
Vue d’ensemble
La similarité de recouvrement est dérivée de la similarité de Jaccard, également appelée le coefficient de Szymkiewicz–Simpson. Elle divise la taille de l'intersection de deux ensembles par la taille du plus petit ensemble dans le but d'indiquer à quel point les deux ensembles sont similaires.
La similarité de recouvrement va de 0 à 1 ; 1 signifie qu'un ensemble est le sous-ensemble de l'autre ou que les deux ensembles sont exactement les mêmes, 0 signifie que les deux ensembles n'ont aucun élément en commun.
Concepts
Similarité de Recouvrement
Étant donné deux ensembles A et B, la similarité de recouvrement entre eux est calculée comme suit :
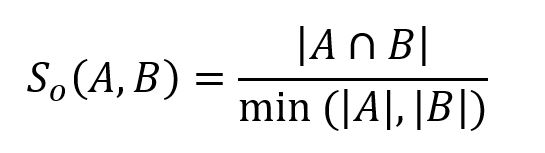
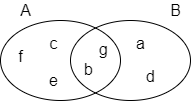
Dans l'exemple suivant, ensemble A = {b,c,e,f,g}, ensemble B = {a,d,b,g}, leur intersection A⋂B = {b,g}, d'où la similarité de recouvrement entre A et B est 2 / 4 = 0,5.
Lors de l'application de la Similarité de Recouvrement pour comparer deux nodes dans un graph, nous utilisons l'ensemble de voisinage 1-hop pour représenter chaque node cible. L'ensemble de voisinage 1-hop :
- ne contient pas de nodes répétés ;
- exclut les deux nodes cibles.
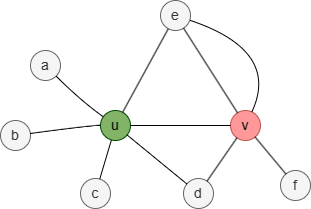
Dans ce graph, l'ensemble de voisinage 1-hop des nodes u et v est :
- Nu = {a,b,c,d,e}
- Nv = {d,e,f}
Par conséquent, la similarité de Jaccard entre les nodes u et v est 2 / 3 = 0,666667.
En pratique, vous pourriez avoir besoin de convertir certaines propriétés de node en schemas de node afin de calculer l'indice de similarité basé sur les voisins communs, tout comme la Similarité de Recouvrement. Par exemple, en ce qui concerne la similarité entre deux applications, des informations comme le numéro de téléphone, l'e-mail, l'IP du dispositif, etc. de l'application pourraient avoir été stockées en tant que properties du schema de node @application; elles doivent être conçues en tant que nodes et incorporées dans le graph afin d'être utilisées pour la comparaison.
Similarité de Recouvrement Pondérée
La Similarité de Recouvrement Pondérée est une extension de la Similarité de Recouvrement classique qui prend en compte les poids associés aux éléments dans les ensembles comparés.
La formule de la Similarité de Recouvrement Pondérée est donnée par :
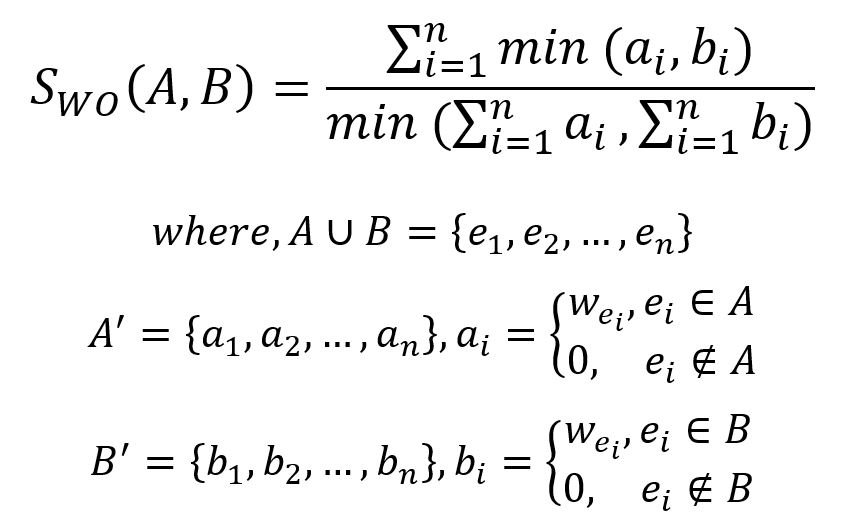
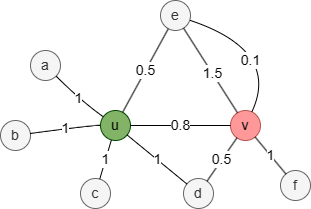
Dans ce graph pondéré, l'union des ensembles de voisinage 1-hop Nu et Nv est {a,b,c,d,e,f}. Assignez à chaque élément de l'ensemble d'union la somme des poids des edges entre le node cible et le node correspondant, ou 0 s'il n'y a pas d'edges entre eux :
| a | b | c | d | e | f | somme | |
|---|---|---|---|---|---|---|---|
| N'u | 1 | 1 | 1 | 1 | 0.5 | 0 | 4.5 |
| N'v | 0 | 0 | 0 | 0.5 | 1.5 + 0.1 =1.6 | 1 | 3.1 |
Par conséquent, la Similarité de Recouvrement Pondérée entre les nodes u et v est (0+0+0+0,5+0,5+0) / 3.1 = 0,322581.
