listUnion()
Function listUnion() merges and deduplicates the elements of two lists, and returns them as a new list, namely, returns the union of these two lists (repeated elements are NOT allowed in the union).
Arguments:
- 1st list <list>
- 2nd list <list>
Returns:
- Union <list>
Common Usage
Exalmple: Direct calculate
UQLuncollect [[1,2,2],[2,4,5]] as a uncollect [[2,4,7],[4,5,7]] as b return table(toString(a), toString(b), toString(listUnion(a, b)))
Result| toString(a) | toString(b) | toString(listUnion(a, b)) | |-------------|-------------|---------------------------| | [1,2,2] | [2,4,7] | [1,2,4,7] | | [2,4,5] | [4,5,7] | [2,4,5,7] |
Exalmple: Multiply and calculate
UQLuncollect [[1,2,2],[2,4,5]] as a uncollect [[2,4,7],[4,5,7]] as b with listUnion(a, b) as c return table(toString(a), toString(b), toString(c))
Result| toString(a) | toString(b) | toString(c) | |-------------|-------------|-------------| | [1,2,2] | [2,4,7] | [1,2,4,7] | | [1,2,2] | [4,5,7] | [1,2,4,5,7] | | [2,4,5] | [2,4,7] | [2,4,5,7] | | [2,4,5] | [4,5,7] | [2,4,5,7] |
Sample graph: (to be used for the following examples)
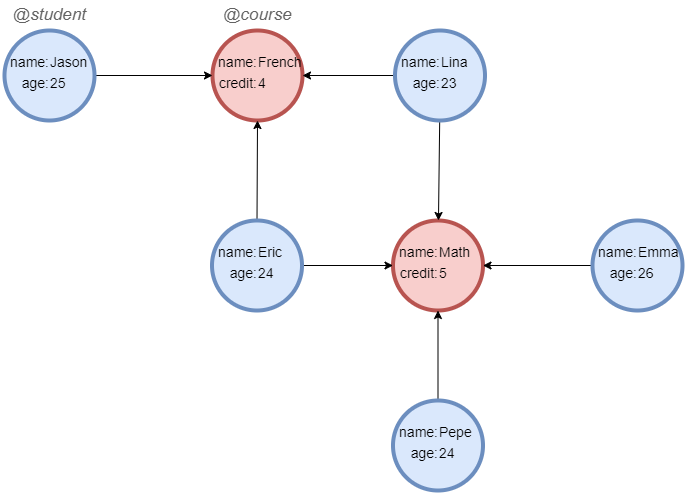
Example: Find the students that select French or Math
UQLkhop().src({name == "French"}).depth(1) as n1 with collect(n1) as l1 khop().src({name == "Math"}).depth(1) as n2 with collect(n2) as l2 return listUnion(l1, l2)
Result[ {"id":"","uuid":"1","schema":"student","values":{}}, {"id":"","uuid":"2","schema":"student","values":{}}, {"id":"","uuid":"3","schema":"student","values":{}}, {"id":"","uuid":"4","schema":"student","values":{}}, {"id":"","uuid":"5","schema":"student","values":{}} ]