This page demonstrates several types of graph query on how they are composed in UQL and what does the query result look like in Ultipa Manager.
GraphSet used in this article:
- Graph model is as demonstrated by Chart1 in Prepare Graph
- Graph data can be downloaded from Data Import
For those who don't have an Ultipa server environment:
- Click the 'Run' button on top of each code box to check the query result
- Or 'Copy' the code and run it in Ultipa Playground against graph 'Quick Start'
Basic Queries
Node Query
Query for nodes is comparable to table query in relational databases. Try to understand below UQL:
find().nodes() as myFirstQuery
return myFirstQuery{*} limit 10
Its literal meaning is 'find nodes and name them as myFirstQuery, return myFirstQuery, limit 10 of them', which is close enough if added with some explanations:
- Chain statement
find().nodes()initiates a node query - Alias myFirstQuery defined for the result of this node query is called by a latter statement
return - Symbol
{*}following the node alias carries all the properties of node
The target of the above UQL is 'find 10 different nodes and return all their properties'. Execute this UQL in Ultipa Manager:
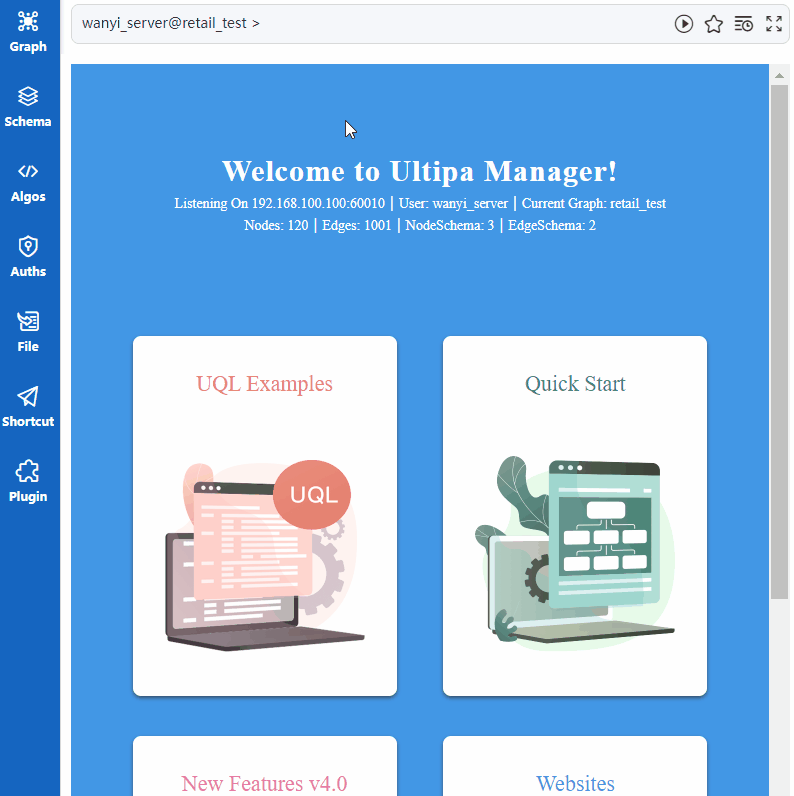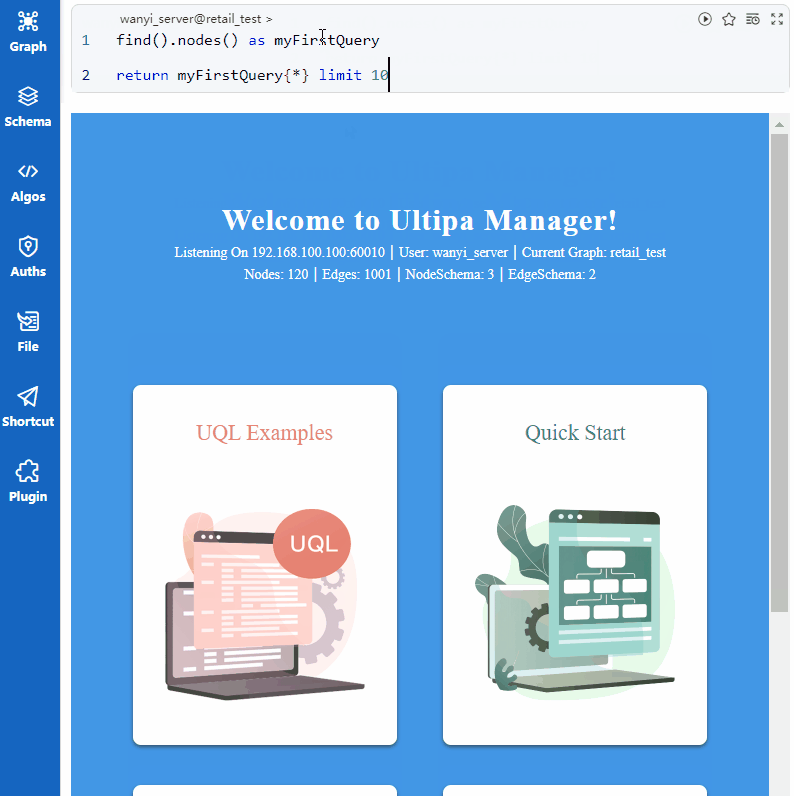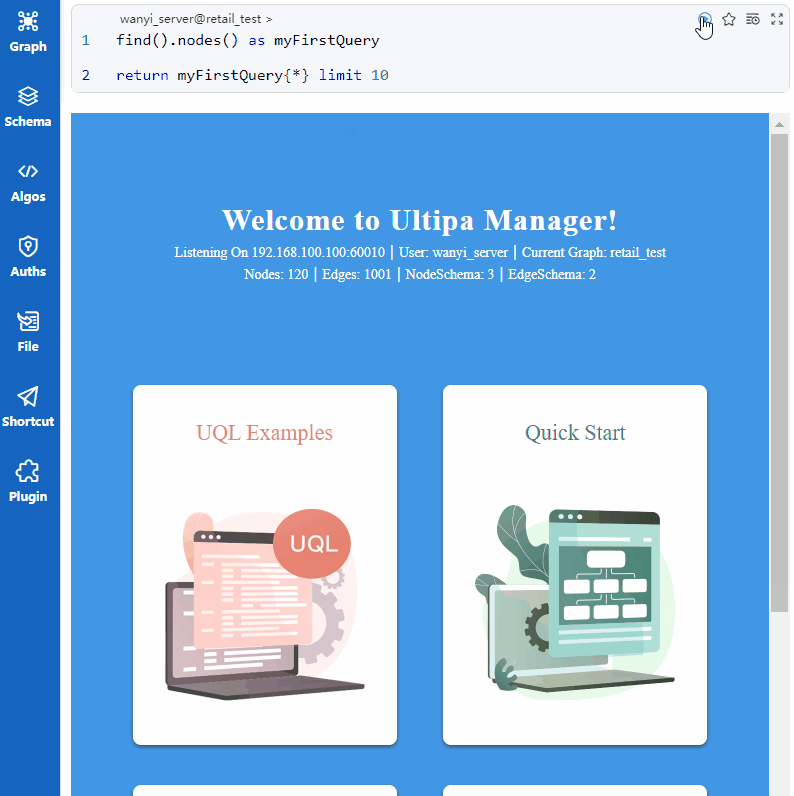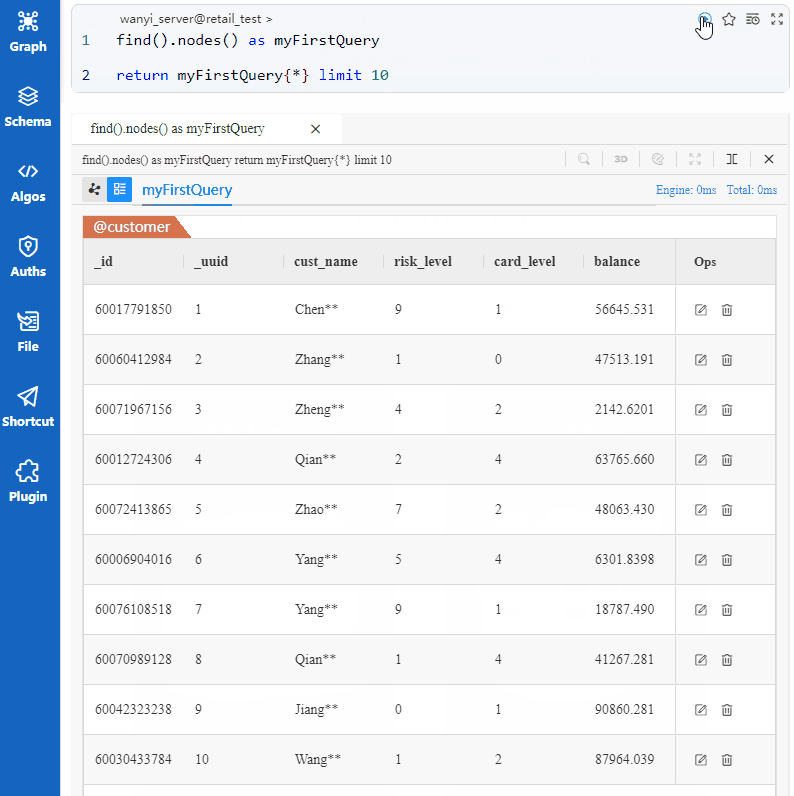
The fact that myFirstQuery are nodes all from schema
@customeris a coincidence, or more precisely, be subject to the sequence of inserting nodes and the behavior of concurrent computing.
