Cette page démontre plusieurs types de requêtes graphiques sur la façon dont elles sont composées en UQL et à quoi ressemble le résultat de la requête dans Ultipa Manager.
GraphSet utilisé dans cet article :
- Le modèle de graph est comme démontré par le Graph1 dans Préparer le Graph
- Les données du graph peuvent être téléchargées depuis Importation des Données
Pour ceux qui n'ont pas d'environnement serveur Ultipa :
- Cliquez sur le bouton 'Exécuter' en haut de chaque boîte de code pour vérifier le résultat de la requête
- Ou 'Copiez' le code et exécutez-le dans Ultipa Playground contre le graph 'Démarrage Rapide'
Requêtes de Base
Requête de Node
La requête pour les nodes est comparable à la requête de table dans les bases de données relationnelles. Essayez de comprendre le UQL ci-dessous :
find().nodes() as myFirstQuery
return myFirstQuery{*} limit 10
Sa signification littérale est 'trouver des nodes et les nommer comme myFirstQuery, revenir myFirstQuery, en limitez 10', ce qui est assez proche s'il est ajouté avec quelques explications :
- L'instruction de chaîne
find().nodes()initie une requête de node - Alias myFirstQuery défini pour le résultat de cette requête de node est appelé par une instruction ultérieure
return - Le symbole
{*}suivant l'alias de node porte toutes les propriétés du node
L'objectif de l'UQL ci-dessus est 'trouver 10 différents nodes et retourner toutes leurs propriétés'. Exécutez cet UQL dans Ultipa Manager :
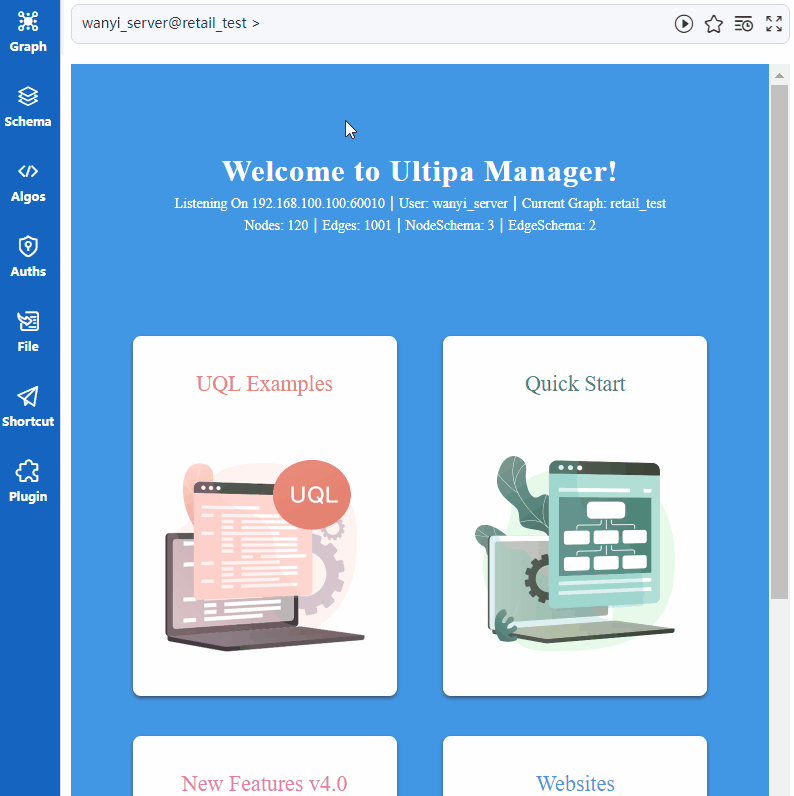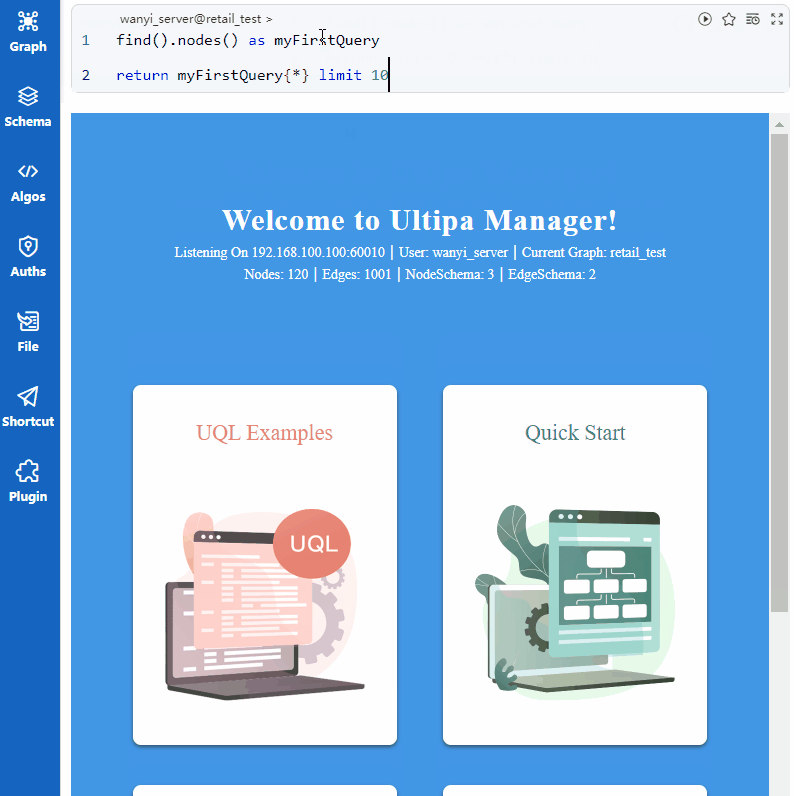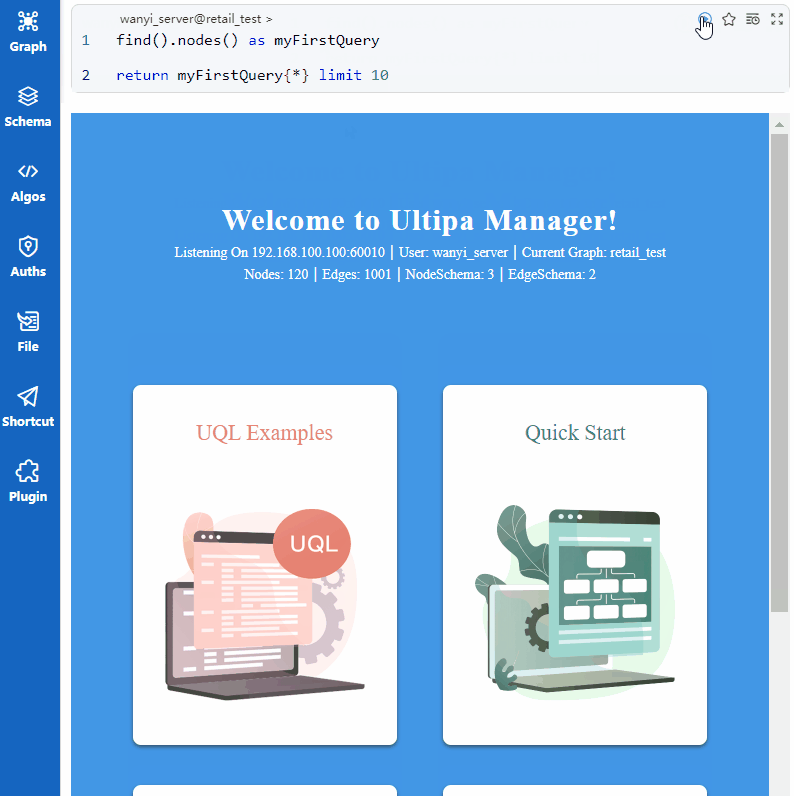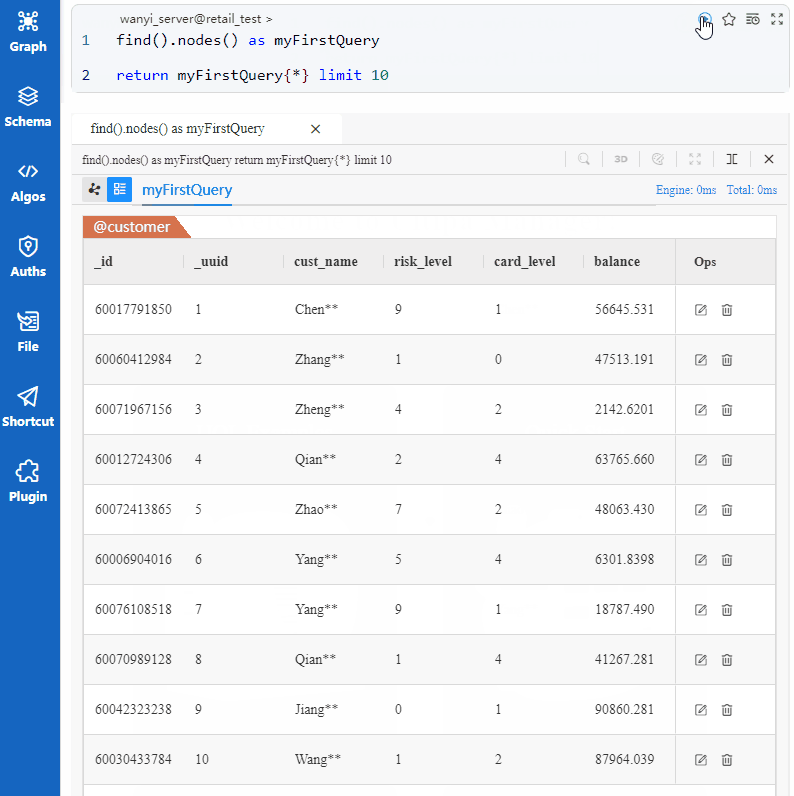
Le fait que myFirstQuery sont tous des nodes du schema
@customerest une coïncidence, ou plus précisément, dépend de la séquence d'insertion des nodes et du comportement de calcul concurrent.