Veuillez vous assurer que la somme des poids des edges entre le node cible et le node voisin est supérieure ou égale à 0.
Considérations
- L'algorithme de Similarité de Recouvrement ignore la direction des edges mais les calcule comme des edges non dirigées.
- L'algorithme de Similarité de Recouvrement ignore toute boucle sur soi-même.
Syntaxe
- Commande :
algo(similarity) - Paramètres :
Nom |
Type |
Spécification |
Défaut |
Optionnel |
Description |
|---|---|---|---|---|---|
| ids / uuids | []_id / []_uuid |
/ | / | Non | ID/UUID du premier groupe de nodes à calculer |
| ids2 / uuids2 | []_id / []_uuid |
/ | / | Oui | ID/UUID du deuxième groupe de nodes à calculer |
| type | string | overlap |
cosine |
Non | Type de similarité ; pour la Similarité de Recouvrement, gardez-le comme overlap |
| edge_weight_property | @<schema>?.<property> |
Type numérique, doit être LTE | / | Oui | La propriété de l'edge à utiliser comme poids de l'edge, où les poids de plusieurs edges entre deux nodes sont additionnés |
| limit | int | ≥-1 | -1 |
Oui | Nombre de résultats à retourner, -1 pour retourner tous les résultats |
| top_limit | int | ≥-1 | -1 |
Oui | Dans le mode de sélection, limite le nombre maximal de résultats retournés pour chaque node spécifié dans ids/uuids, -1 pour retourner tous les résultats avec similarité > 0 ; dans le mode de couplage, ce paramètre est invalide |
L'algorithme a deux modes de calcul :
- Paire :Quand à la fois
ids/uuidsetids2/uuids2sont configurés, coupler chaque node deids/uuidsavec chaque node deids2/uuids2(ignorer le même node) et calculer les similarités par paires. - Sélection :Quand seulement
ids/uuidsest configuré, pour chaque node cible dedans, calculer les similarités par paires entre lui et tous les autres nodes dans le graph. Les résultats retournés incluent tous ou un nombre limité de nodes qui ont une similarité > 0 avec le node cible et sont ordonnés par similarité décroissante.
Exemples
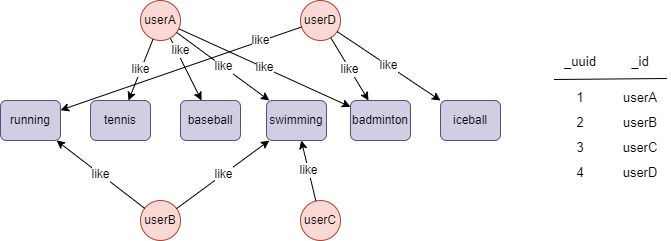
Le graph d'exemple est le suivant :
File Writeback
| Spécification | Contenu |
|---|---|
| nom du fichier | node1,node2,similarity |
algo(similarity).params({
ids: 'userC',
ids2: ['userA', 'userB', 'userD'],
type: 'overlap'
}).write({
file:{
filename: 'sc'
}
})
Résultats : Fichier sc
userC,userA,0.25
userC,userB,0.5
userC,userD,0
algo(similarity).params({
uuids: [1,2,3,4],
type: 'overlap'
}).write({
file:{
filename: 'list'
}
})
Résultats : Fichier list
userA,userC,1
userA,userB,0.5
userA,userD,0.333333
userB,userC,1
userB,userA,0.5
userB,userD,0.5
userC,userA,1
userC,userB,1
userD,userB,0
userD,userA,0.333333
Direct Return
Alias Ordinal |
Type |
Description | Colonnes |
|---|---|---|---|
| 0 | []perNodePair | Paire de nodes et sa similarité | node1, node2, similarity |
algo(similarity).params({
uuids: [1,2],
uuids2: [2,3,4],
type: 'overlap'
}) as overlap
return overlap
Résultats : overlap
| node1 | node2 | similarity |
|---|---|---|
| 1 | 2 | 0.5 |
| 1 | 3 | 1 |
| 1 | 4 | 0.333333333333333 |
| 2 | 3 | 1 |
| 2 | 4 | 0.5 |
algo(similarity).params({
uuids: [1,2],
type: 'overlap',
top_limit: 1
}) as top
return top
Résultats : top
| node1 | node2 | similarity |
|---|---|---|
| 1 | 3 | 1 |
| 2 | 3 | 1 |
Stream Return
Alias Ordinal |
Type |
Description | Colonnes |
|---|---|---|---|
| 0 | []perNodePair | Paire de nodes et sa similarité | node1, node2, similarity |
algo(similarity).params({
uuids: [3],
uuids2: [1,2,4],
type: 'overlap'
}).stream() as overlap
where overlap.similarity > 0
return overlap
Résultats : overlap
| node1 | node2 | similarity |
|---|---|---|
| 3 | 1 | 1 |
| 3 | 2 | 1 |
algo(similarity).params({
uuids: [1],
type: 'overlap',
top_limit: 2
}).stream() as top
return top
Résultats : top
| node1 | node2 | similarity |
|---|---|---|
| 1 | 3 | 1 |
| 1 | 2 | 0.5 |