To query nodes of a specific schema, merchant for example, describe in nodes() as below:
find().nodes({@merchant}) as mySecondQuery
return mySecondQuery{*} limit 10
- The curly braces
{}and its content held bynodes()(as well asn()and many other parameters, review Graph Data - Describe Nodes) is called filtering condition
Below is the execution result of this UQL:
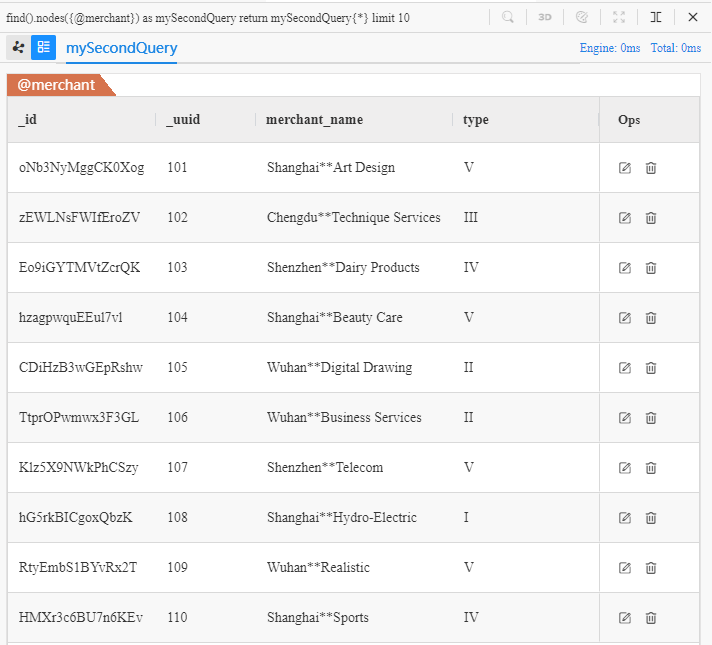
Edge Query
In the current graph model, edges of @transfer exist from nodes of @customer to nodes of @merchant:

Query for edges is quite similar to query for nodes, but using edges() to hold the filtering condition of edges:
find().edges({_from == "60017791850"}) as payment
return payment{*} limit 10
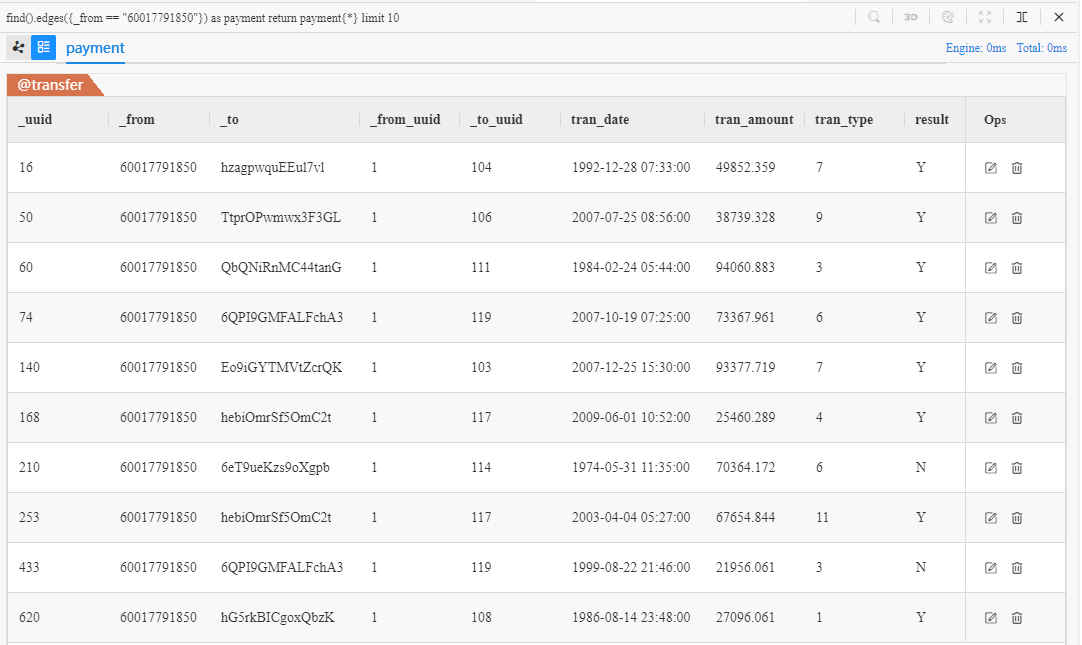
The payment are 10 different edges from customer Chen** (ID: 60017791850) to other nodes, the _to of payment are the IDs of merchants who receive those payments. Combine this edge query with a node query that calls the IDs of these merchants:
find().edges({_from == "60017791850"}) as payment
find().nodes({_id == payment._to}) as merchant
return merchant{*} limit 10
- The
._idfollowing the node alias calls the property_idof node
The above UQL returns all properties of those 10 merchants who receive transactions from Chen** (ID: 60017791850):
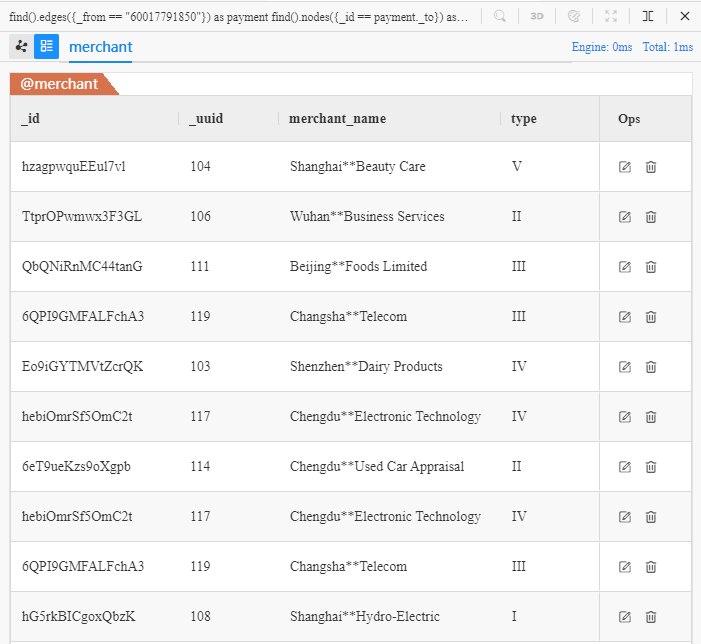
Repeated values occur in the result, which are merchants with
_uuid'117' and '119' that each appears twice, because they each receives two transactions from Chen**.
