is ideal for this task.
We hope the long introduction and background information provided in this document prepare you to enter the world of Ultipa Graph -- a 100% Real-time Graph Database that's far more powerful and user-friendly than any other competitor. It's hundreds of times, and even tens of thousands of times faster; it searches extremely deep; it leaves no hidden path unfound, and it offers the best cost-performance. In short, it costs little but offers far greater performance, and best of all, it enables business landscapes that are previously impossible with other players.