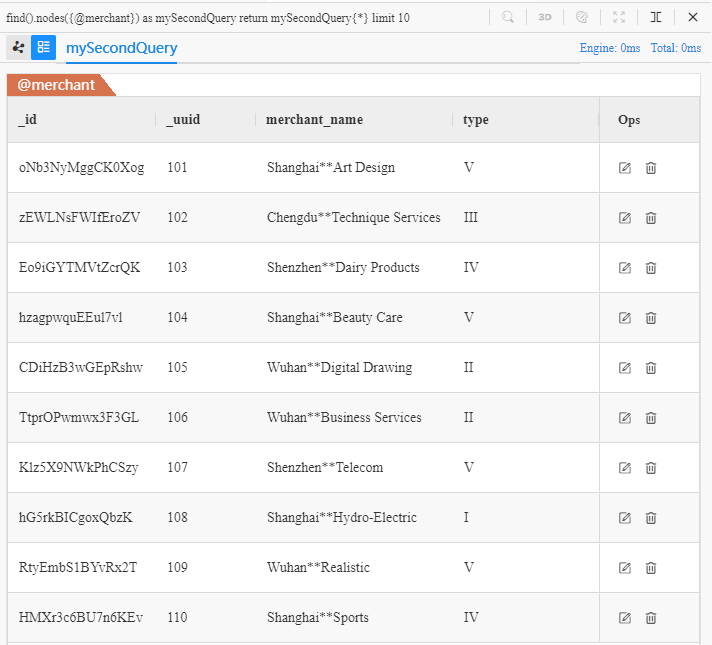
Pour interroger des nodes d'un schema spécifique, comme merchant par exemple, décrivez dans nodes() comme ci-dessous :
find().nodes({@merchant}) as mySecondQuery
return mySecondQuery{*} limit 10
- Les accolades
{}et son contenu détenu parnodes()(ainsi quen()et de nombreux autres paramètres, voir Données Graphiques - Décrire les Nodes) est appelé condition de filtrage
Ci-dessous se trouve le résultat d'exécution de cet UQL :
Requête d'Edge
Dans le modèle de graph actuel, des edges de @transfer existent à partir de nodes de @customer vers des nodes de @merchant :

La requête pour les edges est assez similaire à celle pour les nodes, mais utilise edges() pour contenir la condition de filtrage des edges :
find().edges({_from == "60017791850"}) as payment
return payment{*} limit 10
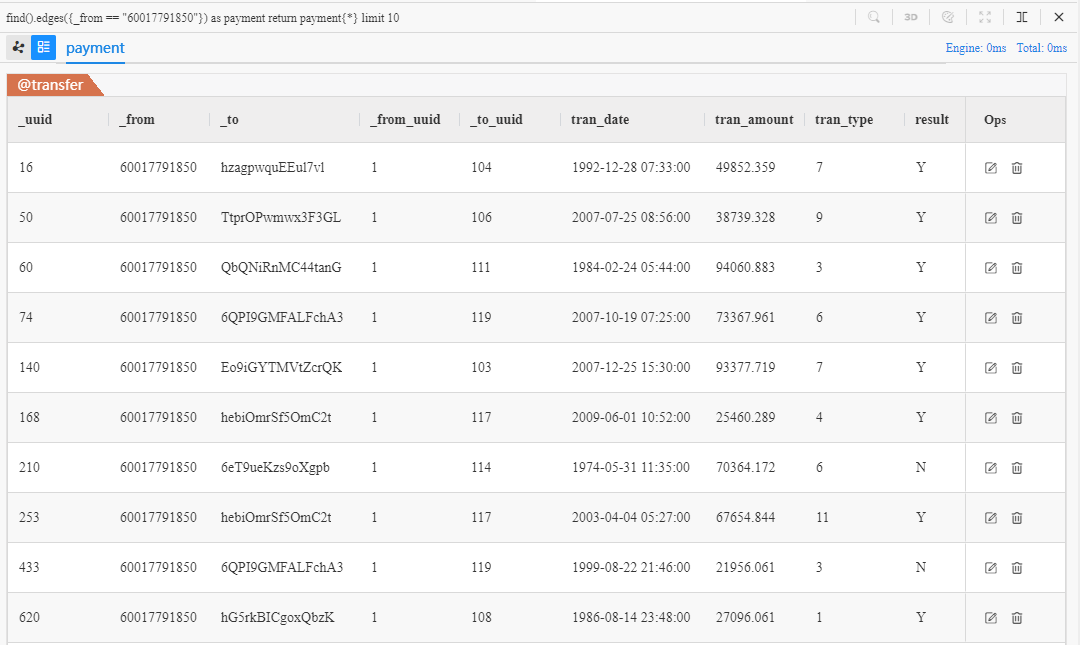
Les payment sont 10 différents edges du client Chen** (ID: 60017791850) vers d'autres nodes, le _to de payment sont les IDs des marchands qui reçoivent ces paiements. Combinez cette requête d'edge avec une requête de node qui appelle les IDs de ces marchands :
find().edges({_from == "60017791850"}) as payment
find().nodes({_id == payment._to}) as merchant
return merchant{*} limit 10
- Le
._idsuivant l'alias de node appelle la propriété_iddu node
Le UQL ci-dessus renvoie toutes les propriétés de ces 10 marchands qui reçoivent des transactions de Chen** (ID: 60017791850) :
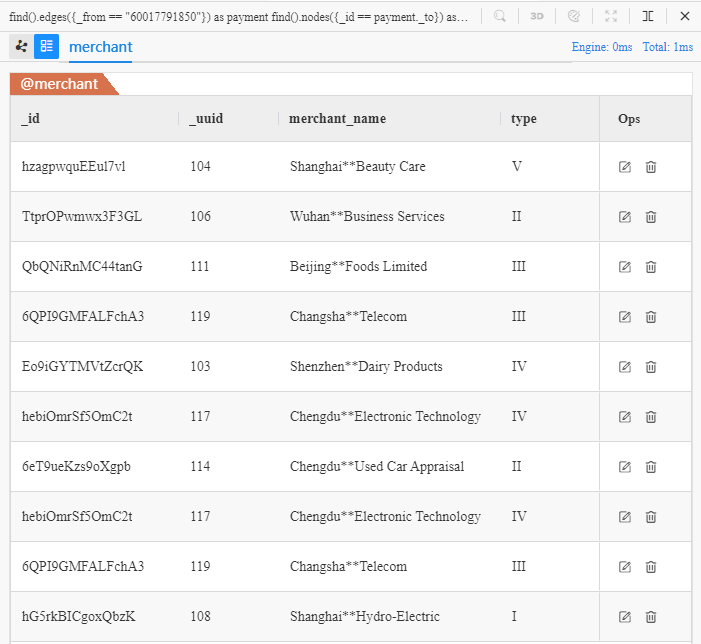
Des valeurs répétées apparaissent dans le résultat, qui sont des marchands avec
_uuid'117' et '119' qui apparaissent chacun deux fois, car chacun reçoit deux transactions de Chen**.
Ceci est un scénario typique de multi-graph, dans lequel plus d'un edge existe entre deux nodes. La vue 2D dans Ultipa Manager peut mieux afficher ce type de scénario.
