Random Walk
✓ File Writeback ✕ Property Writeback ✓ Direct Return ✓ Stream Return ✕ Stats
Overview
A random walk begins at a particular node in graph and proceeds by randomly moving to one of its neighboring nodes; this process is often repeated for a defined number of steps. This concept was introduced by the British mathematician and biostatistician Karl Pearson in 1905, and it has since become a cornerstone in the study of various systems, both within and beyond graph theory.
- K. Pearson, The Problem of the Random Walk (1905)
Concepts
Random Walk
Random walk is a mathematical model employed to simulate a series of steps taken in a stochastic or unpredictable manner, like the erratic path of a drunken person.
The basic random walk is performed in a one-dimensional space: a node initiates from the origin of a number line and moves up or down by one unit at a time with equal likelihood. An example of a 10-step random walk is as follows:
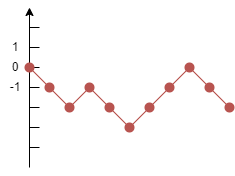
Here is an example of performing this random walk multiple times, with each walk consisting of 100 steps:
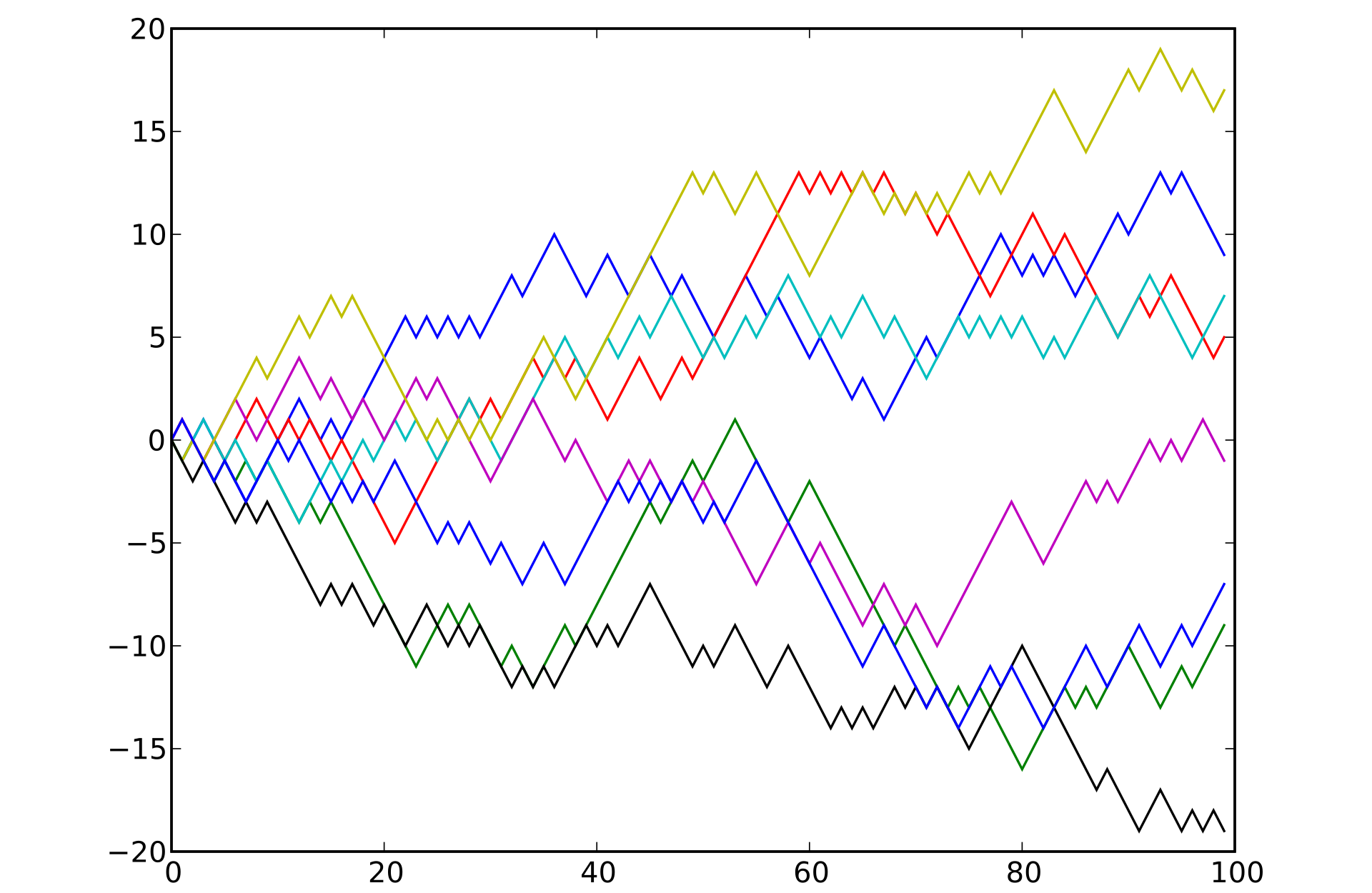
Random Walk in Graph
In a graph, a random walk is a process where a path is formed by starting from a node and moving sequentially through neighboring nodes. This process is controlled by the walk depth, which determines the number of nodes to be visited.