This is a typical scenario of multi-graph, in which more than one edge exist between two nodes. The 2D view in Ultipa Manager can better display this kind of scenario.
Spread
spread().src({_id == "60017791850"}).depth(1) as transaction
return transaction{*} limit 10
Its literal meaning: spread from a source whose ID is 60017791850, to a depth of 1, return all properties of 10 such records.
- Command
spread()initiates a query for edges starting from a center nodesrc(), in BFS manner - Parameter
depth()sets the greatest depth the BFS search goes - Alias transaction represents one-step paths of the found edges, namely the 'start-node, edge, end-node'
- Symbol
{*}following the path alias carries all the properties of nodes and edges in the path
The target of the above UQL is 'find 10 different edges from customer Chen** to merchants and return all properties of Chen**, edges and merchants':
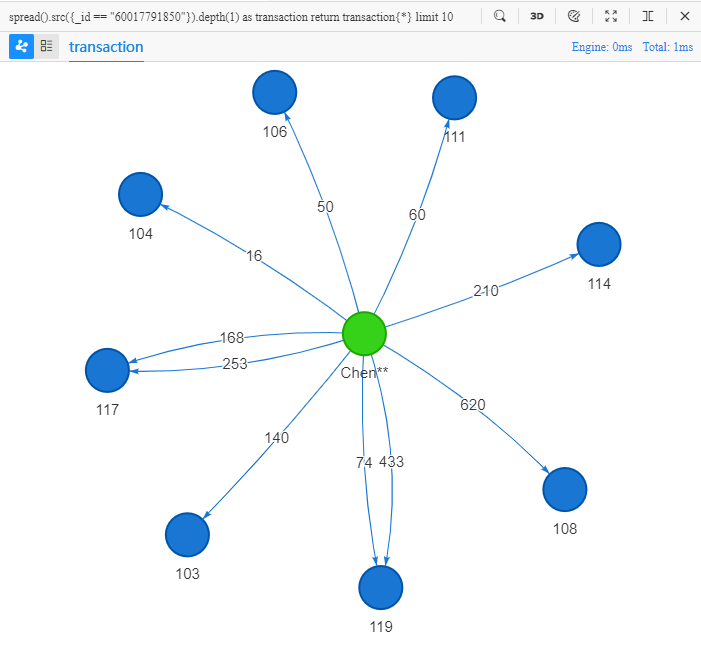
Query result of paths are auto visualized in 2D view in Ultipa Manager, where the multiple transactions between Chen** and the two merchants '117' and '119' are intuitively observed.
To acquire an exact number of distinct end-node merchants through the above spread() query, some deduplication operation can be involved before returning the final result. Another option is to use a different query command that by design searches in BFS manner but returns nodes.
K-Hop
khop().src({_id == "60017791850"}).depth(1) as merchant
return merchant{*} limit 10
Its literal meaning: hop K times from a source whose ID is 60017791850, to a depth of 1, return all properties of 10 such records.
