
GROUP BY divise les lignes dans l'alias en groupes, pour chaque groupe garde une ligne et élimine le reste des lignes ; il est toujours utilisé en combinaison avec des opérations d'agrégation et ORDER BY.
Syntaxe : GROUP BY <expression> as <alias>, <expression> as <alias>, ...
Entrée :
<expression>: Critère de regroupement ; plusieurs critères doivent être homogènes et sont opérés de gauche à droite<alias>: Alias du critère de regroupement, optionnel
Par exemple, appliquez un regroupement multi-niveaux à path, d'abord par la forme des initial-nodes n1, puis par la couleur des terminal-nodes n2 dans chaque groupe ; comptez le nombre de paths dans chaque groupe et retournez à la fois path et le compte.

n(as n1).re().n(as n2) as path
group by n1.shape, n2.color
return path, count(path)
Exemple de graph : (à utiliser pour les exemples suivants)
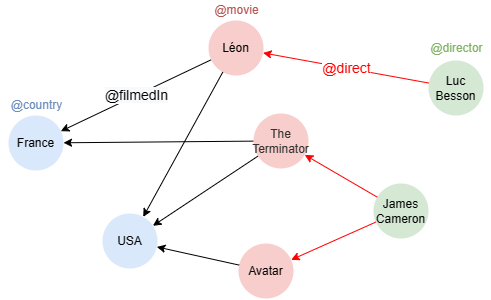
create().node_schema("country").node_schema("movie").node_schema("director").edge_schema("filmedIn").edge_schema("direct")
create().node_property(@*, "name")
insert().into(@country).nodes([{_id:"C001", _uuid:1, name:"France"}, {_id:"C002", _uuid:2, name:"USA"}])
insert().into(@movie).nodes([{_id:"M001", _uuid:3, name:"Léon"}, {_id:"M002", _uuid:4, name:"The Terminator"}, {_id:"M003", _uuid:5, name:"Avatar"}])
insert().into(@director).nodes([{_id:"D001", _uuid:6, name:"Luc Besson"}, {_id:"D002", _uuid:7, name:"James Cameron"}])
insert().into(@filmedIn).edges([{_uuid:1, _from_uuid:3, _to_uuid:1}, {_uuid:2, _from_uuid:4, _to_uuid:1}, {_uuid:3, _from_uuid:3, _to_uuid:2}, {_uuid:4, _from_uuid:4, _to_uuid:2}, {_uuid:5, _from_uuid:5, _to_uuid:2}])
insert().into(@direct).edges([{_uuid:6, _from_uuid:6, _to_uuid:3}, {_uuid:7, _from_uuid:7, _to_uuid:4}, {_uuid:8, _from_uuid:7, _to_uuid:5}])
Regroupement et Agrégation
Exemple : Trouver des paths en 2 étapes @country-@movie-@director, regrouper par director et compter le nombre de paths dans chaque groupe
n({@country}).e().n({@movie}).e().n({@director} as n)
group by n
return table(n.name, count(n))
| n.name | count(n) |
|---------------|----------|
| Luc Besson | 2 |
| James Cameron | 3 |
Analyse : Une agrégation est exécutée dans chaque groupe uniquement si la fonction d'agrégation est composée juste après la clause GROUP BY.
Regroupement Multi-niveaux
Exemple : Trouver des paths en 2 étapes @country-@movie-@director, regrouper par country puis par director, compter le nombre de paths dans chaque groupe
n({@country} as a).e().n({@movie}).e().n({@director} as b)
group by a, b
return table(a.name, b.name, count(a))
| a.name | b.name | count(a) |
|--------|---------------|----------|
| France | Luc Besson | 1 |
| France | James Cameron | 1 |
| USA | Luc Besson | 1 |
| USA | James Cameron | 2 |