Spread
spread().src({_id == "60017791850"}).depth(1) as transaction
return transaction{*} limit 10
Sa signification littérale : étendre à partir d'une source dont l'ID est 60017791850, à une profondeur de 1, retourner toutes les propriétés de 10 enregistrements tels.
- La commande
spread()initie une requête pour les edges à partir d'un node centralsrc(), de manière BFS - Le paramètre
depth()définit la profondeur maximale que la recherche BFS parcourt - L'alias transaction représente les chemins d'un pas des edges trouvés, à savoir le 'node de début, edge, node de fin'
- Le symbole
{*}suivant l'alias de chemin porte toutes les propriétés des nodes et edges du chemin
L'objectif de l'UQL ci-dessus est 'trouver 10 différents edges du client Chen** vers les marchands et retourner toutes les propriétés de Chen**, edges et marchands' :
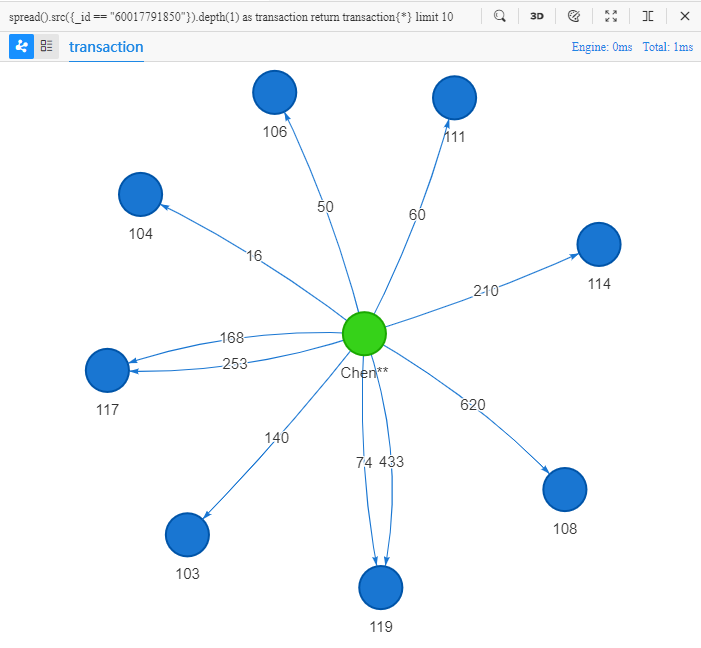
Le résultat de la requête des chemins est automatiquement visualisé en vue 2D dans Ultipa Manager, où les multiples transactions entre Chen** et les deux marchands '117' et '119' sont intuitivement observées.
Pour obtenir un nombre exact de marchands distincts de fin de node via la requête spread(), une opération de déduplication peut être impliquée avant de retourner le résultat final. Une autre option est d'utiliser une différente commande de requête qui, par conception, recherche de manière BFS mais renvoie des nodes.
K-Hop
khop().src({_id == "60017791850"}).depth(1) as merchant
return merchant{*} limit 10
Sa signification littérale : sauter K fois à partir d'une source dont l'ID est 60017791850, à une profondeur de 1, retourner toutes les propriétés de 10 enregistrements tels.
