Schema Overview
HDC
Overview
The Schema Overview algorithm summarizes the structure of a graph by presenting statistics for source node schemas (labels), edge schemas, end node schemas, and the corresponding edge counts.
Example Graph
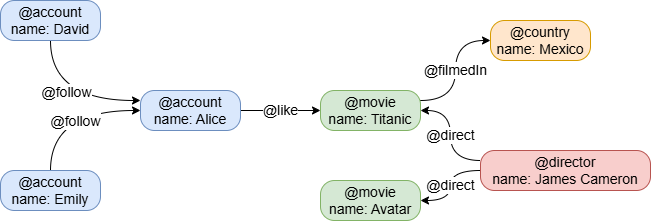
Run the following statements on an empty graph to define its structure and insert data:
ALTER GRAPH CURRENT_GRAPH ADD NODE { account (), movie (), country (), director () }; ALTER GRAPH CURRENT_GRAPH ADD EDGE { follow ()-[]->(), like ()-[]->(), filmedIn ()-[]->(), direct ()-[]->() }; INSERT (David:account {_id: "David"}), (Emily:account {_id: "Emily"}), (Alice:account {_id: "Alice"}), (Titanic:movie {_id: "Titanic"}), (Avatar:movie {_id: "Avatar"}), (Mexico:country {_id: "Mexico"}), (JC:director {_id: "James Cameron"}), (David)-[:follow]->(Alice), (Emily)-[:follow]->(Alice), (Alice)-[:like]->(Titanic), (Titanic)-[:filmedIn]->(Mexico), (JC)-[:direct]->(Titanic), (JC)-[:direct]->(Avatar);
Creating HDC Graph
To load the entire graph to the HDC server hdc-server-1 as my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS { nodes: {"*": ["*"]}, edges: {"*": ["*"]}, direction: "undirected", load_id: true, update: "static" }
Parameters
Algorithm name: schema_overview
Name | Type | Spec | Default | Optional | Description |
|---|---|---|---|---|---|
order | String | asc, desc | / | Yes | Sorts the results by count. |
Full Return
CALL algo.schema_overview.run("my_hdc_graph", {}) YIELD r RETURN r
Result:
node schema(src) | edge schema | node schema(dest) | count |
|---|---|---|---|
| account | follow | account | 2 |
| account | like | movie | 1 |
| movie | filmedIn | country | 1 |
| director | direct | movie | 2 |
Stream Return
CALL algo.schema_overview.stream("my_hdc_graph", {}) YIELD r FILTER r.`node schema(src)` = "account" RETURN r
Result:
node schema(src) | edge schema | node schema(dest) | count |
|---|---|---|---|
| account | follow | account | 2 |
| account | like | movie | 1 |