- Command
khop()initiates a query for nodes start from a center nodesrc(), in BFS manner - Alias merchant represents nodes
The target of the above UQL is 'find 10 different merchants who receive payments from Chen** and return all properties of these merchants:
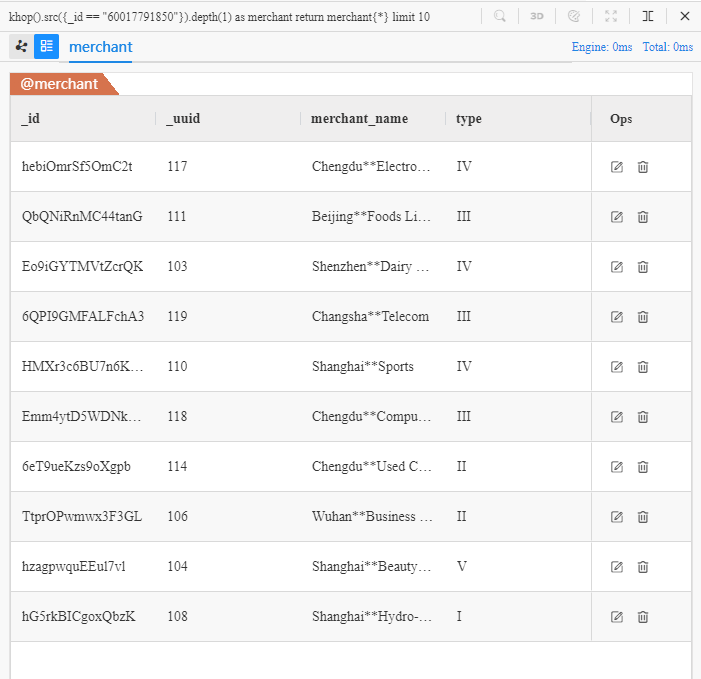
Two more merchants '110' and '118' are found by
khop(), in addition to those 8 merchants found byspread().
Think in 'Template'
Template query is an advanced type of graph query by accurately describing each node and edge in a path. It employs parameters n(), e() and nf() aforementioned in Graph Data.
Chains
n({_id == "60017791850"}).e().n() as transaction
return transaction{*} limit 10
Its literal meaning: find 1-step paths from node whose ID is 60017791850 and return all information of 10 such paths:
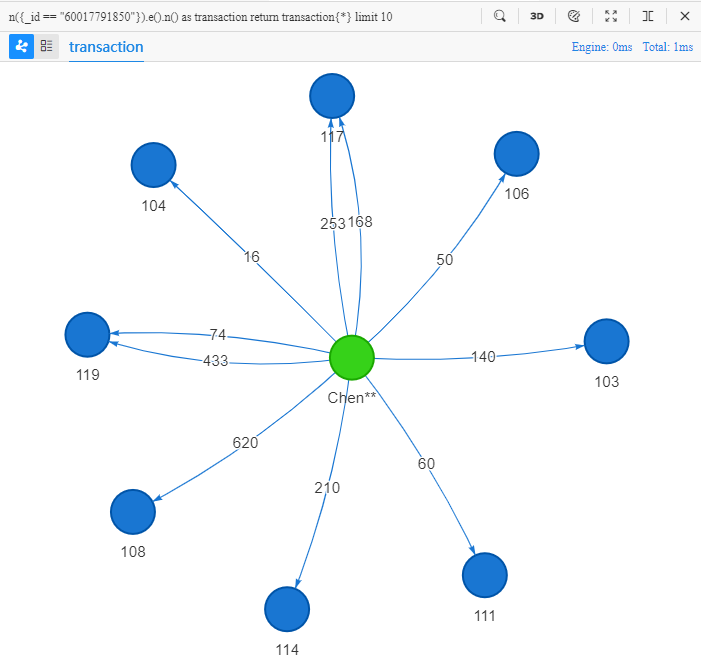
It achieves the same result as the previous query using
spread(), as both queries searches for 1-step paths from customer Chen**.
Now consider a path that starts from Chen** and reaches a merchant via 3 edges, all edges should have transaction amount greater than 70000:

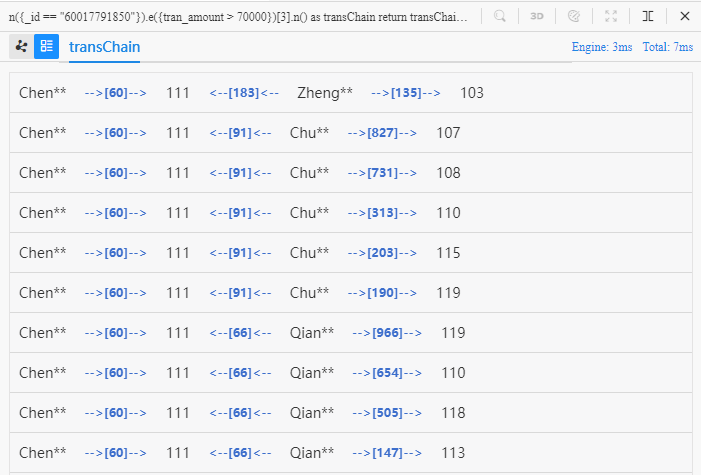
n({_id == "60017791850"}).e({tran_amount > 70000})[3].n() as transChain
return transChain{*} limit 10
- Symbol
[3]followinge()indicates the number of edges in the path (same purpose asdepth())
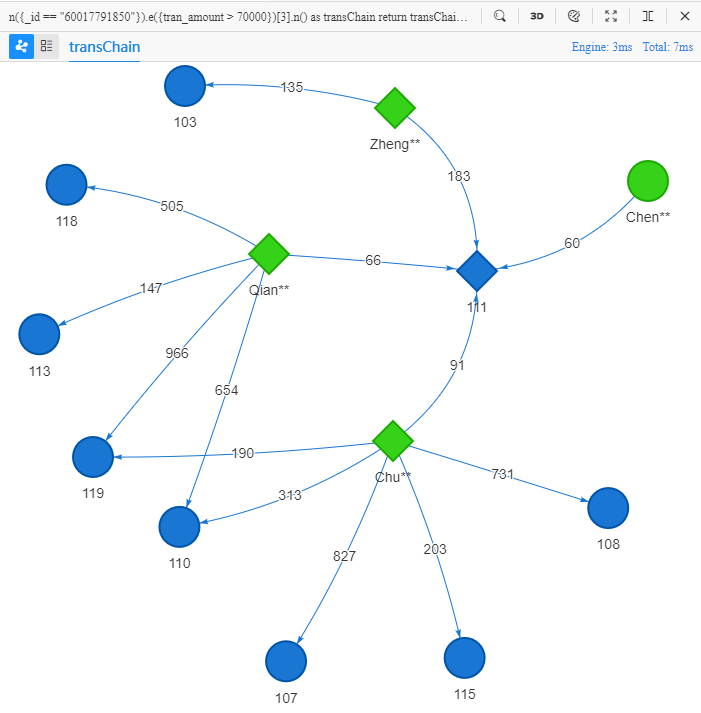
These 10 paths diverge from the 2nd node in each of their own, merchant '111', into 3 branches, and further diverge from those three customers Zheng**, Qian** and Chu** into 10 branches, which eventually reach 8 different merchants.