- La commande
khop()initie une requête pour les nodes depuis un node centralsrc(), de manière BFS - L'alias merchant représente les nodes
L'objectif de l'UQL ci-dessus est 'trouver 10 différents marchands qui reçoivent des paiements de Chen** et retourner toutes les propriétés de ces marchands:
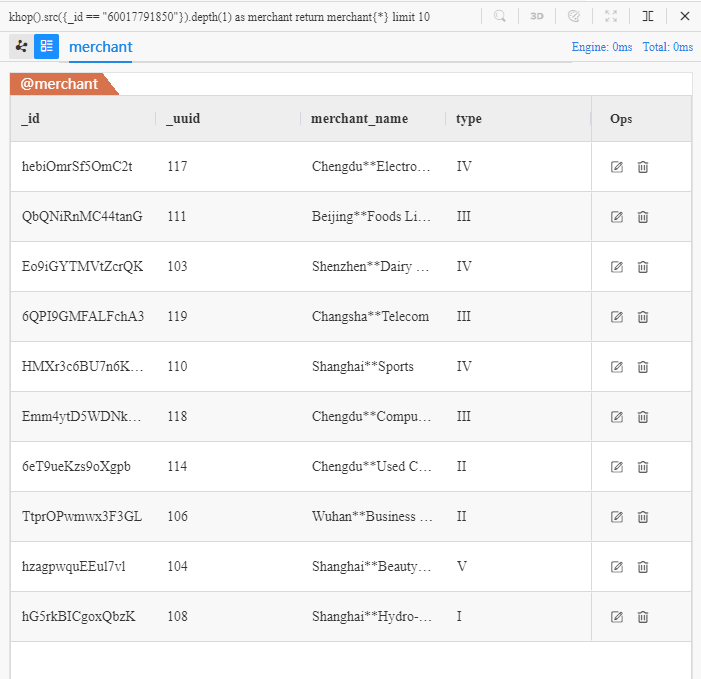
Deux marchands supplémentaires '110' et '118' sont trouvés par
khop(), en plus de ces 8 marchands trouvés parspread().
Penser en "Template"
La requête modèle est un type avancé de requête graph en décrivant avec précision chaque node et edge dans un chemin. Elle utilise les paramètres n(), e() et nf() mentionnés dans Données Graphiques.
Chaînes
n({_id == "60017791850"}).e().n() as transaction
return transaction{*} limit 10
Sa signification littérale : trouver des chemins d'un pas à partir du node dont l'ID est 60017791850 et renvoyer toutes les informations de 10 tels chemins :
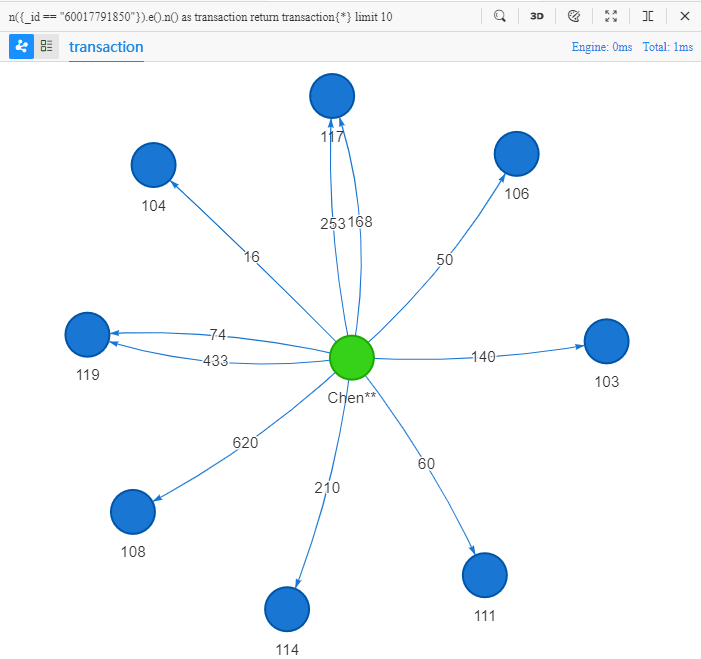
Cela atteint le même résultat que la requête précédente utilisant
spread(), car les deux requêtes recherchent des chemins d'un pas à partir du client Chen**.
