Label Propagation Algorithm
✓ File Writeback ✓ Property Writeback ✓ Direct Return ✓ Stream Return ✓ Stats
Overview
The Label Propagation algorithm (LPA) is a community detection algorithm using label propagation. Each node is initialized with a label and at every iteration of the algorithm, each node updates its label to the one that is most prevalent among its neighbors. This iterative process allows densely connected groups of nodes to converge on a consensus labels, nodes sharing the same label then forming a community.
LPA does not optimize any specific chosen measure of community strengths, and does not require the number of communities to be predefined. Instead, it leverages the network structure to guide its progression. This simplicity enables LPA to efficiently analyze large and complex networks.
Related material of the algorithm:
- U.N. Raghavan, R. Albert, S. Kumara, Near linear time algorithm to detect community structures in large-scale networks (2007)
Concepts
Label
Label of a node is initialized with a specified property value, or its unique UUID.
Nodes that have the same label at the end of the algorithm indicate their affiliation to a common community.
NOTEIn LPA, all initial labels are valid and able to propagate. If there is a need to specify some labels as invalid, please contact Ultipa team for customization.
Label Propagation
In the simplest settings, at every iteration of propagation, each node updates its label to the one that the maximum numbers of its neighbors belongs to.
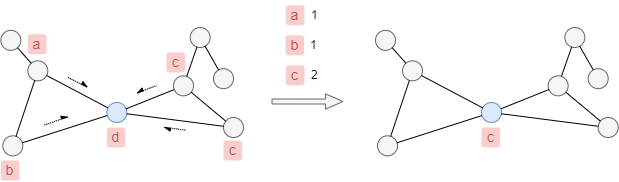
As the following example shows, the label of the blue node will be updated from d to c.
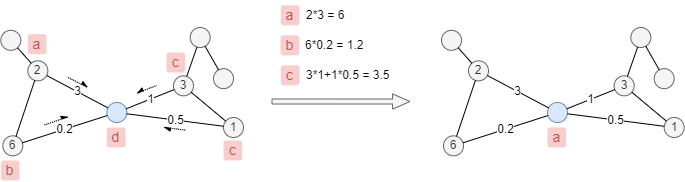
When considering node and edge weights, the label weight equals to the sum of the products of the corresponding node and edge weights, each node updates its label to the one with the largest weight.
As the weights of nodes and edges denoted in the example below, the label of the blue node will be updated from d to a.
Multi-label Propagation
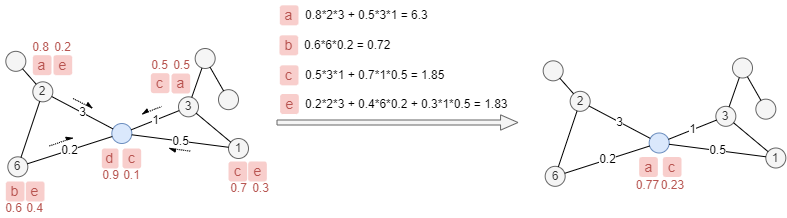
In multi-label propagation, each node accept multiple labels during the propagation. In this case, a label probability that is proportional to its weight is given to each label of a node, while the sum of label probabilities of each node keeps as 1.
In the example below, each node keeps 2 labels, the probabilities are written next to labels, the labels of the blue node will be updated from d, c to a, c with label probabilities Pa = 6.3/(6.3+1.85) = 0.77 and Pc = 1.85/(6.3+1.85) = 0.23.
Considerations
- LPA ignores the direction of edges but calculates them as undirected edges.
- Node with self-loops propagates its current label(s) to itself, and each self-loop is counted twice.
- LPA follows the synchronous update principle when updating node labels. This means that all nodes update their labels simultaneously based on the labels of their neighbors. However, in some cases, label oscillations can occur, particularly in bipartite graphs. To address this issue, the algorithm incorporates an interrupt mechanism that detects and prevents excessive label oscillations.
- Due to factors such as the order of nodes, the random selection of labels with equal weights, and parallel calculations, the community division results of LPA may vary.