If the shopping behaviors of Chen**, Zheng**, Qian** and Chu**, those who all purchase products from merchant '111', are concluded similar, then it is reasonable to recommend some of those 8 merchants at terminal node to customer Chen**, which is a typical product and merchant recommendation scenario.
The 2D view of Ultipa Manager does not re-render the same node or edge for a different path. When all 10 paths start from Chen**, pass edge '60' and reach merchant '111', these 3 metadata are shared in the 2D view. A list view will show clearly all the metadata of each path:
Circles
Edges in a path never repeat, but nodes do sometimes, which induces circles into the path.
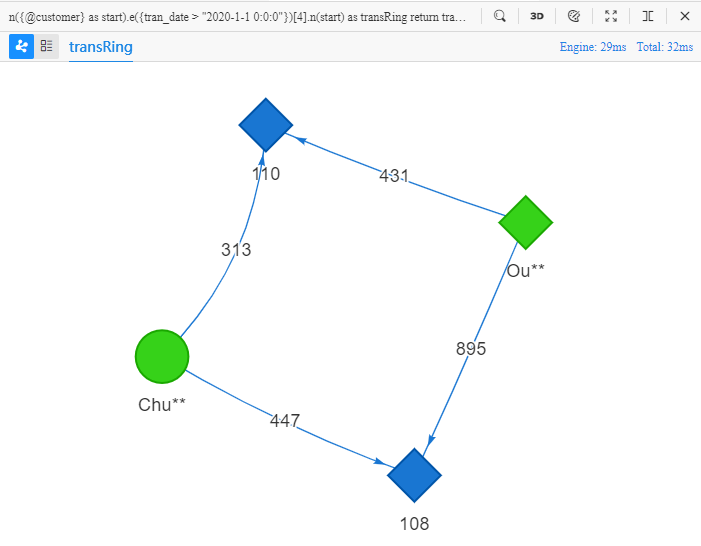
n({@customer} as start).e({tran_date > "2020-1-1 0:0:0"})[4].n(start) as transRing
return transRing{*} limit 10
- The last
n()calls the alias start defined in the firstn(), so the initial node and the terminal node of the path become the same node
The target of the above UQL is 'find 10 four-step paths starting from a @customer node and back to this node again eventually, where each transaction happens after 2020-1-1 0:0:0, return all properties of nodes and edges in these paths':
The list view of the query result:
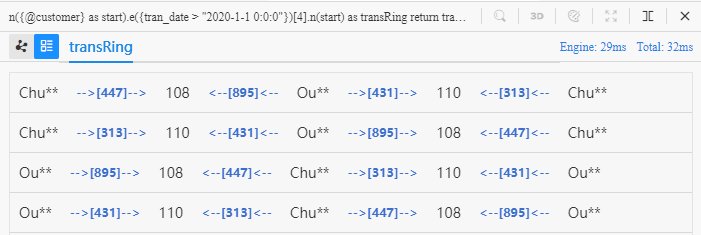
In these four-step circles, both customers Chu** and Ou** purchase products from merchants '110' and '108', this provides evidence of some similarities between these two customers.