Considérons maintenant un chemin qui commence à partir de Chen** et atteint un marchand via 3 edges, tous les edges doivent avoir un montant de transaction supérieur à 70000 :

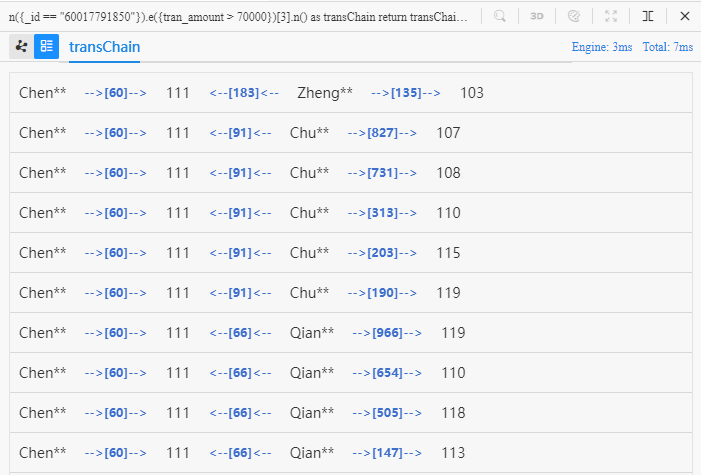
n({_id == "60017791850"}).e({tran_amount > 70000})[3].n() as transChain
return transChain{*} limit 10
- Le symbole
[3]suivante()indique le nombre d'edges dans le chemin (même objectif quedepth())
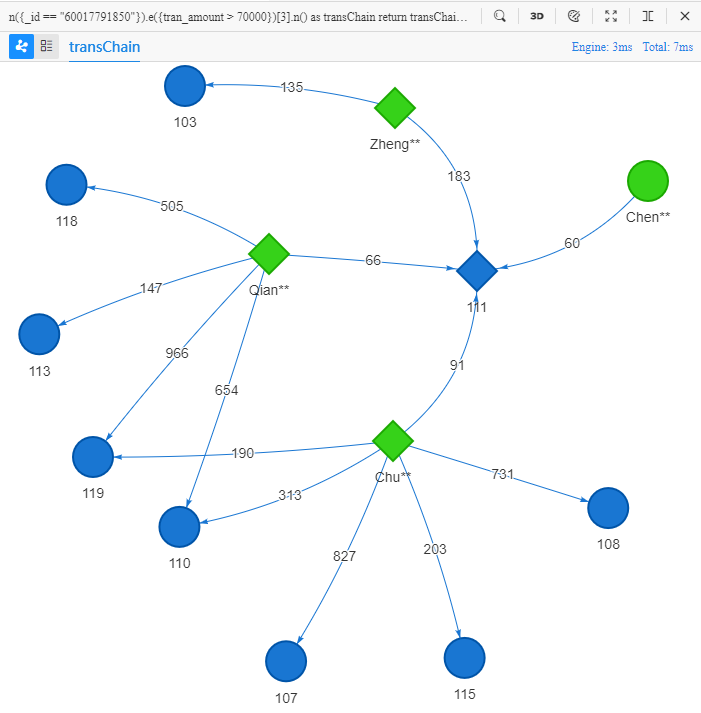
Ces 10 chemins divergent à partir du 2ème node dans chacun le leur, le marchand '111', en 3 branches, et divergent plus loin de ces trois clients Zheng**, Qian** et Chu** en 10 branches, qui atteignent finalement 8 différents marchands.
Si les comportements d'achat de Chen**, Zheng**, Qian** et Chu**, ceux qui achètent tous des produits du marchand '111', sont considérés comme similaires, alors il est raisonnable de recommander certains de ces 8 marchands au node terminal au client Chen**, ce qui est un scénario typique de recommandation de produits et de marchands.
La vue 2D d'Ultipa Manager ne re-rend pas le même node ou edge pour un chemin différent. Quand tous les 10 chemins commencent par Chen**, passent l'edge '60' et atteignent le marchand '111', ces 3 métadonnées sont partagées dans la vue 2D. Une vue de liste montrera clairement toutes les métadonnées de chaque chemin :
Cercles
Les edges dans un chemin ne se répètent jamais, mais les nodes le font parfois, ce qui induit des cercles dans le chemin.
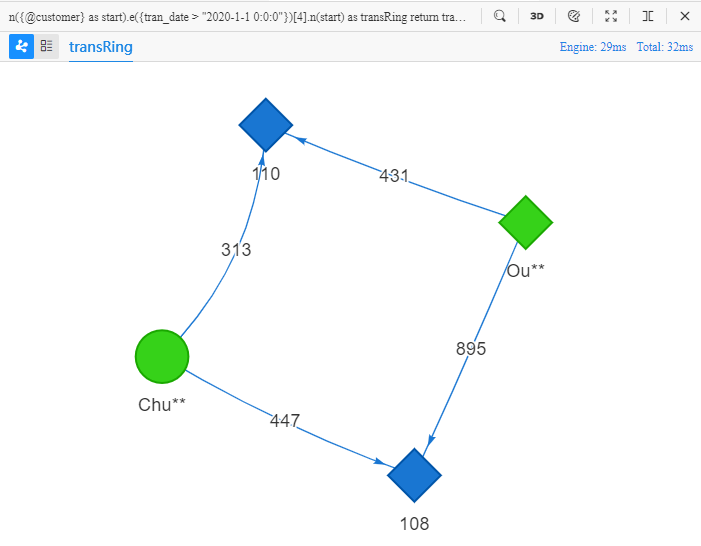
n({@customer} as start).e({tran_date > "2020-1-1 0:0:0"})[4].n(start) as transRing
return transRing{*} limit 10
- Le dernier
n()appelle l'alias start défini dans le premiern(), donc le node initial et le node terminal du chemin deviennent le même node
L'objectif de l'UQL ci-dessus est 'trouver 10 chemins à quatre étapes commençant par un node @customer et revenant à ce node à la fin, où chaque transaction a lieu après 2020-1-1 0:0:0, retourner toutes les propriétés des nodes et edges dans ces chemins' :
La vue liste du résultat de la requête :
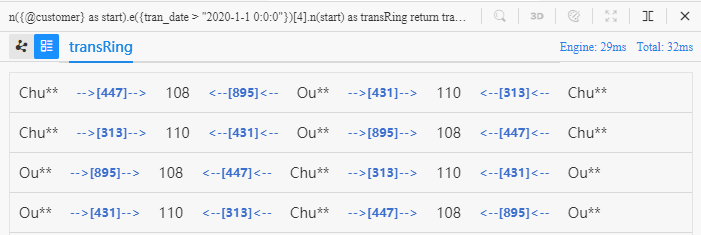
Dans ces cercles à quatre étapes, les clients Chu** et Ou** achètent des produits des marchands '110' et '108', cela fournit des preuves de certaines similitudes entre ces deux clients.
