UNION ALL
UNION ALL splices return values that have same alias from two RETURNs head-to-tail and unite the data of each return value in the same row as an integrated row. It has an operational efficiency higher than that of UNION since no deduplication is executed against the united rows.
Syntax:
... RETURN <expression1_A> as <alias_A>, <expression1_B> as <alias_B>, ...
UNION ALL
... RETURN <expression2_A> as <alias_A>, <expression2_B> as <alias_B>, ...
Input:
- <expression1>: Return values of the 1st RETURN
- <expression2>: Return values of the 2nd RETURN, should have the same number of return values as the 1st RETURN and the same data structure of each same alias
- <alias>: The alias of return value (different order allowed)
For instance, splice heterologous return values a and b:
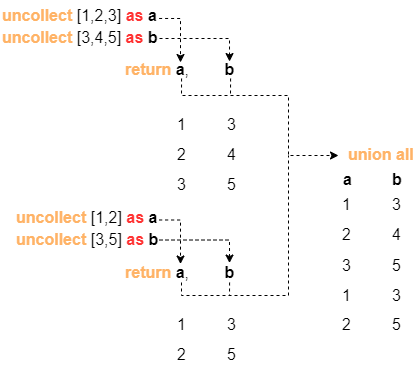
UQLuncollect [1,2,3]) as a uncollect [3,4,5]) as b return a, b union all uncollect [1,2]) as a uncollect [3,5]) as b return a, b
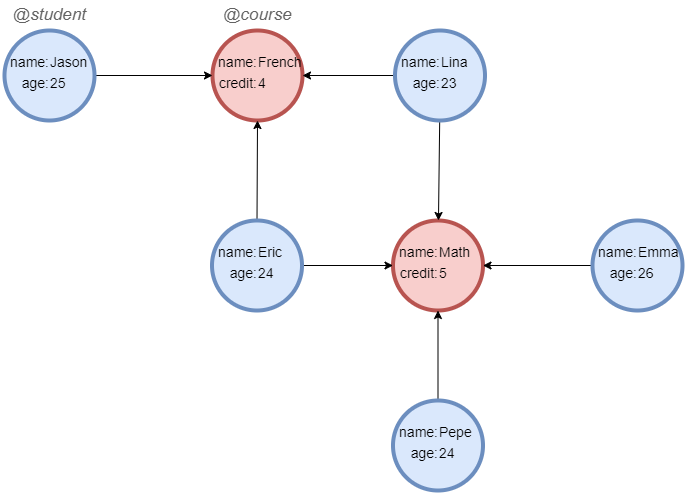
Sample graph: (to be used for the following examples)
Common Usage
Example: Find students no elder than 24-year-old that select French, also find students no younger than 24-year-old that select Math, return these students
UQLn({@course.name == "French"}).e().n({@student.age <= 24} as n) return n.name union all n({@course.name == "Math"}).e().n({@student.age >= 24} as n) return n.name
ResultLina Eric Pepe Eric Emma