Shortest Paths
n({_id == "60017791850"}).e()[:5].n(115) as transRange
return transRange{*} limit 1
- The value
:5in the bracket can also be written as1:5, which specifies a flexible range of path length instead of a fixed number - The number '115' in the last
n()is a brief format of{_uuid == 115}
The target of the above UQL is 'find a path from Chen** to the node whose UUID is 115, with a length no greater than 5, return all properties of nodes and edges in the path':
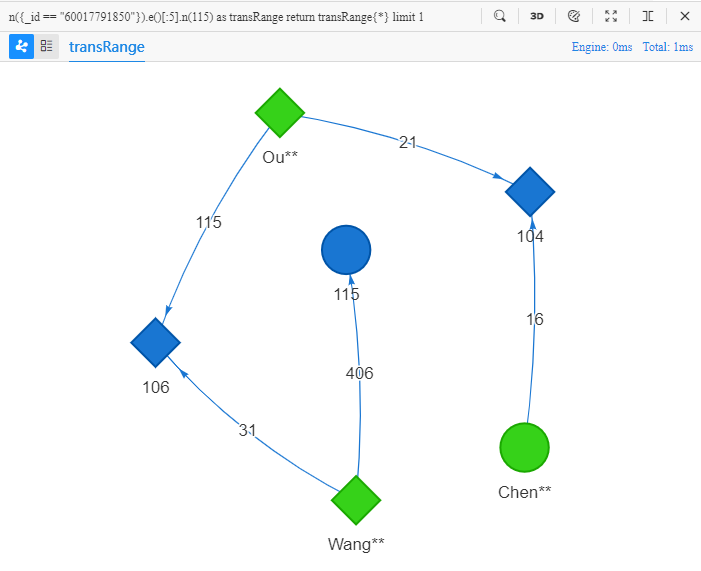
By chance, the found path has exactly 5 edges.
A minor revision made to the path length might completely change the query target of the UQL:
n({_id == "60017791850"}).e()[*:5].n(115) as transShortest
return transShortest{*} limit 1
- By adding a star
*, the value*:5turns the template into a shortest path with a length no greater than 5
The target of the above UQL is 'find a shortest path from Chen** to the node whose UUID is 115, with a length no greater than 5, return all properties of nodes and edges in the path':
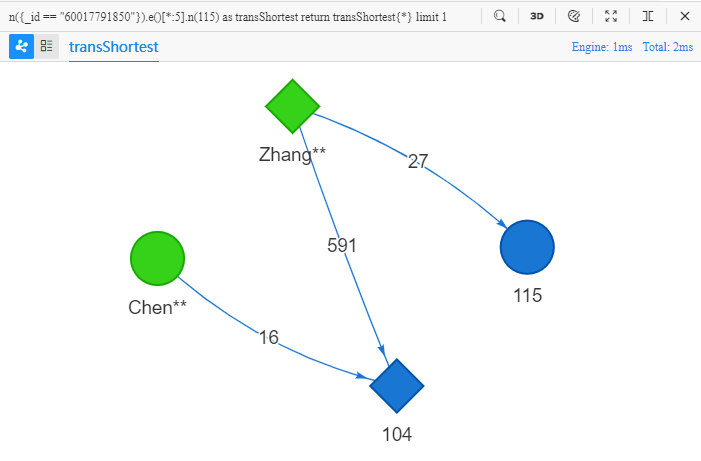
Shortest path suggests the most direct connection between two nodes. In general, the shorter the path, the greater its connectiveness, and the more value to analyze. For this reason, real-world entities sometimes intentionally hide themselves in exceedingly long distance away (20~30 steps) from another entity. To dig out these suspicious entites, a high-performance DBMS with HTAP-capability, ultra-deep graph traversal capability, and outstanding responsiveness is needed.
Common Calculations
UQL can conduct a variety of calculations after finding nodes, edges and paths, via functions and clauses. This section introduces some frequently used ones, please refer to UQL manual for detail.