Chemins les Plus Courts
n({_id == "60017791850"}).e()[:5].n(115) as transRange
return transRange{*} limit 1
- La valeur
:5dans la parenthèse peut également être écrite1:5, ce qui spécifie une plage flexible de longueur de chemin au lieu d'un nombre fixe - Le nombre '115' dans le dernier
n()est un format abrégé de{_uuid == 115}
L'objectif de l'UQL ci-dessus est 'trouver un chemin de Chen** au node dont l'UUID est 115, avec une longueur ne dépassant pas 5, retourner toutes les propriétés des nodes et des edges du chemin' :

Par hasard, le chemin trouvé a exactement 5 edges.
Une légère révision apportée à la longueur du chemin pourrait complètement changer la cible de requête de l'UQL :
n({_id == "60017791850"}).e()[*:5].n(115) as transShortest
return transShortest{*} limit 1
- En ajoutant une étoile
*, la valeur*:5transforme le modèle en un chemin le plus court avec une longueur ne dépassant pas 5
L'objectif de l'UQL ci-dessus est 'trouver un chemin le plus court de Chen** au node dont l'UUID est 115, avec une longueur ne dépassant pas 5, retourner toutes les propriétés des nodes et des edges du chemin' :
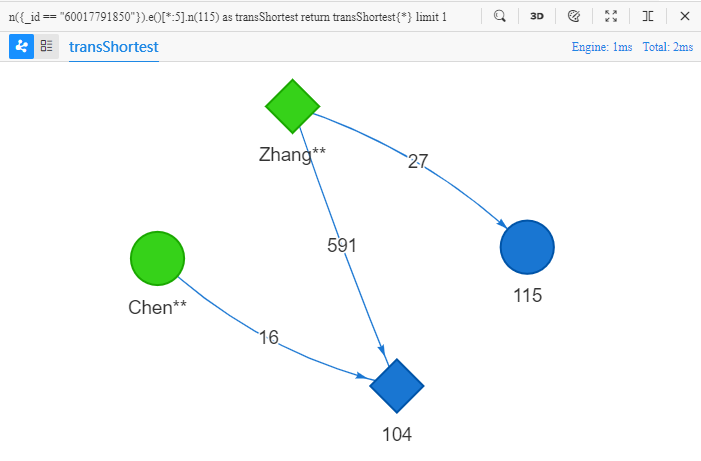
Le chemin le plus court suggère la connexion la plus directe entre deux nodes. En général, plus le chemin est court, plus sa connectivité est grande, et plus il est intéressant à analyser. Pour cette raison, les entités du monde réel cachent parfois intentionnellement leurs connexions à une distance excessivement longue (20~30 étapes) d'une autre entité. Pour découvrir ces entités suspectes, une DBMS à haute performance avec capacité HTAP, ultra-profonde de traversée de graph, et une réactivité exceptionnelle est nécessaire.
Calculs Communs
L'UQL peut effectuer une variété de calculs après avoir trouvé des nodes, edges et chemins, via des fonctions et des clauses. Cette section présente certains des plus fréquemment utilisés, veuillez vous référer au manuel UQL pour plus de détails.
