CALL
CALL executes operations against the query result of each subquery, NOT all the result of a query command. It wraps query commands and the operations in curly braces {}, passes in the alias that triggers each subquery using a WITH clause and passes out the result of each subquery using a RETURN clause.
Syntax:
CALL {
WITH <alias_In>, <alias_In>, ...
...
RETURN <expression> as <alias_Out>, <expression> as <alias_Out>, ...
}
Input:
- <alias_In>: The alias that triggers the subquery
- <expression>: The return value of the subquery
- <alias_Out>: The alias of return value of the subquery, optional when <expression> is alias
For instance, skip the first row of each subquery result p:

UQLfind().nodes([1, 5]) as nodes call { with nodes n(nodes).e()[:2].n() as p skip 1 return p as path } return path
Sample graph: (to be used for the following examples)
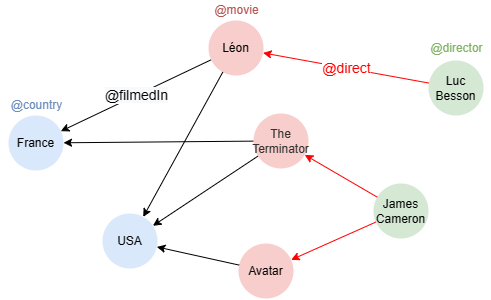
Common Usage
Example: Not using GROUP BY, find how many movies are filmed in each country
UQLfind().nodes({@country}) as nodes call { with nodes n(nodes).e().n({@movie} as n) return count(n) as number } return table(nodes.name, number)
Result| nodes.name | number | |------------|--------| | France | 2 | | USA | 3 |