
UNCOLLECT libère chaque élément d'une liste en une ligne indépendante et duplique chaque ligne originale et ses lignes homologues en un nombre correspondant de lignes multiples. Le flux de données libéré a une longueur égale à la somme des longueurs de toutes les listes qui ont été libérées du flux de données original.
Syntaxe: UNCOLLECT <expression1> as <alias1>, <expression2> as <alias2>, ...
Entrée
- <\expression>: La liste à libérer
- <\alias>: L'alias acquis après que la liste soit libérée, obligatoire
Lors de la libération de plusieurs flux de données de listes, la longueur libérée des listes de chaque ligne est sujette à la liste de cette ligne avec le plus grand nombre d'éléments, remplissant avec
nullsi insuffisant.
Par exemple, libérer tous les nodes dans path, les alias homologues path et a1 ont 2 lignes, après libération path et a2 ont 6 lignes:
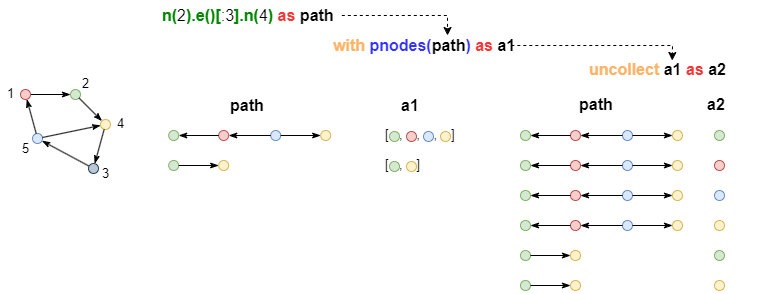
n(2).e()[:3].n(4) as path
with pnodes(path) as a1
uncollect a1 as a2
return path, a2
Un autre exemple est donné pour libérer deux flux de données s1 et s2, où le [1,2] dans la première ligne de s2 et le ["d","e"] dans la deuxième ligne de s1 sont complétés avec null afin de compléter la longueur:
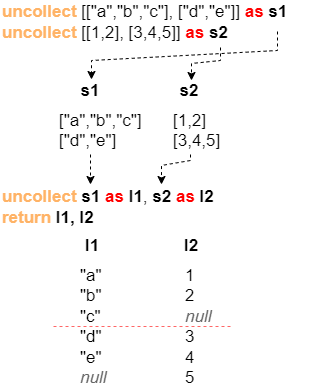
uncollect [["a","b","c"],["d","e"]] as s1
uncollect [[1,2],[3,4,5]] as s2
uncollect s1 as l1, s2 as l2
return l1, l2
Échantillon de graph : (à utiliser pour les exemples suivants)
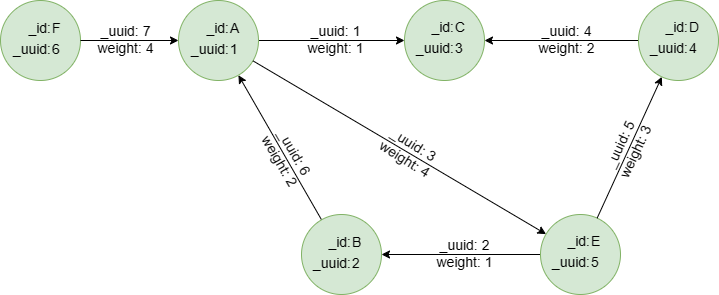
create().edge_property(@default, "weight", int32)
insert().into(@default).nodes([{_id:"A", _uuid:1}, {_id:"B", _uuid:2}, {_id:"C", _uuid:3}, {_id:"D", _uuid:4}, {_id:"E", _uuid:5}, {_id:"F", _uuid:6}])
insert().into(@default).edges([{_uuid:1, _from_uuid:1, _to_uuid:3, weight:1}, {_uuid:2, _from_uuid:5, _to_uuid:2 , weight:1}, {_uuid:3, _from_uuid:1, _to_uuid:5 , weight:4}, {_uuid:4, _from_uuid:4, _to_uuid:3 , weight:2}, {_uuid:5, _from_uuid:5, _to_uuid:4 , weight:3}, {_uuid:6, _from_uuid:2, _to_uuid:1 , weight:2}, {_uuid:7, _from_uuid:6, _to_uuid:1 , weight:4}])
Utilisation Courante
Exemple : Trouver des paths de 2 étapes de A à D, dédupliquer tous les nodes impliqués et retourner
n({_id == "A"}).e()[2].n({_id == "D"}) as p
uncollect pnodes(p) as a
with dedup(a) as b
return b{*}
| _id | _uuid |
|-----|-------|
| A | 1 |
| C | 3 |
| D | 4 |
| E | 5 |