Dédupliquer
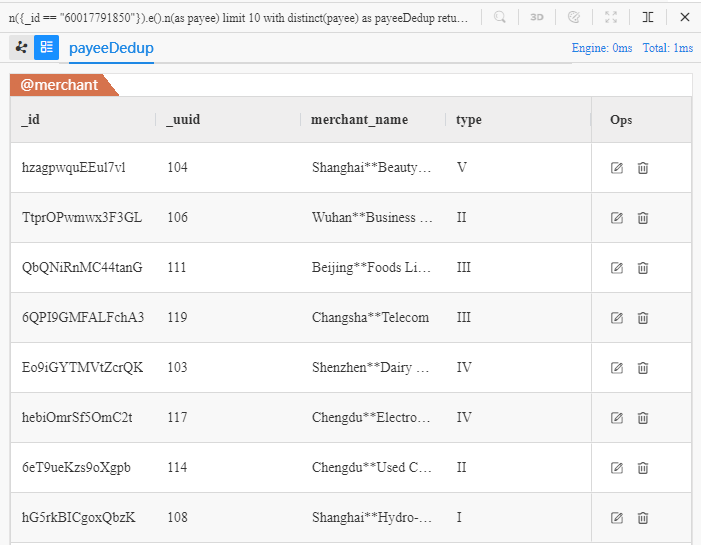
Revisitez le premier exemple démontré dans la section Chaînes pour trouver ces 8 marchands distincts sur 10 au total :
n({_id == "60017791850"}).e().n(as payee) limit 10
with distinct payee as payeeDedup
return payeeDedup{*}
- L'opérateur
distinctdéduplique payee basé sur l'ID du node - L'opération de déduplication est composée dans
with - L'instruction
limit 10est exécutée avantwith, toutes les instructions UQL sont exécutées dans l'ordre où elles sont composées
Compter
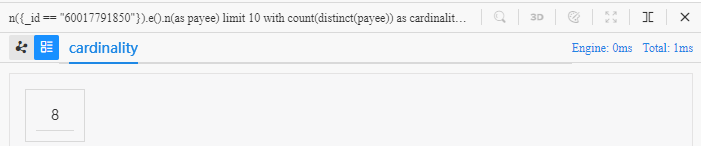
Revisitez l'exemple précédent pour calculer le nombre de marchands distincts :
n({_id == "60017791850"}).e().n(as payee) limit 10
with count(distinct payee) as cardinality
return cardinality
- La fonction
count()calcule le nombre dedistinct payee,count()etdistinctsont parfois utilisés conjointement
Ordonner par
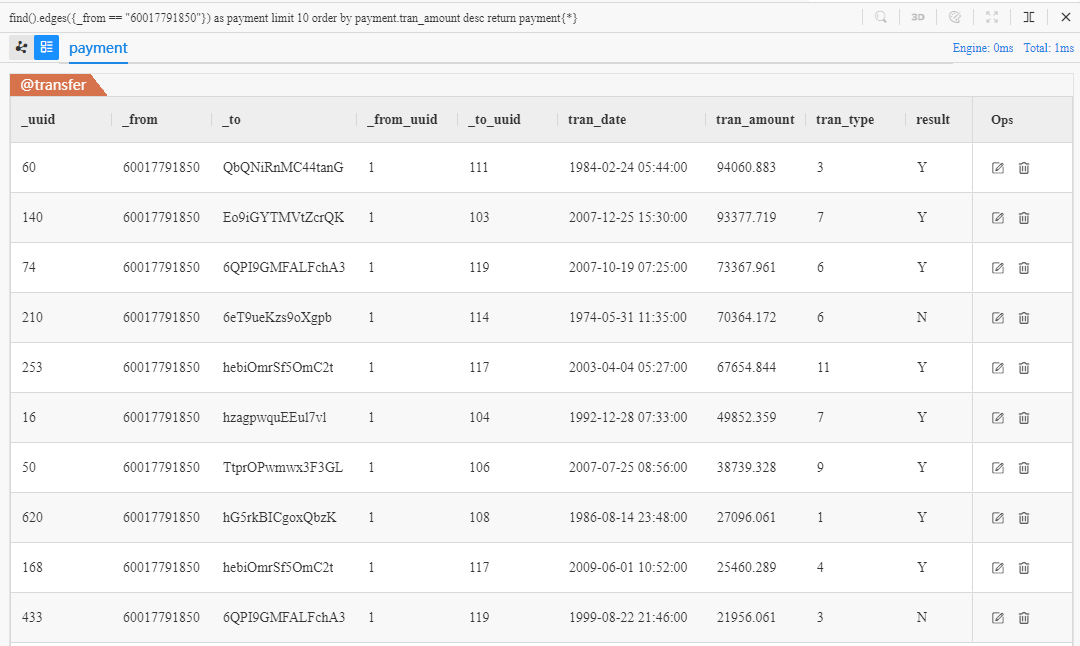
Revisitez le premier exemple démontré dans la section Requête d'Edge pour retourner ces 10 edges en ordre décroissant de leur montant de transaction :
find().edges({_from == "60017791850"}) as payment limit 10
order by payment.tran_amount desc
return payment{*}
- Le mot-clé de clause
order bytrie payment par sa propriété tran_amount - Le mot-clé
descà la fin de la clauseorder bysignifie trier par ordre décroissant
Groupe par
Revisitez le deuxième exemple démontré dans la section Chaînes pour regrouper ces chemins de 3 étapes par leur 3ème node, et compter le nombre de chemins dans chaque groupe :
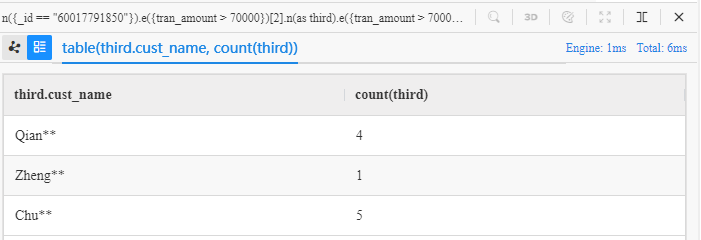
n({_id == "60017791850"}).e({tran_amount > 70000})[2].n(as third).e({tran_amount > 70000}).n() limit 10
group by third
return table(third.cust_name, count(third))
- Pour exprimer le 3ème node dans le chemin, le modèle original
n().e()[3].n()est transformé enn().e()[2].n().e().n() - Le mot-clé de clause
group bydivise third basé sur l'ID du node - La fonction
count()est exécutée contre third dans chaque groupe - La fonction
table()fusionnethird.cust_nameetcount(third)dans une table pour les rendre plus pratiques à vérifier