Syntax
- Command:
algo(lpa) - Parameters:
| Name | Type | Spec | Default | Optional | Description |
|---|---|---|---|---|---|
| node_label_property | @<schema>?.<property> | Numeric/String type, must LTE | / | Yes | Node property to initialize node labels, nodes without the property are not involved in label propagation; UUID is used as label for all nodes if not set |
| node_weight_property | @<schema>?.<property> | Numeric type, must LTE | / | Yes | Node property to use as node weight |
| edge_weight_property | @<schema>?.<property> | Numeric type, must LTE | / | Yes | Edge property to use as edge weight |
| loop_num | int | ≥1 | 5 | Yes | Number of propagation iterations |
| k | int | ≥1 | 1 | Yes | Maximum number of labels each node keeps in the end (all labels are ordered by their probability from high to low) |
Examples
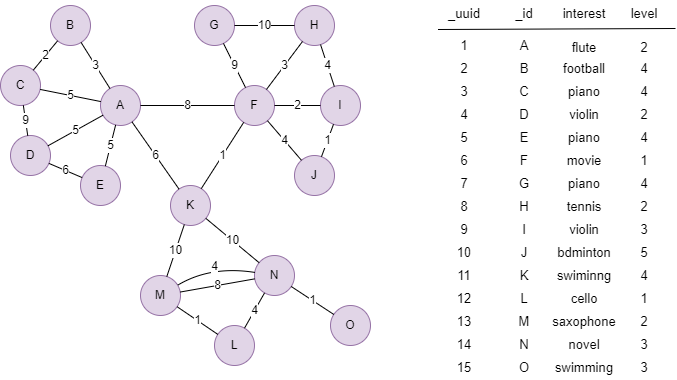
The example graph is as follows, nodes are of schema user, edges are of schema connect, the value of @connect.strength is shown in the graph:
File Writeback
Spec | Content |
|---|---|
| filename | _id,label_1,probability_1,...label_k,probability_k |
UQLalgo(lpa).params({ k: 2, loop_num: 5, edge_weight_property: 'strength' }).write({ file:{ filename: "lpa" } })
Statistics: label_count = 7
Results: File lpa
FileO,1,0.599162,2,0.400838, N,1,0.634582,2,0.365418, M,1,0.610834,2,0.389166, L,1,0.607434,2,0.392566, K,1,0.619842,2,0.380158, J,14,0.655975,8,0.344025, I,14,0.546347,8,0.453653, H,9,0.690423,7,0.309577, G,14,0.569427,8,0.430573, F,9,0.784132,7,0.215869, E,9,0.519003,12,0.480997, D,14,0.781072,9,0.218928, C,12,0.540345,9,0.459655, B,9,0.559427,14,0.440573, A,14,0.768171,12,0.231829,
Property Writeback
Spec | Content | Write to | Data Type |
|---|---|---|---|
| property | label_1, probability_1, ... label_k, probability_k | Node property | Label: string,Label probability: float |
UQLalgo(lpa).params({ node_label_property: 'interest', edge_weight_property: '@connect.strength', k: 2, loop_num: 10 }).write({ db:{ property: "lab" } })
Statistics: label_count = 5
Results: The labels and the corresponding probability of each node is written to new properties lab_1, probability_1, lab_2 and probability_2 respectively
Direct Return
Alias Ordinal | Type | Description | Columns |
|---|---|---|---|
| 0 | []perNode | Node and its labels, label probabilities | _uuid, label_1, probability_1, ... label_k, probability_k |
| 1 | KV | Number of labels | label_count |
UQLalgo(lpa).params({ node_label_property: '@user.interest', node_weight_property: '@user.level' }) as res return res
Results: res
| _uuid | label_1 | probability_1 |
|---|---|---|
| 15 | novel | 1.000000 |
| 14 | swimming | 1.000000 |
| 13 | novel | 1.000000 |
| 12 | novel | 1.000000 |
| 11 | novel | 1.000000 |
| 10 | violin | 1.000000 |
| 9 | badminton | 1.000000 |
| 8 | piano | 1.000000 |
| 7 | badminton | 1.000000 |
| 6 | badminton | 1.000000 |
| 5 | piano | 1.000000 |
| 4 | piano | 1.000000 |
| 3 | piano | 1.000000 |
| 2 | piano | 1.000000 |
| 1 | piano | 1.000000 |
UQLalgo(lpa).params({ node_label_property: 'interest', k: 2 }) as res, stats return res, stats
Results: res and stats
| _uuid | label_1 | probability_1 | label_2 | probability_2 |
|---|---|---|---|---|
| 15 | novel | 0.642453 | saxophone | 0.357547 |
| 14 | swimming | 0.577773 | saxophone | 0.422227 |
| 13 | novel | 0.610180 | swimming | 0.389820 |
| 12 | saxophone | 0.608193 | novel | 0.391807 |
| 11 | piano | 0.536380 | saxophone | 0.463620 |
| 10 | piano | 0.588276 | movie | 0.411724 |
| 9 | piano | 0.595449 | movie | 0.404551 |
| 8 | piano | 0.637065 | movie | 0.362935 |
| 7 | piano | 0.554655 | movie | 0.445345 |
| 6 | piano | 0.720096 | movie | 0.279904 |
| 5 | piano | 0.502892 | flute | 0.497108 |
| 4 | piano | 0.648339 | flute | 0.351661 |
| 3 | piano | 0.520442 | flute | 0.479558 |
| 2 | piano | 0.624170 | flute | 0.375831 |
| 1 | piano | 0.670773 | flute | 0.329227 |
| label_count |
|---|
| 6 |
Stream Return
Alias Ordinal | Type | Description | Columns |
|---|---|---|---|
| 0 | []perNode | Node and its labels, label probabilities | _uuid, label_1, probability_1, ... label_k, probability_k |
UQLalgo(lpa).params({ node_label_property: '@user.interest', node_weight_property: '@user.level', edge_weight_property: 'strength', loop_num: 10 }).stream() as lpa group by lpa.label_1 with count(lpa) as labelCount return table(lpa.label_1, labelCount) order by labelCount desc
Results: table(lpa.label_1, labelCount)
| lpa.label_1 | labelCount |
|---|---|
| piano | 5 |
| swimming | 3 |
| violin | 2 |
| novel | 2 |
| tennis | 2 |
Stats Return
Alias Ordinal | Type | Description | Columns |
|---|---|---|---|
| 0 | KV | Number of labels | label_count |
UQLalgo(lpa).params({ node_label_property: 'interest', edge_weight_property: 'strength', k: 1, loop_num: 5 }).stats() as count return count
Results: count
| label_count |
|---|
| 5 |