
Vue d’ensemble
L'algorithme SybilRank classe la confiance des nodes par des marches aléatoires interrompues tôt dans le réseau, généralement un Réseau Social en Ligne (OSN). L'essor des OSNs s'est accompagné de l'augmentation des attaques Sybil, sous lesquelles un attaquant malveillant crée plusieurs faux comptes (Sybil), dans le but de faire du spam, de distribuer des logiciels malveillants, de manipuler les votes ou les comptages de vues pour des contenus de niche, etc.
SybilRank a été proposé par Qiang Cao et al. en 2012, il est efficace sur le plan computationnel et peut s'adapter à de grands graphs.
- Q. Cao, M. Sirivianos, X. Yang, T. Pregueiro, Aiding the Detection of Fake Accounts in Large Scale Social Online Services (2012)
Concepts
Modèle de Menace et Graines de Confiance
SybilRank considère un OSN comme un graph non dirigé, où chaque node correspond à un utilisateur du réseau, et chaque edge correspond à une relation sociale bilatérale.
Dans le modèle de menace de SybilRank, tous les nodes sont divisés en deux ensembles disjoints : non-Sybil H, et Sybil S. Désignons la région non-Sybil GH comme le sous-graph induit par l'ensemble H, qui inclut tous les non-Sybil et les edges entre eux. De même, la région Sybil GS est le sous-graph induit par S. GH et GS sont connectés par attack edges entre les Sybil et les non-Sybil.
Certains nodes considérés comme non-Sybil sont spécifiés comme des graines de confiance pour le fonctionnement de SybilRank. La transmission de la confiance sur plusieurs nodes rend SybilRank robuste aux erreurs de sélection de graines, car désigner incorrectement un node qui est Sybil ou proche de Sybil comme graine entraîne seulement une petite fraction de la confiance totale à être initialisée et propagée dans la région Sybil.
Vous trouverez ci-dessous un exemple de modèle de menace avec des graines de confiance :
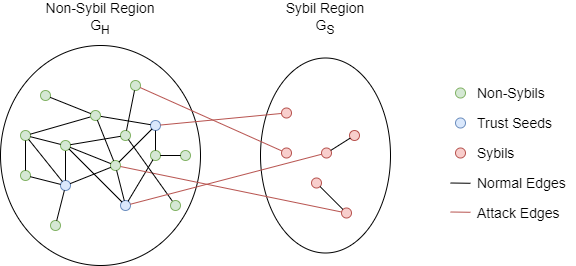
Une hypothèse importante de SybilRank est que le nombre d’attack edges est limité. Puisque SybilRank est conçu pour des attaques à grande échelle, où les faux comptes sont créés et maintenus à faible coût, et sont donc incapables de se lier d'amitié avec de nombreux vrais utilisateurs. Cela résulte en une faible coupe entre GH et GS.
Marche Aléatoire Interrompue Tôt
Dans un graph non dirigé, si la probabilité de transition d’une marche aléatoire vers un node voisin est uniformément distribuée, lorsque le nombre d'étapes est suffisant, la probabilité de se retrouver à chaque node convergerait pour être proportionnelle à son degré. Le nombre d'étapes qu'une marche aléatoire nécessite pour atteindre la distribution stationnaire est appelé le temps de mélange du graph.
SybilRank repose sur l'observation qu'une marche aléatoire interrompue tôt partant d’un node non-Sybil (graine de confiance) a une probabilité plus élevée de se retrouver à un node non-Sybil qu'à un node Sybil, puisque la marche est peu susceptible de traverser un des rares attack edges. C'est-à-dire qu'il y a une différence significative entre le temps de mélange de la région non-Sybil GH et l'ensemble du graph.
SybilRank se réfère à la probabilité de se retrouver sur chaque node comme la confiance du node. SybilRank classe les nodes selon leurs scores de confiance ; les nodes avec des scores de confiance faibles sont classés plus haut, et ce sont potentiellement des faux utilisateurs.
Propagation de Confiance via Itération de Puissance
SybilRank utilise la technique de l'itération de puissance pour calculer efficacement la probabilité de se retrouver à un endroit des marches aléatoires dans de grands graphs. L'itération de puissance implique des multiplications matricielles successives où chaque élément de la matrice représente la probabilité de transition d'une marche aléatoire d'un node à un node voisin. Chaque itération calcule la distribution de la probabilité de se retrouver sur tous les nodes au fur et à mesure que la marche aléatoire avance d'une étape.
Dans un graph non dirigé G = (V, E), initialement une confiance totale TG est distribuée de manière égale parmi toutes les graines de confiance. Lors de chaque itération de puissance, un node distribue d'abord sa confiance de manière égale à ses voisins ; il recueille ensuite la confiance distribuée par ses voisins et met à jour sa propre confiance en conséquence. La confiance du node v à la i-ème itération est :
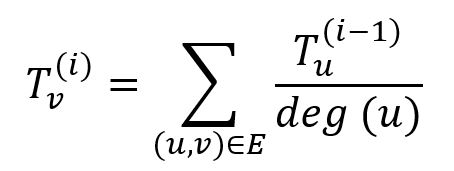
où le node u appartient à l'ensemble voisin du node v, deg(u) est le degré du node u. Le montant total de confiance TG reste inchangé tout le temps.
