Resource Allocation
HDC
Overview
The Resource Allocation algorithm assumes that nodes distribute resources to each other through shared neighbors, who act as transmitters. In its basic form, each transmitter is considered to possess a single unit of resource, which is evenly distributed among its neighbors. As a result, the similarity between two nodes is measured by the amount of resource one node is able to transmit to the other through these shared neighbors. This concept was introduced by Tao Zhou, Linyuan Lü, and Yi-Cheng Zhang in 2009:
- T. Zhou, L. Lü, Y. Zhang, Predicting Missing Links via Local Information (2009)
It is computed using the following formula:
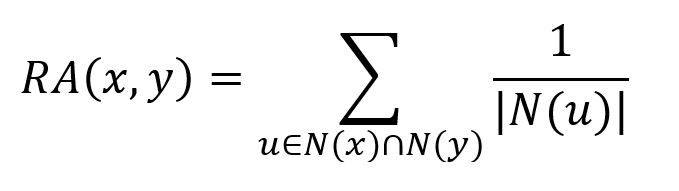
where N(u) is the set of nodes adjacent to u. For each common neighbor u of the two nodes, the Resource Allocation first calculates the reciprocal of its degree |N(u)|, and then sums these values across all common neighbors.
When calculating the degree for nodes in the graphset:
- Edges connecting the same two nodes are counted only once;
- Self-loops are excluded from the calculation.
Higher Resource Allocation scores indicate greater similarity between nodes, while a score of 0 indicates no similarity.
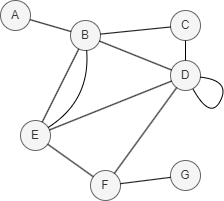
In this example, N(D) ∩ N(E) = {B, F}, RA(D,E) = + = + = 0.5833.
Considerations
- The Resource Allocation algorithm treats all edges as undirected, ignoring their original direction.
Example Graph
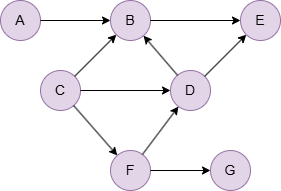
Run the following statements on an empty graph to define its structure and insert data:
INSERT (A:default {_id: "A"}), (B:default {_id: "B"}), (C:default {_id: "C"}), (D:default {_id: "D"}), (E:default {_id: "E"}), (F:default {_id: "F"}), (G:default {_id: "G"}), (A)-[:default]->(B), (B)-[:default]->(E), (C)-[:default]->(B), (C)-[:default]->(D), (C)-[:default]->(F), (D)-[:default]->(B), (D)-[:default]->(E), (F)-[:default]->(D), (F)-[:default]->(G);
Creating HDC Graph
To load the entire graph to the HDC server hdc-server-1 as my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS { nodes: {"*": ["*"]}, edges: {"*": ["*"]}, direction: "undirected", load_id: true, update: "static" }
Parameters
Algorithm name: topological_link_prediction
Name | Type | Spec | Default | Optional | Description |
|---|---|---|---|---|---|
ids | []_id | / | / | No | Specifies the first group of nodes for computation by their _id. If unset, all nodes in the graph are used as the first group of nodes. |
uuids | []_uuid | / | / | No | Specifies the first group of nodes for computation by their _uuid. If unset, all nodes in the graph are used as the first group of nodes. |
ids2 | []_id | / | / | No | Specifies the second group of nodes for computation by their _id. If unset, all nodes in the graph are used as the second group of nodes. |
uuids2 | []_uuid | / | / | No | Specifies the second group of nodes for computation by their _uuid. If unset, all nodes in the graph are used as the second group of nodes. |
type | String | Resource_Allocation | Adamic_Adar | No | Specifies the similarity type; for Resource Allocation, keep it as Resource_Allocation. |
return_id_uuid | String | uuid, id, both | uuid | Yes | Includes _uuid, _id, or both to represent nodes in the results. |
limit | Integer | ≥-1 | -1 | Yes | Limits the number of results returned. Set to -1 to include all results. |
File Writeback
CALL algo.topological_link_prediction.write("my_hdc_graph", { ids: ["C"], ids2: ["A","E","G"], type: "Resource_Allocation", return_id_uuid: "id" }, { file: { filename: "ra" } })
Result:
File: ra_id1,_id2,result C,A,0.25 C,E,0.5 C,G,0.333333
Full Return
CALL algo.topological_link_prediction.run("my_hdc_graph", { ids: ["C"], ids2: ["A","C","E","G"], type: "Resource_Allocation", return_id_uuid: "id" }) YIELD ra RETURN ra
Result:
| _id1 | _id2 | result |
|---|---|---|
| C | A | 0.25 |
| C | E | 0.5 |
| C | G | 0.333333 |
Stream Return
CALL algo.topological_link_prediction.stream("my_hdc_graph", { ids: ["C"], ids2: ["A", "B", "D", "E", "F", "G"], type: "Resource_Allocation", return_id_uuid: "id" }) YIELD ra FILTER ra.result >= 0.3 RETURN ra
Result:
| _id1 | _id2 | result |
|---|---|---|
| C | D | 0.583333 |
| C | E | 0.5 |
| C | G | 0.333333 |