Deduplicate
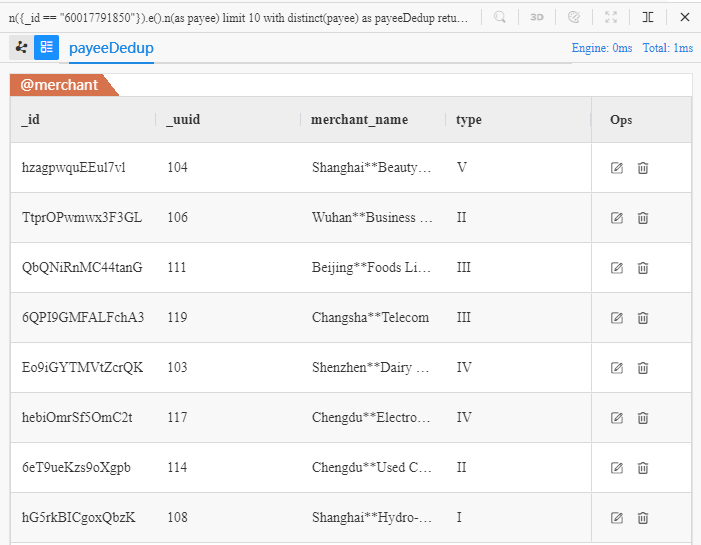
Revise the first example demonstrated in section Chains to find those 8 distinct merchants out of 10 in total:
n({_id == "60017791850"}).e().n(as payee) limit 10
with distinct payee as payeeDedup
return payeeDedup{*}
- Operator
distinctdeduplicates payee based on node ID - Deduplication operation is composed in
with - Statement
limit 10is executed beforewith, all UQL statements are executed in the order they are composed
Count
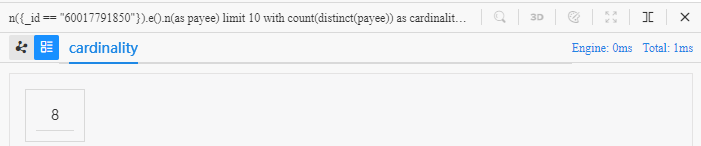
Revise the previous example to calculate the number of distinct merchants:
n({_id == "60017791850"}).e().n(as payee) limit 10
with count(distinct payee) as cardinality
return cardinality
- Function
count()calculates the number ofdistinct payee,count()anddistinctare sometimes jointly used
Order By
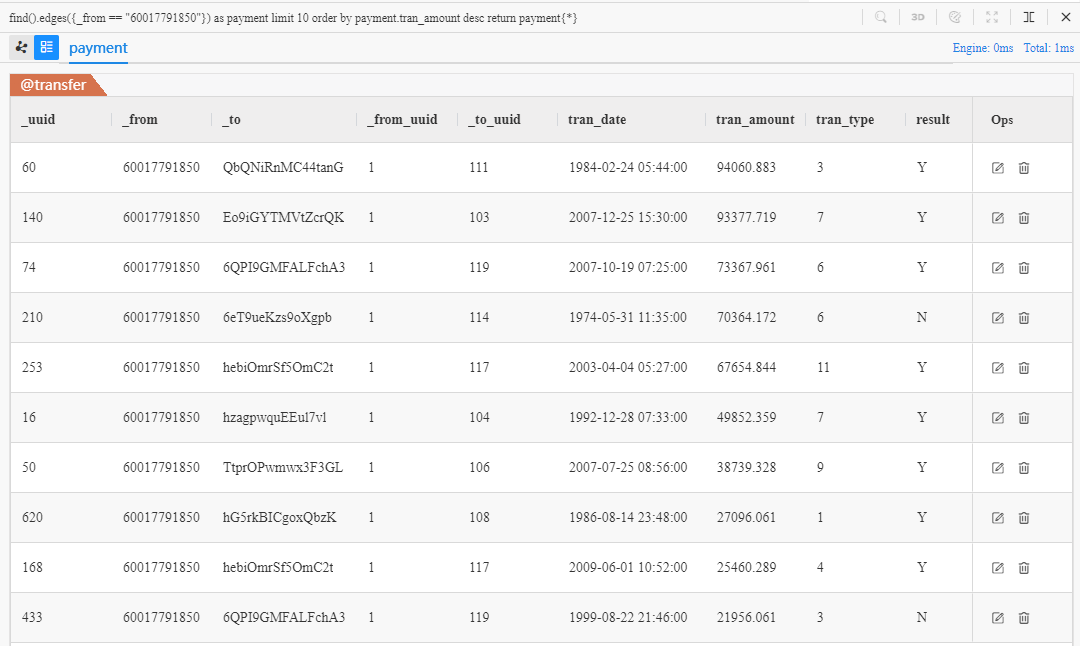
Revise the first example demonstrated in section Edge Query to return those 10 edges in descending order of their transaction amount:
find().edges({_from == "60017791850"}) as payment limit 10
order by payment.tran_amount desc
return payment{*}
- Clause keyword
order bysorts payment by its property tran_amount - Keyword
descin the end of clauseorder bymeans to sort in descending pattern
Group By
Revise the second example demonstrated in section Chains to group those 3-step paths by their 3rd node, and count the number of paths in each group:
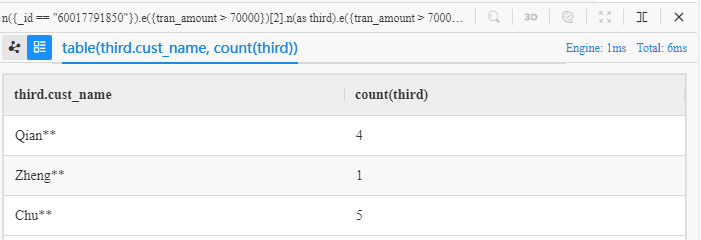
n({_id == "60017791850"}).e({tran_amount > 70000})[2].n(as third).e({tran_amount > 70000}).n() limit 10
group by third
return table(third.cust_name, count(third))
- To express the 3rd node in the path, the original template
n().e()[3].n()is transformed inton().e()[2].n().e().n() - Clause keyword
group bydivides third based on node ID - Function
count()is executed against third within each group - Function
table()mergesthird.cust_nameandcount(third)in one table to make them more convenient to check