GROUP BY
GROUP BY divides the rows in the alias into groups, for each group keeps one row and discard the rest of rows; it is always used in combination with aggregation and ORDER BY operations.
Syntax: GROUP BY <expression> as <alias>, <expression> as <alias>, ...
Input:
- <expression>: Grouping criterion; multiple criteria must be homologous and are operated from left to right
- <alias>: Alias of grouping criterion, optional
For instance, apply mult-level grouping to path, first by the shape of initial-nodes n1, then by the colour of terminal-nodes n2 in each group; count the number of paths in each group and return both path and the count.

UQLn(as n1).re().n(as n2) as path group by n1.shape, n2.color return path, count(path)
Sample graph: (to be used for the following examples)
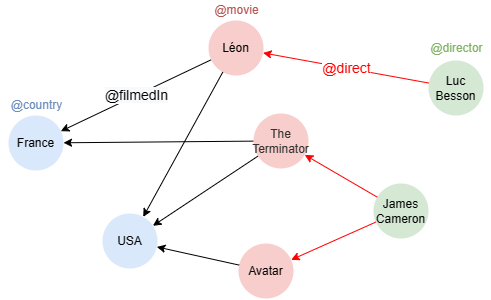
Grouping and Aggregating
Example: Find 2-step paths @country-@movie-@director, group by director and count the number of paths in each group
UQLn({@country}).e().n({@movie}).e().n({@director} as n) group by n return table(n.name, count(n))
Result| n.name | count(n) | |---------------|----------| | Luc Besson | 2 | | James Cameron | 3 |
Analysis: An aggregation is executed within each group only if the aggregation funciton is composed right after the GROUP BY clause.
Multi-level Grouping
Example: Find 2-step paths @country-@movie-@director, group by country and then by director, count the number of paths in each group
UQLn({@country} as a).e().n({@movie}).e().n({@director} as b) group by a, b return table(a.name, b.name, count(a))
Result| a.name | b.name | count(a) | |--------|---------------|----------| | France | Luc Besson | 1 | | France | James Cameron | 1 | | USA | Luc Besson | 1 | | USA | James Cameron | 2 |