Avec suffisamment d'itérations de puissance, la confiance de tous les nodes convergerait vers la distribution stationnaire :
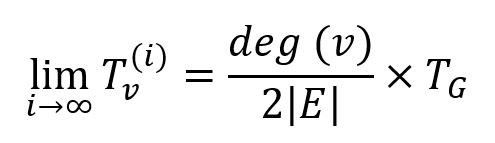
Cependant, SybilRank termine l'itération de puissance après un certain nombre d'étapes avant la convergence, et il est suggéré de le définir comme log(|V|). Ce nombre d'itérations est suffisant pour atteindre une distribution stationnaire approximativement de la confiance sur la région non-Sybil à mélange rapide GH, mais limite la confiance s'échappant vers la région Sybil GS, donc les non-Sybil seront classés plus haut que les Sybil.
En pratique, le temps de mélange de GH est affecté par de nombreux facteurs, donc
log(|V|)est seulement une référence, mais il doit être inférieur au temps de mélange de l'ensemble du graph.
Considérations
- Chaque boucle auto-ajoutée ajoute deux degrés à son sujet node.
- L'algorithme SybilRank ignore la direction des edges mais les calcule comme des edges non dirigés.
- Le coût computationnel de SybilRank est O(n log n). Cela est dû au fait que chaque itération de puissance coûte O(n), et il itère O(log n) fois. Il n'est pas lié au nombre de graines de confiance.
Syntaxe
- Commande :
algo(sybil_rank) - Paramètres :
Nom |
Type |
Spéc |
Défaut |
Optionnel |
Description |
|---|---|---|---|---|---|
| total_trust | float | >0 | / | Non | Confiance totale du graph |
| trust_seeds | []_uuid |
/ | / | Oui | UUID des graines de confiance, il est suggéré d'assigner des graines de confiance pour chaque communauté; tous les nodes sont spécifiés comme des graines de confiance si non défini |
| loop_num | int | >0 | 5 |
Oui | Nombre d'itérations, il est suggéré de définir comme log(|V|) (base-2) |
| limit | int | ≥-1 | -1 |
Oui | Nombre de résultats à retourner, -1 pour retourner tous les résultats |
Exemples
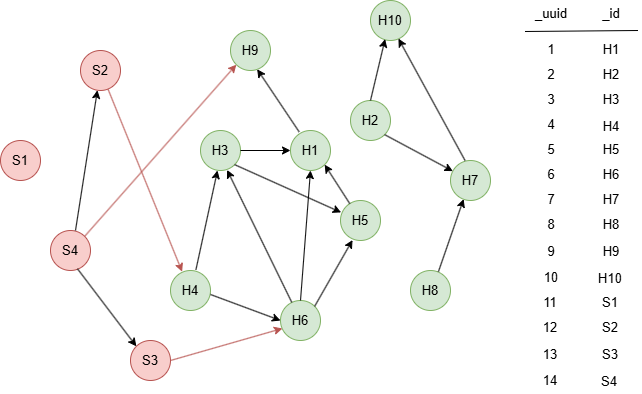
Le graph d'exemple est le suivant :
File Writeback
| Spéc | Contenu |
|---|---|
| filename | _id,rank |
algo(sybil_rank).params({
total_trust: 100,
trust_seeds: [2,3,5],
loop_num: 4
}).write({
file:{
filename: 'sybilRank'
}
})
Résultats : Fichier sybilRank
S1,0
S4,3.61111
S2,4.45602
S3,4.71065
H9,5.0434
H8,5.09259
H4,6.66667
H10,7.87037
H5,8.67766
H1,9.59491
H2,9.9537
H7,10.4167
H3,11.305
H6,12.6013
Property Writeback
| Spéc | Contenu | Écrire à | Type de Donnée |
|---|---|---|---|
| property | rank |
Node property | float |
algo(sybil_rank).params({
total_trust: 100,
trust_seeds: [2,3,5],
loop_num: 4
}).write({
db:{
property: 'trust'
}
})
Résultats : Score de confiance pour chaque node est écrit dans une nouvelle propriété nommée trust
Direct Return
| Ordinal Alias | Type | Description |
Colonnes |
|---|---|---|---|
| 0 | []perNode | Node et sa confiance | _uuid, rank |
algo(sybil_rank).params({
total_trust: 100,
trust_seeds: [2,3,5],
loop_num: 4
}) as trust
return trust
Résultats : trust
| _uuid | rank |
|---|---|
| 11 | 0.0000000 |
| 14 | 3.6111109 |
| 12 | 4.4560180 |
| 13 | 4.7106481 |
| 9 | 5.0434031 |
| 8 | 5.0925918 |
| 4 | 6.6666660 |
| 10 | 7.8703699 |
| 5 | 8.6776609 |
| 1 | 9.5949059 |
| 2 | 9.9537029 |
| 7 | 10.416666 |
| 3 | 11.304976 |
| 6 | 12.601272 |
Stream Return
| Ordinal Alias | Type | Description |
Colonnes |
|---|---|---|---|
| 0 | []perNode | Node et sa confiance | _uuid, rank |
algo(sybil_rank).params({
total_trust: 100,
trust_seeds: [2,3,5],
loop_num: 4,
limit: 4
}).stream() as trust
find().nodes({_uuid == trust._uuid}) as nodes
return table(nodes._id, trust.rank)
Résultats : table(nodes._id, trust.rank)
| nodes._id | trust.rank |
|---|---|
| S1 | 0.0000000 |
| S4 | 3.6111109 |
| S2 | 4.4560180 |
| S3 | 4.7106481 |