Ultipa's Random Walk algorithm implements the classical form of random walk. By default, each edge is assigned the same weight (equal to 1), resulting in equal probabilities of traversal. When edge weights are specified, the likelihood of traversing those edges becomes proportional to their weights. It's important to note that various variations of random walk exist, such as Node2Vec Walk and Struc2Vec Walk.
Considerations
- Self-loops are also eligible to be traversed during the random walk.
- If the walk starts from an isolated node without any self-loop, the walk halts after the first step as there are no adjacent edges to proceed to.
- The Random Walk algorithm ignores the direction of edges but calculates them as undirected edges.
Syntax
- Command:
algo(random_walk) - Parameters:
| Name | Type | Spec | Default | Optional | Description |
|---|---|---|---|---|---|
| ids / uuids | []_id / []_uuid | / | / | Yes | ID/UUID of nodes to start random walks; start from all nodes if not set |
| walk_length | int | ≧1 | 1 | Yes | Depth of each walk, i.e., the number of nodes to visit |
| walk_num | int | ≧1 | 1 | Yes | Number of walks to perform for each specified node |
| edge_schema_property | []@<schema>?.<property> | Numeric type, must LTE | / | Yes | Edge property(-ies) to use as edge weight(s), where the values of multiple properties are summed up; nodes only walk along edges with the specified property(-ies) |
| limit | int | ≧-1 | -1 | Yes | Number of results to return, -1 to return all results |
Example
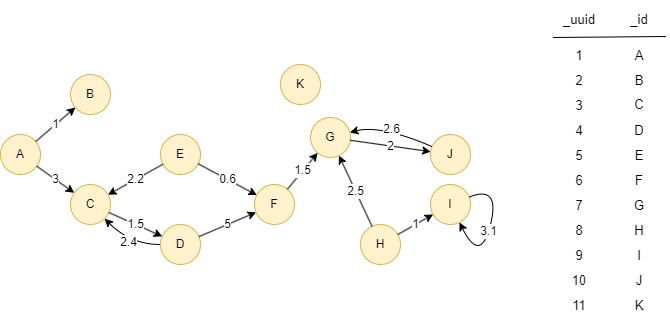
The example graph is as follows, numbers on edges are the values of edge property score:
File Writeback
Spec | Content | Description |
|---|---|---|
| filename | _id,_id,... | IDs of visited nodes |
UQLalgo(random_walk).params({ walk_length: 6, walk_num: 2 }).write({ file:{ filename: 'walks' }})
Results: File walks
FileK, J,G,J,G,F,D, I,I,I,H,I,I, H,I,I,I,I,I, G,J,G,J,G,H, F,D,C,A,B,A, E,F,D,C,D,C, D,F,G,H,G,H, C,D,F,E,F,D, B,A,B,A,C,A, A,C,A,C,D,F, K, J,G,J,G,J,G, I,I,I,H,I,I, H,I,H,G,J,G, G,H,I,I,H,G, F,D,C,D,F,E, E,C,D,F,G,J, D,C,D,C,E,F, C,E,C,A,B,A, B,A,B,A,C,A, A,B,A,C,D,C,
Direct Return
| Alias Ordinal | Type | Description | Columns |
|---|---|---|---|
| 0 | []perWalk | Array of UUIDs of visited nodes | [_uuid, _uuid, ...] |
UQLalgo(random_walk).params({ walk_length: 6, walk_num: 2, edge_schema_property: 'score' }) as walks return walks
Results: walks
| [11] |
| [10, 7, 10, 7, 10] |
| [9, 9, 9, 9, 9] |
| [8, 9, 9, 9, 9] |
| [7, 10, 7, 10, 7] |
| [6, 4, 3, 4, 3] |
| [5, 6, 7, 6, 4] |
| [4, 6, 7, 10, 7] |
| [3, 1, 3, 1, 3] |
| [2, 1, 3, 1, 3] |
| [1, 3, 4, 3, 5] |
| [11] |
| [10, 7, 10, 7, 10] |
| [9, 9, 9, 8, 7] |
| [8, 9, 8, 7, 8] |
| [7, 6, 4, 6, 4] |
| [6, 5, 6, 4, 6] |
| [5, 3, 4, 6, 4] |
| [4, 6, 4, 6, 7] |
| [3, 4, 3, 4, 6] |
| [2, 1, 3, 1, 3] |
| [1, 2, 1, 3, 1] |
Stream Return
| Alias Ordinal | Type | Description | Columns |
|---|---|---|---|
| 0 | []perWalk | Array of UUIDs of visited nodes | [_uuid, _uuid, ...] |
UQLalgo(random_walk).params({ walk_length: 5, walk_num: 1, edge_schema_property: '@default.score' }).stream() as walks where size(walks) == 5 return walks
Results: walks
| [10, 7, 10, 7, 6] |
| [9, 9, 9, 9, 9] |
| [8, 9, 9, 9, 9] |
| [7, 10, 7, 6, 4] |
| [6, 4, 3, 4, 6] |
| [5, 6, 4, 6, 4] |
| [4, 3, 4, 6, 4] |
| [3, 1, 3, 5, 3] |
| [2, 1, 3, 4, 6] |
| [1, 2, 1, 2, 1] |